N-Gram是一种基于统计语言模型的算法
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,并且按照事先设定好的阈值进行过滤,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
n元语法模型是基于(n-1)阶马尔可夫链的一种概率语言模型,通过n个语词出现的概率来推断语句的结构。
N-Gram: (linguistics) a contiguous sequence of n items from a given sequence of text or speech.
N-Gram 指文本中连续出现的n个语词。
一元语言模型
unigram (plural unigrams)
(linguistics) An n-gram consisting of a single item from a sequence
由序列中的单个Item组成的n-gram
一元语言模型中,我们的句子概率定义为:

我们应该如何得到每个参数实例的值。用的是极大似然估计法。
比如我们说我们的训练语料是下面这个简单的语料。

那么我们的字典为:“星期五早晨,我特意起了个大早为的就是看天空。” 22个不同词(字典中包含的词语,是去重之后的),每个词语的概率直接用极大似然估计法估计得到。
如:p(星)=1/27,p(期)=1/27,一直算到后面的空为1/27. (包含标点符号)
于是我们就需要存储我们学习得到的模型参数,一个向量,22维,每个维度保存着每个单词的概率值。
那么有同学就需要问了,来了一句话,我们应该怎么估计呢?下面我举一个简单的例子来模拟一下如何用语言模型估计一句话的概率,比如:
p(我看看早晨的天空)=p(我)*p(看)*p(看)*p(早)*p(晨)p(的)p(天)p(空)=1/271/271/27…*1/27就能够直接运算出来。
于是我们得出,只要将每句话拆开为每个单词然后用累积形式运算,这样我们就能算出每句话的概率来了。
但是这样是不是就解决我们所有的问题呢?并没有,下面我们介绍二元语言模型。
二元语言模型
介绍二元语言模型之前,我们首先来看两句话,he eats pizza与he drinks pizza,我们需要用语言模型来判断这两句话出现的概率。
好,那么我们现在用一元语言模型来分别计算这两个句子的概率大小。
p(he eats pizza) = p(he)*p(eats)*p(pizza)
p(he drinks pizza) = p(he)*p(drinks)*p(pizza)
我们可以看出,其实通过一元语言模型的计算公式,我们看不出上面两个句子的概率有多大差别,但是我们很明显知道第一句话比第二句话的概率要大的多,因为正确的表达应该就是吃披萨,而不是喝披萨。
但是由于我们用了一元语言模型,假设每个词都是条件无关的,这样的话就会导致我们考虑不到两个词之间的关系搭配,比如在这个例子中,很明显应该判断的是p(pizza|eats)与p(pizza|drinks)的概率大小比较。
这也就是二元语言模型需要考虑的问题。
我们需要计算p(pizza|eats)与p(pizza|drinks)的概率,我们首先给出二元语言模型的定义 :
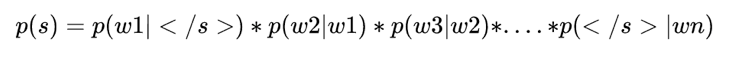
下面我们举出一个例子(例子来源于https://class.coursera.org/nlp/):
这个例子来自大一点的语料库:
假设现在有一个语料库,我们统计了下面一些词出现的数量

下面这个概率作为其他一些已知条件给出:
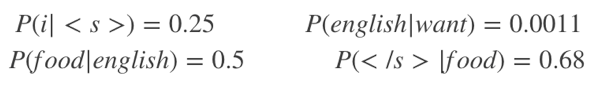
下面这个表给出的是基于Bigram模型进行计数之结果
为了计算对应的二元模型的参数,即P(wi | wi-1),我们要先计数即c(wi-1,wi),然后计数c(wi-1),再用除法可得到这些条件概率。可以看到对于c(wi-1,wi)来说,wi-1有语料库词典大小(记作|V|)的可能取值,wi也是,所以c(wi-1,wi)要计算的个数有|V|^2。
c(wi-1,wi)计数结果如下:
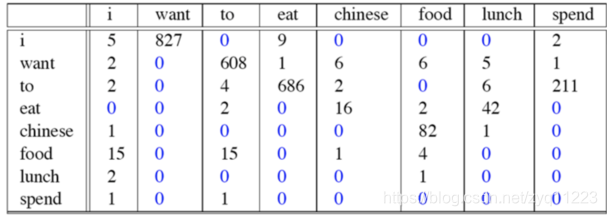
例如,其中第一行,第二列 表示给定前一个词是 “i” 时,当前词为“want”的情况一共出现了827次。据此,我们便可以算得相应的频率分布表如下。
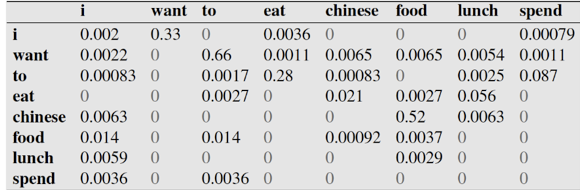

再比如说我们就以表中的p(eat|i)=0.0036这个概率值讲解,从表一得出“i”一共出现了2533次,
而其后出现eat的次数一共有9次,p(eat|i)=p(eat,i)/p(i)=count(eat,i)/count(i)=9/2533 = 0.0036
下面通过基于这个语料库来判断
s1=“<s> i want english food</s>”
与s2 = "<s> want i english food</s>"哪个句子更合理:
首先来判断p(s1)
P(s1)=P(i|<s>)P(want|i)P(english|want)P(food|english)P(</s>|food)
=0.25×0.33×0.0011×0.5×0.68=0.000031
再来求p(s2)?
P(s2)=P(want|<s>)P(i|want)P(english|want)P(food|english)P(</s>|food)
=0.25*0.0022*0.0011*0.5*0.68 = 0.00000002057
通过比较我们可以明显发现0.00000002057<0.000031,
也就是说s1= "i want english food</s>"更合理。
然后下面的思路就很简单了,在给定的训练语料中,利用贝叶斯定理,将上述的条件概率值(因为一个句子出现的概率都转变为右边条件概率值相乘了)都统计计算出来即可。下面会给出具体例子讲解。这里先给出公式:
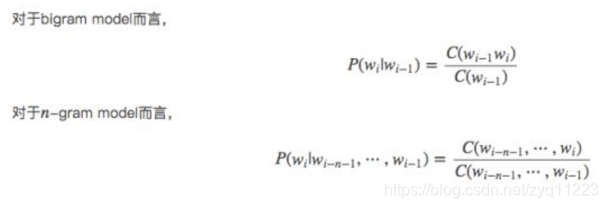
对第一个进行解释,后面同理,如下:
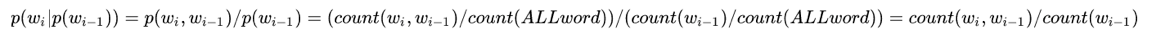
式中,C(wi-(n-1),wi-(n-2),…,wi-1,wi)表示字符串wi-(n-1),wi-(n-2),…,wi-1,wi出现在语料库中的次数。
根据上述模型定义可以看出:
- 当n越小时,模型只考虑领近词语之间的关系。尤其是对于n=1时的特殊情况,被称之为unigram,此时对于每一个词的概率评估实际上与文本的上下文无关,仅与当前词语在语料库中出现的概率有关,但人们不会以一个词一个词的方式交流,而是要以词组成句子和段落,所以要预测一个词是否出现,需要考虑上下文中的更多词,即增大n 的取值,以捕捉更多的有用信息。
- 然而,另一方面,当n越大时,虽然模型会考虑更长距离的上下文之间的关联关系,但随着n的取值增大,语言模型的参数越多,将导致参数空间过大到无法估算。若词表集合为V,其中单词数量为|V|,则由这些词组成的N元组合的数目为|V|^n,也就是说,组合数目会随着n的增大呈指数级的增长。同时,对于一条用于训练的词序列长度为1语料数据,可以提供的n元词语组合的总数为(l-n+1)。
- 根据Zipf定律,少量词语占据了大部分的出现频次,若去除掉重复出现的n元组合,语料数据能提供的信息将更少。相对于语言模型的参数估计需求来说,语料数据是非常稀疏的。除非有海量的各种类型的语料数据,负责大量的n元组合都不曾在训练语料中出现过,依据最大似然估计得到的概率将会是0,也就是说模型可能仅仅能计算廖廖几个句子。
利用N-Gram模型评估语句是否合理
为了引入N-Gram的这个应用,我们从几个例子开始。
首先,从统计的角度来看,自然语言中的一个句子 s 可以由任何词串构成,不过概率 P(s) 有大有小。例如:



接下来的思路就比较明确了,可以利用最大似然法来求出一组参数,使得训练样本的概率取得最大值。

来看一个具体的例子,假设我们现在有一个语料库如下,其中<s1><s2> 是句首标记,</s2></s1> 是句尾标记:

Zipf定律描述
Zipf定律是美国学者G.K.齐普夫提出的。
可以表述为:在自然语言的语料库里,一个单词出现的次数与它在频率表里的排名成反比。
1935年,哈佛大学的 语言学专家Zipf在研究英文单词出现的频率时,发现如果把单词出现的频率按由大到小的顺序排列,则每个单词出现的频率与它的名次的常数次幂存在简单的反 比关系,这种分布就称为Zipf定律,它表明在英语单词中,只有极少数的词被经常使用,而绝大多数词很少被使用.实际上,包括汉语在内的许多国家的语言都 有这种特点。这个定律后来在很多领域得到了同样的验证,包括网站的访问者数量、城镇的大小和每个国家公司的数量。
例子
比如我们现在使用单元Unigram、二元的Bi-gram和三元的Tri-gram模型来对进行特征提取。
我们的训练样本为:
1)我去了北京天安门
2)我是中国人
那么我们对每一个样本进行单元Unigram、二元的Bi-gram和三元的Tri-gram模型提取。
单元Unigram来说
对于:“我去了北京天安门”
抽取 我 去了 北京 天安门
对于:“我是中国人”
抽取 我 是 中国人
二元Bi-gram
对于:“我去了北京天安门”
抽取 我 去了/ 去了 北京/ 北京 天安门/
对于:“我是中国人”
抽取 我 是 / 是 中国人/
三元Tri-gram
对于:“我去了北京天安门”
抽取 我 去了 北京/ 去了 北京 天安门/
对于:“我是中国人”
抽取 我 是 中国人/
那么从上面可以得出,我们的特征向量包含我在训练数据中利用单元Unigram,二元Bi-gram,
以及三元Tri-gram抽取出的不同特征,组成我的特征向量维度。
然后以后对应一句话,直接进行Unigram,Bi-gram,Tri-gram进行抽取特征,出现哪个特征,
就统计它的频数,最后填在特征向量中即可。
比如上面的特征向量我列举一下顺序如:
我、是、中国人、去了、北京、天安门、我 是、是 中国人、我 去了、去了 北京、北京 天安门、
我 去了 北京、去了 北京 天安门、 我 是 中国人、
抽取特征过程
那么对于一句话“我是中国人”进行N-gram特征抽取的方法是。
单元Unigram来说
对于:“我是中国人”
抽取 我 是 中国人
二元Bi-gram
对于:“我是中国人”
抽取 我 是 / 是 中国人/
三元Tri-gram
对于:“我是中国人”
抽取 我 是 中国人/
于是我们就在出现的词语维度赋值为1,其余没有出现过的特征赋值为0,相当于one-hot特征。
得到特征向量如下:
[1,1,1,0,0,0,1,1,0,0,0,0,0,0,1]
得到的上面这个特征向量就是我们使用N-gram提取特征方法提取出来的特征。
总结
如果我们使用N-gram提取特征,使用unigram,bigram,trigram提取特征的情况,
在词汇表大小为V的时候,特征向量维度长度为[V(unigram)+V^2(bigram)+V^3(trigram)]
数据量太大,维度爆炸怎么办 ?
要考虑用频度阈值和停用词表进行过滤,实际上如果考虑zipf定律的话,高频常用词组可能也没那么多
使用N-Gram模型时的数据平滑算法
背景:为什么要做平滑处理?
零概率问题,就是在计算实例的概率时,如果某个量x,在观察样本库(训练集)中没有出现过,会导致整个实例的概率结果是0。在文本分类的问题中,当一个词语没有在训练样本中出现,该词语调概率为0,使用连乘计算文本出现概率时也为0。这是不合理的,不能因为一个事件没有观察到就武断的认为该事件的概率是0。
有研究人员用150万词的训练语料来训练 trigram 模型,然后用同样来源的测试语料来做验证,结果发现23%的 trigram 没有在训练语料中出现过。这其实就意味着上一节我们所计算的那些概率有空为 0,这就导致了数据稀疏的可能性,我们的表3中也确实有些为0的情况。对语言而言,由于数据稀疏的存在,极大似然法不是一种很好的参数估计办法。
这时的解决办法,我们称之为“平滑技术”(Smoothing)或者 “减值” (Discounting)。其主要策略是把在训练样本中出现过的事件的概率适当减小,然后把减小得到的概率密度分配给训练语料中没有出现过的事件。实际中平滑算法有很多种,例如:
▸ Laplacian (add-one) smoothing
▸ Add-k smoothing
▸ Jelinek-Mercer interpolation
▸ Katz backoff
▸ Absolute discounting
▸ Kneser-Ney
平滑技术
平滑技术是为了解决训练集的数据稀松问题。
零概率问题,就是在计算实例的概率时,如果某个量x,在观察样本库(训练集)中没有出现过,会导致整个实例的概率结果是0。在文本分类的问题中,当一个词语没有在训练样本中出现,该词语调概率为0,使用连乘计算文本出现概率时也为0。这是不合理的,不能因为一个事件没有观察到就武断的认为该事件的概率是0。
一般的m阶马尔科夫链转移概率是这样训练的:
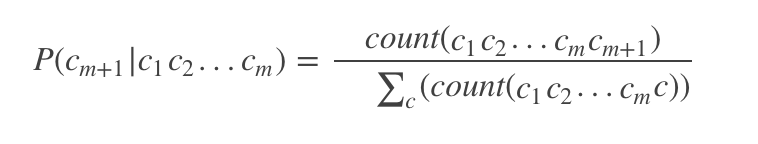
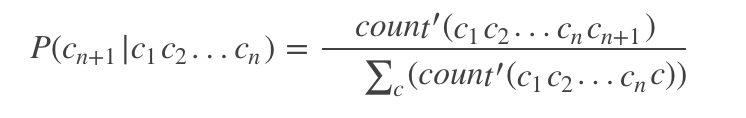
count(c1c2…cmc) 是训练集中所有(m+1)-gram的数量,比如“abcd”,如果训练集中没有出现“ab@”这样的3-gram,那么P(@|ab)=0,这样所有的前缀为”ab@”的字符串的概率就都为0了,这样所有在训练集中未出现的n-gram,就会被判定为概率为0,“ab@password”和”ab@sdf#2(“的概率都为0,这是不合理的。解决办法就是对未出现的n-gram,给他们一个较小的概率,避免让其为0.

拉普拉斯的理论支撑
为了解决零概率的问题,法国数学家拉普拉斯最早提出用加1的方法估计没有出现过的现象的概率,所以加法平滑也叫做拉普拉斯平滑。
假定训练样本很大时,每个分量x的计数加1造成的估计概率变化可以忽略不计,但可以方便有效的避免零概率问题。
应用举例
假设在文本分类中,有3个类,C1、C2、C3,在指定的训练样本中,某个词语K1,在各个类中观测计数分别为0,990,10,K1的概率为0,0.99,0.01,对这三个量使用拉普拉斯平滑的计算方法如下:
1/1003 = 0.001,991/1003=0.988,11/1003=0.011
将公式1.1的每个count和公式1.2中的count’,都加一个正数a,这就避免了转移概率出现0的情况。
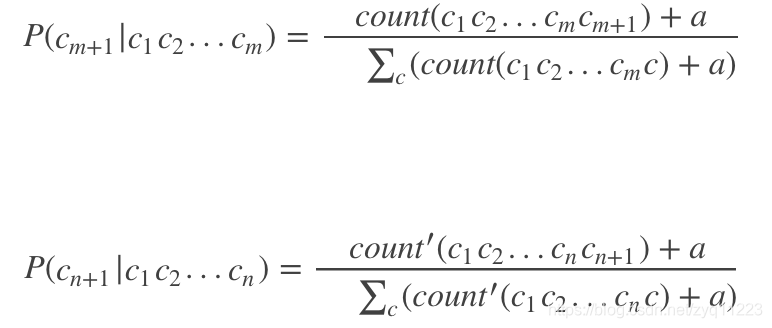
建议取a=0.01.
拉普拉斯平滑
拉普拉斯平滑(Laplace Smoothing)又被称为加 1 平滑,是比较常用的平滑方法。平滑方法的存在是为了解决零概率问题。
参考:
https://blog.csdn.net/baimafujinji/article/details/51281816
https://blog.csdn.net/u010899985/article/details/79177053
https://blog.csdn.net/zhengwantong/article/details/72403808
https://zhuanlan.zhihu.com/p/32829048