1、什么是布隆过滤器
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
他就是一个很大的二进制数组
误判率跟哈希函数的次数,位数组的长度有关
2、布隆过滤器原理
布隆过滤器的核心实现是一个超大的位数组和几个哈希函数。假设位数组的长度为m,哈希函数的个数为k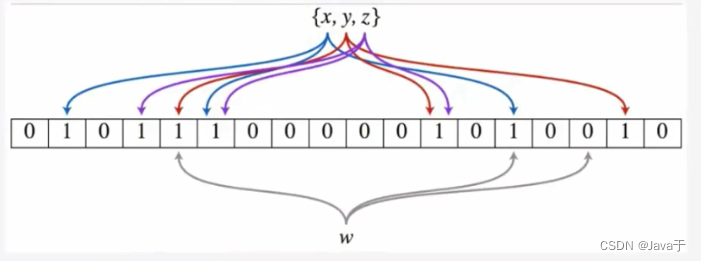
3、空间计算
在布隆过滤器增加元素之前,首先需要初始化布隆过滤器的空间,也就是上面说的二进制数组,除此之外还需要计算无偏hash函数的个数。布隆过滤器提供了两个参数,分别是预计加入元素的大小n,运行的错误率f。布隆过滤器中有算法根据这两个参数会计算出二进制数组的大小l,以及无偏hash函数的个数k。
- 错误率越低,位数组越长,控件占用较大
- 错误率越低,无偏hash函数越多,计算耗时较长
4、测试一个元素是否属于一个百万元素集合所需耗时
4.1 引入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>22.0</version>
</dependency>4.2 测试
public class Test {
private static int size = 1000000;
private static BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(),size);
public static void main(String[] args) {
for (int i = 0; i < size; i++) {
bloomFilter.put(i);
}
ArrayList<Integer> list = new ArrayList<>(10000);
for (int i = size+10000; i < size+20000; i++) {
if (bloomFilter.mightContain(i)){
list.add(i);
}
}
System.out.println("误判的数量" + list.size());
}
}
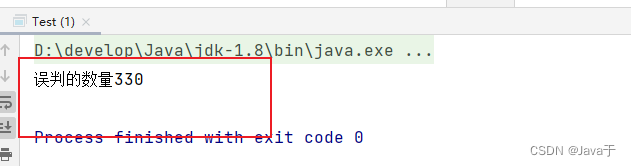
从上面可以看出,我们故意取10000个不在过滤器里的值,却还有330个被认为在过滤器里,这说明误判率0.03
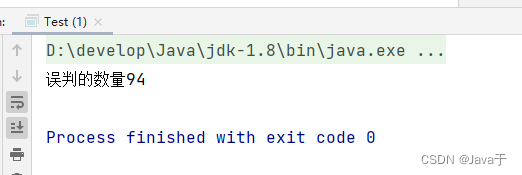
也可以该误判率,这就会导致位数增大

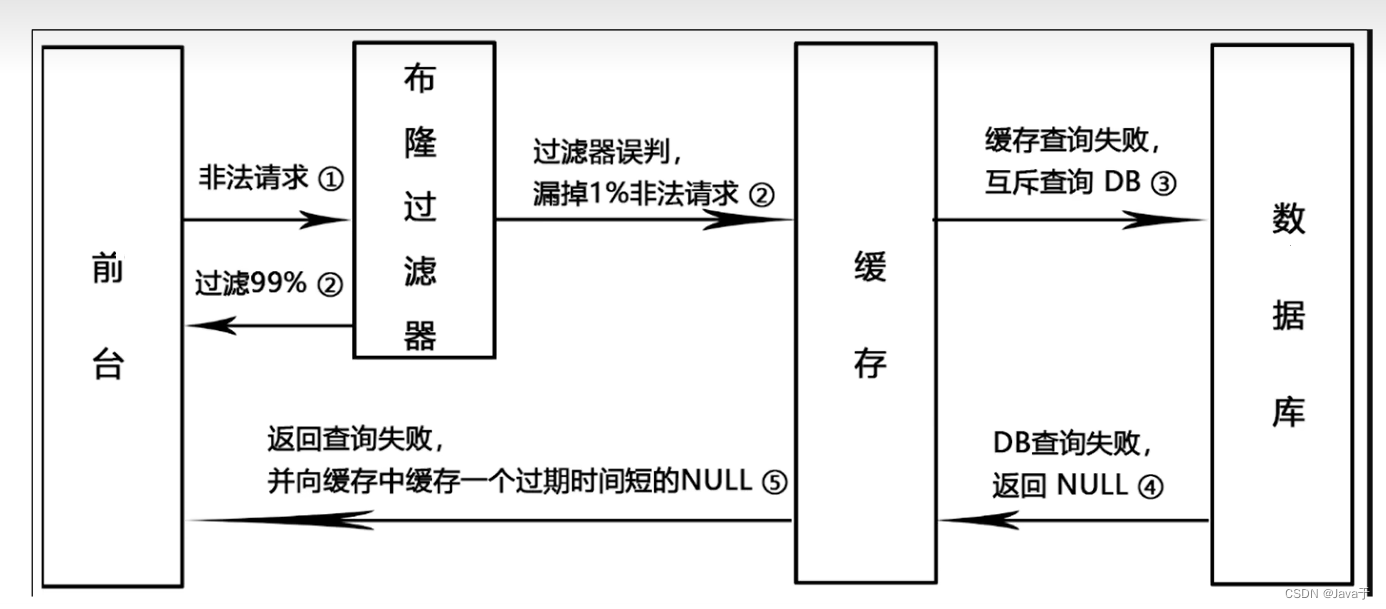
将所有可能存在的数据缓存放到布隆过滤器中,当黑客访问不存在的缓存时迅速返回避免缓存及DB挂掉。

redis伪代码如下所示
String get(String key) { //布隆过滤器钟存储的是数据库表钟对应的id
if(!bloomfilter.mightContain(key)){
return null;
}
String value=redis.get(key);//先从缓存获取.
if(value!=null){
return value;
}
value = db.get(key);//查询数据库
redis.set(key, value);
return value;
}