一、概念
什么是强化学习?
1.难点
- reward的出现是延迟的
- agent的action会影响结果或者反馈reward
2.分类
policy based =》learning a actor;value-based=》learning a critic
2.1 policy based
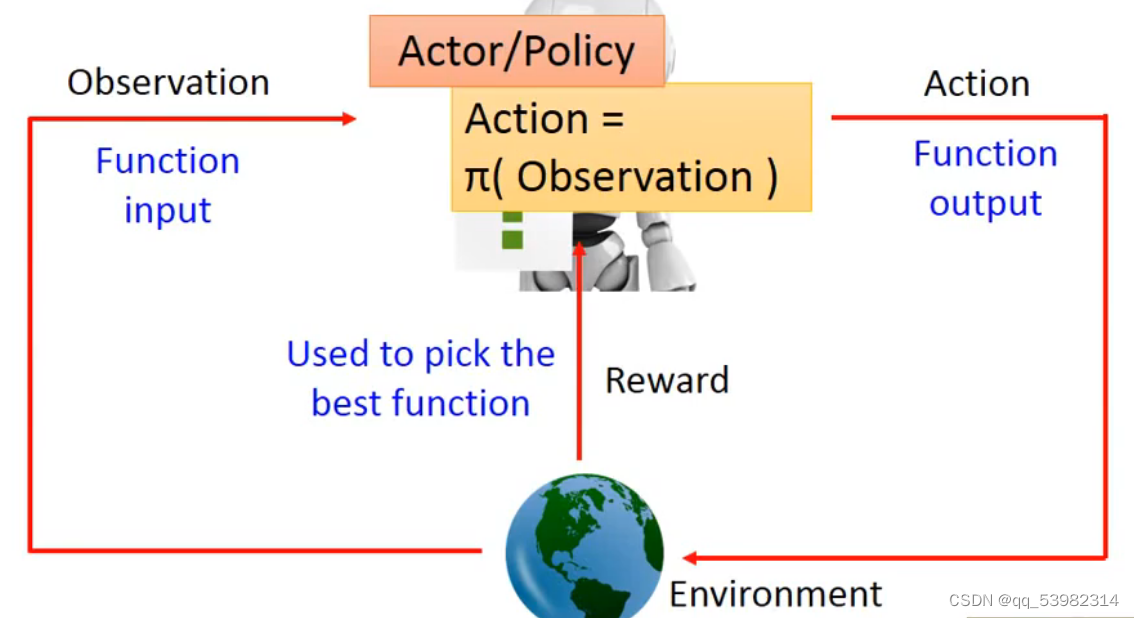
policy based的流程框架如下图所示:
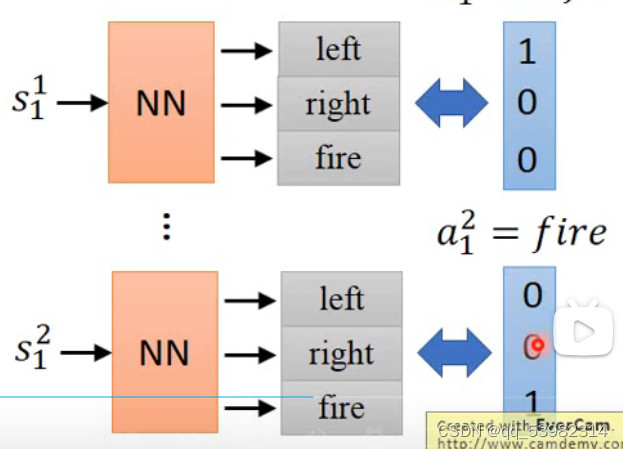
神经网络输出actor: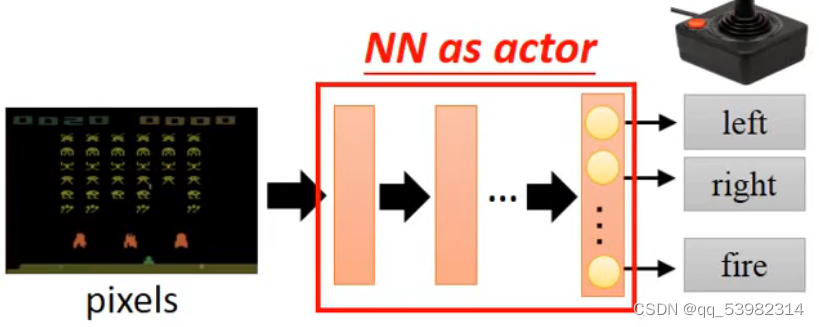
神经网络输出的是不同的action的概率,最高的就是这一步的action。
Start with observation S1;
Machine decides to take a1
Machine obtains reward ri
Machine sees observation S2
Machine decides to take a2
Machine obtains reward r2
……
总的概率计算公式如下: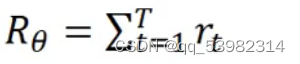 因为行为和游戏具有随机性,则这个R是不确定的。则设置
因为行为和游戏具有随机性,则这个R是不确定的。则设置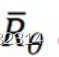 作为R的期望值,评估了行为向量的好坏。
作为R的期望值,评估了行为向量的好坏。
- goodness of actor
输入参数: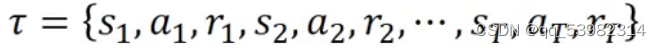
我选择这个行为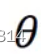 的概率:
的概率: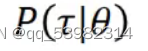 。
。
则 就是期望的reward。即每个行为的reward和每个行为的概率相乘,然后相加。
就是期望的reward。即每个行为的reward和每个行为的概率相乘,然后相加。
那如何选择最好的actor呢?使用的方法就是gradient ascent
-
gradient ascent
求reward最大值时候的值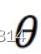 :
: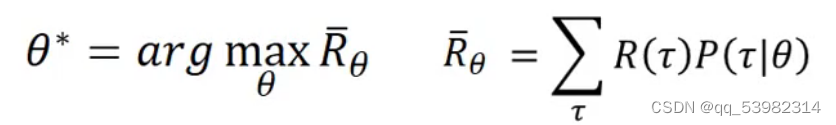 。
。过程如下:先初始化,然后重复进行以下过程:
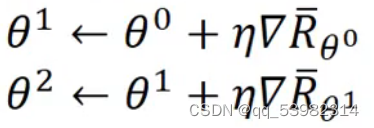
数学公式如下:
又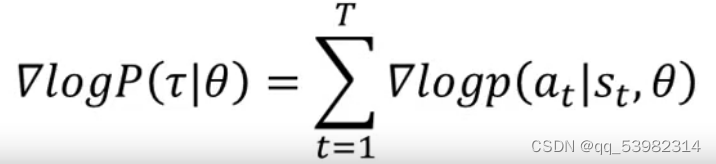
式子的理念就是:在采取的行为是积极的时候,就提升 的概率;反之,就降低。
的概率;反之,就降低。
但是这样不够完善,飞机可能在原地一直开火,如何使得太低的增加?
add a baseline。
- add a baseline
现实的例子,在大家都增加之后,被归一化之后,即使概率增加也没有用,也会是相对最低的。如图所示,a的即使增加的最多,在归一化之后也是概率最小的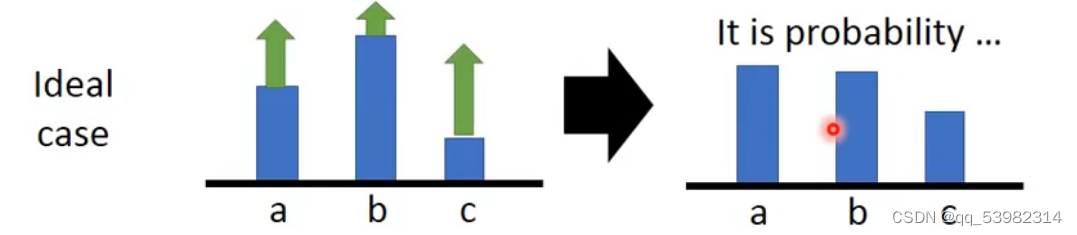
也有情况会使得没出现的action的几率变得更小,如下图所示,a没有出现,所以概率减小: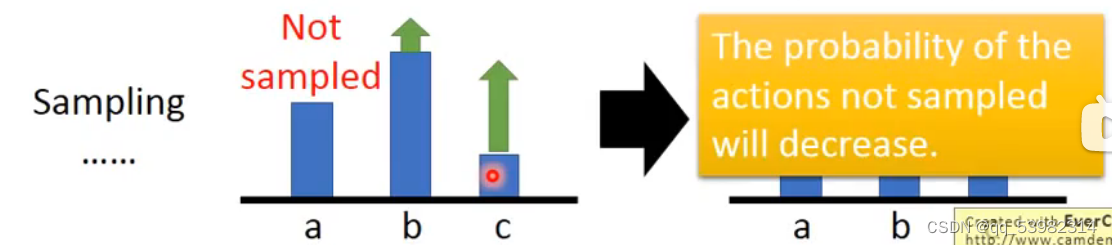
那就要设计一个较好的b值,使得概率的梯度变得有正有负。
公式成为下图: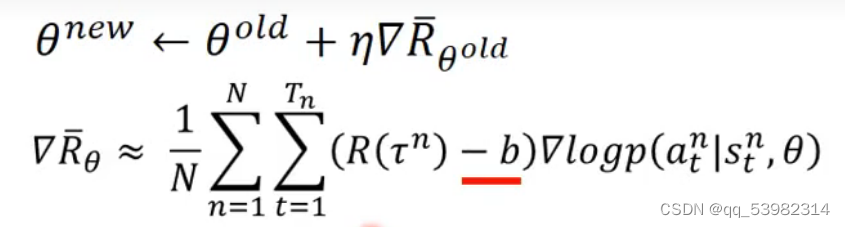
2.2 policy gradient
由 经过神经网络得到
经过神经网络得到