在自然语言处理领域,最开始的学习肯定绕不开one-hot,N-gram,word2vec。下文会快速,简要的介绍这两种技术,至于更多的技术细节,可以参考文章最后的参考文献。在阅读了本篇文章后,读者应该能够达到如下几个目的:
1.明白one-hot,N-gram,word2vec的作用
2.明白one-hot,N-gram,word2vec的数学/网络架构
1.词向量
词向量就是用来将语言中的词进行数学化的一种方式,顾名思义,词向量
就是把一个词表示成一个向量。这样做的初衷就是机器只认识0 1 符号,换句话说,在自然语言处理中,要想让机器识别语言,就需要将自然语言抽象表示成可被机器理解的方式。所以,词向量是自然语言到机器语言的转换。
词向量最初是用one-hot represention表征的,也就是向量中每一个元素都关联着词库中的一个单词,指定词的向量表示为:其在向量中对应的元素设置为1,其他的元素设置为0。采用这种表示无法对词向量做比较,后来就出现了分布式表征。
在word2vec中就是采用分布式表征,在向量维数比较大的情况下,每一个词都可以用元素的分布式权重来表示,因此,向量的每一维都表示一个特征向量,作用于所有的单词,而不是简单的元素和值之间的一一映射。这种方式抽象的表示了一个词的“意义”。
向量的长度为词典的大小,向量的分量只有一个 1,其他全为 0, 1 的位置对应该词在词典中的位置,例如
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …]
“麦克”表示为 [0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 …]
优点: 如果使用稀疏方式存储,非常简洁,实现时就可以用0,1,2,3,…来表示词语进行计算,这样“话筒”就为3,“麦克”为8.
缺点:1.容易受维数灾难的困扰,尤其是将其用于 Deep Learning 的一些算法时;2.任何两个词都是孤立的,存在语义鸿沟词(任意两个词之间都是孤立的,不能体现词和词之间的关系)。
也正是这些原因,Hinton在 1986 年提出了Distributional Representation,可以克服 one-hot representation的缺点。解决“词汇鸿沟”问题,可以通过计算向量之间的距离(欧式距离、余弦距离等)来体现词与词的相似性
。
其基本想法是直接用一个普通的向量表示一个词,这种向量一般长成这个样子:[0.792, −0.177, −0.107, 0.109, −0.542, …],常见维度50或100。
优点:解决“词汇鸿沟”问题
缺点:训练有难度。没有直接的模型可训练得到。所以采用通过训练语言模型的同时,得到词向量 。
当然一个词怎么表示成这么样的一个向量是要经过一番训练的,训练方法较多,word2vec是其中一种。值得注意的是,每个词在不同的语料库和不同的训练方法下,得到的词向量可能是不一样的。
2.N-gram
N-gram就是最简单的一种语言模型。在一些NLP任务中,我们需要判断一句话出现的概率是多少,即这句话是不是符合人的说话习惯,这时就可以利用到N-gram。另外,N-gram可以用于实现汉字转换,关于这点,读者可以查询资料。
N-gram的数学模型非常简单,就是一条数学表达式:
上面概率公式的意义为:第一次词确定后,看后面的词在前面次出现的情况下出现的概率。
例如,有个句子“大家喜欢吃苹果”,一共四个词”大家,喜欢,吃,苹果”
P(大家,喜欢,吃,苹果)=p(大家)p(喜欢|大家)p(吃|大家,喜欢)p(苹果|大家,喜欢,吃)
p(大家)表示“大家”这个词在语料库里面出现的概率;
p(喜欢|大家)表示“喜欢”这个词出现在“大家”后面的概率;
p(吃|大家,喜欢)表示“吃”这个词出现在“大家喜欢”后面的概率;
p(苹果|大家,喜欢,吃)表示“苹果”这个词出现在“大家喜欢吃”后面的概率。
把这些概率连乘起来,得到的就是这句话平时出现的概率。
如果这个概率特别低,说明这句话不常出现,那么就不算是一句自然语言,因为在语料库里面很少出现。如果出现的概率高,就说明是一句自然语言
为了表示简单,上面的公式用下面的方式表示
其中,如果Contexti是空的话,就是它自己p(w),另外如“吃”的Context就是“大家”、“喜欢”,其余的对号入座。
因此,如何计算 呢? 上面看的是跟据这句话前面的所有词来计算,这样计算就很复杂,像上面那个例子得扫描四次语料库,这样一句话有多少个词就得扫描多少趟。语料库一般都比较大,越大的语料库越能提供准确的判断。这样计算开销太大。
N-gram的精髓
为了解决这个问题,N-gram假设一句话中,一个字只跟这个字之前的几个字相关(一般为2或3),这本身就是马尔科夫模型的思想。因此,上式的计算变成:
如果一个词的出现仅依赖于它前面出现的一个词,那么我们就称之为bigram。即
如果一个词的出现仅依赖于它前面出现的两个词,那么我们就称之为trigram。
为什么只考虑2和3呢?这里主要是考虑到计算机的算力。取3时,所有可能的N-gram的个数,已经接近计算机的最大算力了。
3.word2vec
现在得到词向量最常用的方法是什么?毫无疑问是word2vec。word2vec通过训练一个神经网络,得到网络的权重矩阵,作为输入的词向量。常用的word2vec模型是:CBOW,Skip-gram。框架图如下:
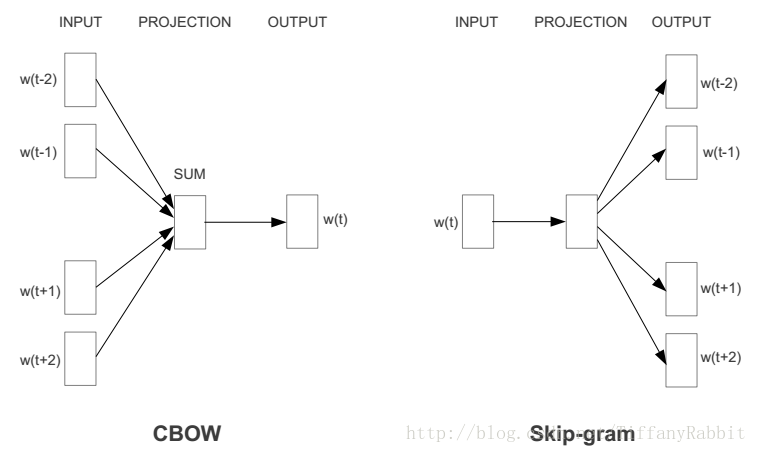
CBOW,Skip-gram两者的差别在于:CBOW通过上下文预测中心词概率,而Skip-gram模型则通过中心词预测上下文的概率。
什么意思呢?举个例子,对于一句话:社会主义就是好,对于CBOW,如果要预测“主义”,则输入就是“社会”,“就是”,“好”;对于Skip-gram,输入则是“主义”,输出是剩下的几个字。
但它们的相同点在于,这两个算法训练的目标都是最大限度的观察实际输出词(焦点词)在给定输入上下文且考虑权重的条件概率。比如在上段的例子里,通过输入“社会”,“就是”,“好”之后,算法的目标就是训练出一个网络,在输出层,能最大概率的得到“主义”的条件概率。
下面基于CBOW,详细讲述一下网络架构:
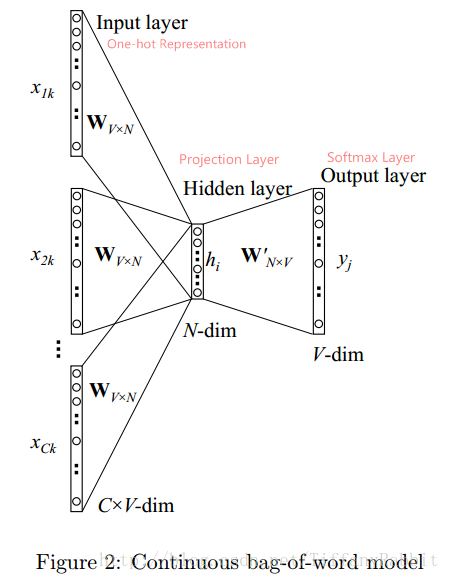
上图是CBOW的架构。
符号定义: 语料库为D,词汇总数V;考虑上下文词语数C个,分别表示为
;映射层/词向量维度为N;
为词汇w的One-hot Representation,V维;
为词汇w的词向量,N维。
输入层: 输入层的节点为C个上下文词语的one-hot表示,共C*V输入节点。
映射层: 将输入层节点乘上权重矩阵
得到的词向量(word embedding)求平均得到h。公式如下。
输出层: 映射层经过
(而后即为
) 权重矩阵后,得到V维z, 再对z进行softmax操作得到中心词为某个词j的概率分布。公式如下。
这个神经网络,除了训练出了一个语言模型,更为重要的是得到了源输入的词向量表示,那就是权重矩阵 。
如何理解?举个例子就知道了。如果输入是10000*1的one-hot向量,而隐含层神经元是300,则可见,权重矩阵(输入层-隐含层)为10000*300。而这时,权重矩阵的每一行就是一个词的词向量。为什么?我们来看看这个乘法:

假设等号最左边是输入,然后乘以权重矩阵,可见输出就是权重矩阵在对应输入向量元素值为1的索引的行。因此,得到的权重矩阵的每一行都是词向量。
好了,到此就介绍完毕了,下面这几篇参考文献都是不错的学习资料,可以参考。
参考文献
【1】 word2vec 入门基础(一)
https://www.cnblogs.com/tina-smile/p/5176441.html
【2】一文详解 Word2vec 之 Skip-Gram 模型(结构篇)https://www.leiphone.com/news/201706/PamWKpfRFEI42McI.html
【3】语言模型系列之N-Gram、NPLM及Word2vec(包含代码使用方法)
https://blog.csdn.net/TiffanyRabbit/article/details/72654180
【4】word2vec 中的数学原理详解(四)基于 Hierarchical Softmax 的模型
https://blog.csdn.net/itplus/article/details/37969979
【5】word2vec词向量训练及gensim的使用(最为浅显易懂)https://blog.csdn.net/zl_best/article/details/53433072/