一:前言
requests虽然功能强大,但遇上JavaScript动态渲染过的html页面还是有一定的局限,这是后如果你机器强大,而且爬取数据量不是太大的话,你或许可以考虑一下selenium+phantomjs来针对那些需要登录,并且是JavaScript动态渲染的网页。
selenium
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。
可以从 PyPI 网站下载 Selenium库https://pypi.python.org/simple/selenium ,也可以用 第三方管理器 pip用命令安装:pip install selenium
Selenium 官方参考文档:http://selenium-python.readthedocs.io/index.html
phantomjs
PhantomJS 是一个基于Webkit的“无界面”(headless)浏览器,它会把网站加载到内存并执行页面上的 JavaScript,因为不会展示图形界面,所以运行起来比完整的浏览器要高效。
如果我们把 Selenium 和 PhantomJS 结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理 JavaScrip、Cookie、headers,以及任何我们真实用户需要做的事情。
PhantomJS 只能从它的官方网站http://phantomjs.org/download.html) 下载。 因为 PhantomJS 是一个功能完善(虽然无界面)的浏览器而非一个 Python 库,所以它不需要像 Python 的其他库一样安装,但我们可以通过Selenium调用PhantomJS来直接使用。
PhantomJS 官方参考文档:http://phantomjs.org/documentation
三:第一个程序
# -*- coding:utf-8 -*-
from selenium import webdriver
import os
#创建浏览器对象
driver = webdriver.PhantomJS()
driver.get("https://www.baidu.com")
#保存网页快照
driver.save_screenshot("baidu.png")
#退出浏览器
driver.quit()程序运行的结果就是将百度的首页保存为图片

注意
使用这句代码webdriver.PhantomJS()的前提是你的phantomjs一定是要配置了环境变量,(至于如何配置环境变量,如果有不清楚的可以参考这一篇文章http://blog.csdn.net/katyusha1/article/details/78359439)
如果老铁们使用的是anaconda集成包的话,那么可以将phantomjs放在anaconda安装目录下的Scripts目录下,这样anaconda会自动加载。
4:模拟登录
如果想要模拟页面登录,则需要使用webdriver提供的各种方法来寻找网页中的各种元素
假设有如下标签
<input type="text" name="user-name" id="passwd-id" />获取id标签值
element = driver.find_element_by_id(“passwd-id”)
获取name标签值
element = driver.find_element_by_name(“user-name”)
获取标签名值
element = driver.find_elements_by_tag_name(“input”)
也可以通过XPath来匹配
element = driver.find_element_by_xpath(“//input[@id=’passwd-id’]”)
关于元素的选取,有如下的API 单个元素选取
find_element_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
讲完上面的东西基本上就可以做一个简答的网站模拟登陆了,那么接下来我们就以人人网为例吧。
为什么选择人人?
因为它简单!
为什么简单?
因为它没有验证码!

首先看一看人人网的登录页面
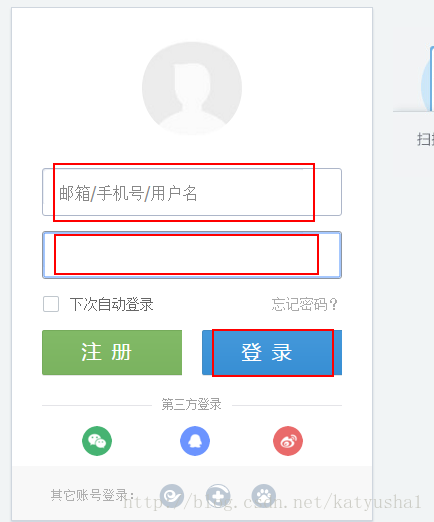
用谷歌浏览器的开发者工具检查一下用户名输入框,密码输入框,以及登录按钮元素

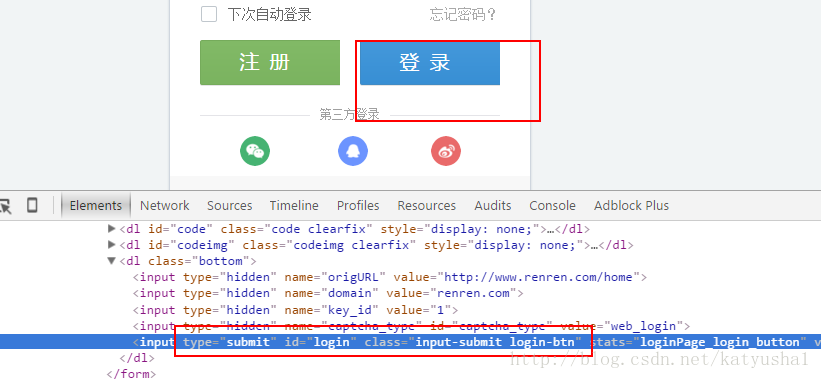
可以发现用户名和密码输入框的标签属性,这正是我们模拟登陆需要用上的东西
好了废话不多说,直接上代码
# -*- coding:utf-8 -*-
from selenium import webdriver
# 要想调用键盘按键操作需要引入keys包
from selenium.webdriver.common.keys import Keys
import time
#创建浏览器对象
driver = webdriver.PhantomJS()
#豆瓣登录页面
driver.get("http://www.renren.com/SysHome.do")
#输入账号
driver.find_element_by_id("email").send_keys("yourusername")
#输入密码
driver.find_element_by_name("password").send_keys("yourpasswd")
#模拟点击登录
driver.find_element_by_id("login").click()
#设置休息时间等待页面加载
time.sleep(10)
#保存网页快照
driver.save_screenshot("renren.png")
#退出浏览器
driver.quit()执行结果
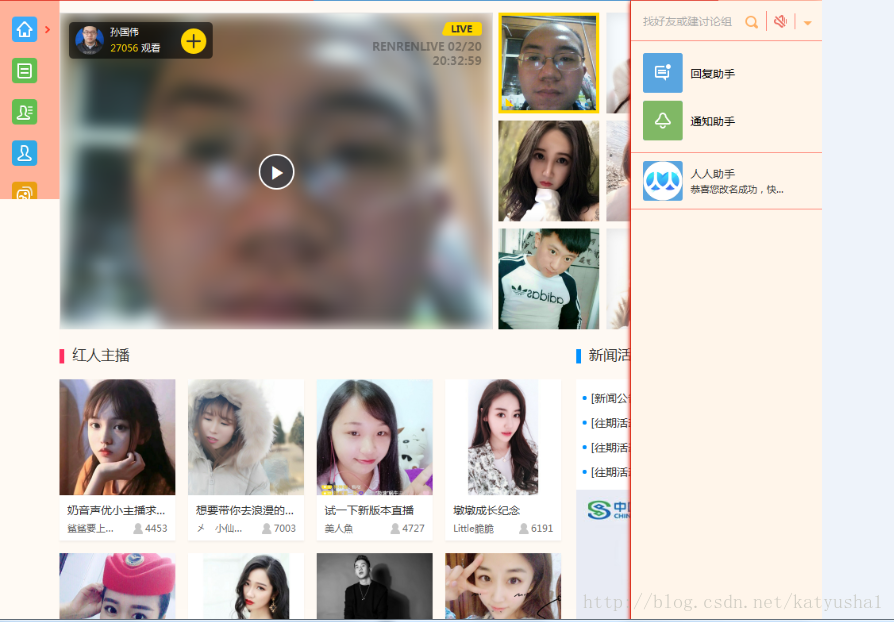
哎。。。。。。
人人再也不是以前那个人人了
