最近在做谷歌text normlization的时候,俩队友用到了这个算法,搞得我一脸懵逼。整体来说,还是一种字符串模糊匹配算法吧,多用来衡量字符串之间的相似度。字符串的精确匹配算法KMP算法之前也提到过。
N-Gram(有时也称为N元模型)是自然语言处理中一个非常重要的概念,通常在NLP中,人们基于一定的语料库,可以利用N-Gram来预计或者评估一个句子是否合理。另外一方面,N-Gram的另外一个作用是用来评估两个字符串之间的差异程度。这是模糊匹配中常用的一种手段。本文将从此开始,进而向读者展示N-Gram在自然语言处理中的各种powerful的应用。
- 基于N-Gram模型定义的字符串距离
- 利用N-Gram模型评估语句是否合理
- 使用N-Gram模型时的数据平滑算法
基于N-Gram模型定义的字符串距离
在自然语言处理时,最常用也最基础的一个操作是就是“模式匹配”,或者称为“字符串查找”。而模式匹配(字符串查找)又分为精确匹配和模糊匹配两种。
所谓精确匹配,大家应该并不陌生,比如我们要统计一篇文章中关键词 “information” 出现的次数,这时所使用的方法就是精确的模式匹配。这方面的算法也比较多,而且应该是计算机相关专业必修的基础课中都会涉及到的内容,例如KMP算法、BM算法和BMH算法等等。
另外一种匹配就是所谓的模糊匹配,它的应用也随处可见。例如,一般的文字处理软件(例如,Microsoft Word等)都会提供拼写检查功能。当你输入一个错误的单词,例如 “ informtaion” 时,系统会提示你是否要输入的词其实是 “information” 。将一个可能错拼单词映射到一个推荐的正确拼写上所采用的技术就是模糊匹配。
模糊匹配的关键在于如何衡量两个长得很像的单词(或字符串)之间的“差异”。这种差异通常又称为“距离”。这方面的具体算法有很多,例如基于编辑距离的概念,人们设计出了 Smith-Waterman 算法和Needleman-Wunsch 算法,其中后者还是历史上最早的应用动态规划思想设计的算法之一。现在Smith-Waterman 算法和Needleman-Wunsch 算法在生物信息学领域也有重要应用,研究人员常常用它们来计算两个DNA序列片段之间的“差异”(或称“距离”)。甚至于在LeetCode上也有一道“No.72 Edit Distance”,其本质就是在考察上述两种算法的实现。可见相关问题离我们并不遥远。
N-Gram在模糊匹配中的应用
我们除了可以定义两个字符串之间的编辑距离(通常利用Needleman-Wunsch算法或Smith-Waterman算法)之外,还可以定义它们之间的N-Gram距离。N-Gram(有时也称为N元模型)是自然语言处理中一个非常重要的概念。假设有一个字符串 s,那么该字符串的N-Gram就表示按长度 N 切分原词得到的词段,也就是 s 中所有长度为 N 的子字符串。设想如果有两个字符串,然后分别求它们的N-Gram,那么就可以从它们的共有子串的数量这个角度去定义两个字符串间的N-Gram距离。但是仅仅是简单地对共有子串进行计数显然也存在不足,这种方案显然忽略了两个字符串长度差异可能导致的问题。比如字符串 girl 和 girlfriend,二者所拥有的公共子串数量显然与 girl 和其自身所拥有的公共子串数量相等,但是我们并不能据此认为 girl 和girlfriend 是两个等同的匹配。
为了解决该问题,有学者便提出以非重复的N-Gram分词为基础来定义 N-Gram距离这一概念,可以用下面的公式来表述:
此处,|GN(s)| 是字符串 s 的 N-Gram集合,N 值一般取2或者3。以 N = 2 为例对字符串Gorbachev和Gorbechyov进行分段,可得如下结果(我们用下画线标出了其中的公共子串)。
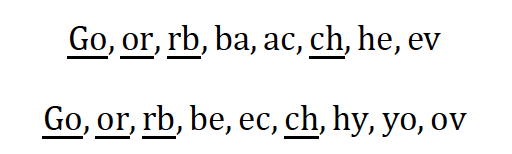
结合上面的公式,即可算得两个字符串之间的距离是8 + 9 − 2 × 4 = 9。显然,字符串之间的距离越小,它们就越接近。当两个字符串完全相等的时候,它们之间的距离就是0。