文章目录
1.开启本系列目的
最近开始阅读Sutton教授的《Reinforcement learning: An Introduction(second edition)》一书,希望在记录自己学习心得的同时,也能和大家分享自己思考的一些内容,同时帮助英文不好的同学对本书有一个基本的了解。
其实说来惭愧,虽然这一年多也接触了不少强化学习的知识,甚至学习了很多比较前沿的算法,像DQN, NAF, DDPG, A3C, A2C等等,但是却从来没有认真读过这本,其实主要是源于自己对于英文教材的抗拒(被英文自控原理课吓得有后遗症了…),然而越来越发现,没有扎实的基础,一旦涉及到较深刻的理论,就没办法真正理解其背后的逻辑,导致知识永远是悬浮在空中的。所以,无论如何要戒骄戒躁,多下功夫在基础知识上,所谓磨刀不误砍柴工,确实有理。
本系列博客,每篇介绍一章的内容,每周更新一章。其实自己已经对课题组的同学们承诺用一个学期左右的时间把这本书介绍完,而系列博客能督促自己尽量认真地准备每周讲的内容,对自己个人而言也是一种督促。毕业之前,希望自己至少能把这本书的归纳完成。
实际上,本来计划和几位师兄弟协作,把这本书认真翻译一遍放到Github上的,但是后来考虑到这种做法可能会侵犯作者的权利,导致一些不必要的麻烦;而且近段时间实在是忙不过来,感觉也很难拿出这么多时间完整地完成这项工作;此外,我现在发现,翻译本书这件事已经有兄弟开始搞起来了(点这里)。
本人水平有限,尤其数学水平一向较差,因此文中出现的纰漏也请体谅。本系列会大量参考各位兄弟的资料,比如上面提到的那个专栏,我会将所有引用的地方注明出处。本系列着重于各章的核心知识点,就不一一翻译了,通过本系列文章应该可以大致熟悉书籍的框架内容,如需深入了解,还是要尽量阅读原文。
2.本书框架
第一章:介绍什么是强化学习,介绍强化学习的特点;
第二章~第八章:强化学习的表格算法,适用于离散问题(棋类等),也可以把连续问题离散化;
第九章~第十三章:强化学习的拟合算法,用函数拟合值函数,适合处理连续问题;
第十四章~第十七章:强化学习前沿.
3.认识强化学习
强化学习(Reinforcement Learning),简称RL。当我们思考学习的本质时,我们立即会想到我们自身,而我们人类是通过和环境不断交互,不断试错进行学习的(当然,我们学习新的知识是在已有“基础”上的,因此实际上比RL快很多,但是就交互性学习这一点是一致的)。我们通过眼睛、耳朵观察环境(状态)、通过四肢、嘴巴对环境施加影响(动作),然后我们观察环境因为我们动作所起的变化(状态转移,也就是环境模型),这个过程我们可以探索性地学习关于环境的知识,在此基础上结合我们的需求(目标),我们就能形成一个动作序列(策略),尽可能满足我们的需求。
什么是强化学习?
强化学习是学习如何做决策,把一个场景映射到一个行动,依次来最大化一个数值回报信号。学习者并没有被告诉采取哪一个动作,而是必须通过自身的尝试来发现什么样的动作可以产生最多的回报。最有意思也是最具挑战性的场景是:一个动作不仅影响当前的立即回报,同时也会影响下一个状态,通过这个状态影响所有后续的回报,因此不能仅仅考虑当前的回报,而是要把引发的后续回报折算到当前状态上来。基于试错的探索和延迟回报是强化学习最重要也是最具特殊性的两个特征[2]。
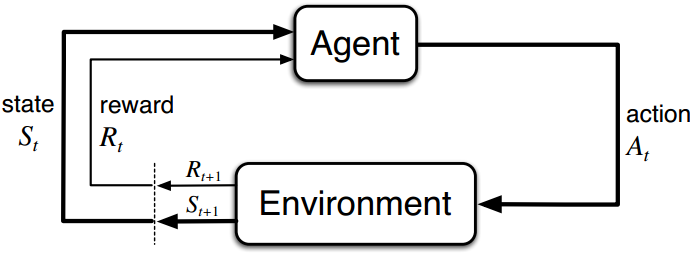
强化学习的基本特征?[2]
- 从交互中学习: 从交互中学习是所有学习和智能理论的基本思想。算法通过大量的与环境的交互(尝试和纠错trial-and-error search),从而计算出值函数,并在此过程中改善策略,最终得到最优的策略(次优的)。是边与环境交互,在目标的导引下,自主学习的。
- 通过计算学习: 强化学习是从交互中学习的计算性的方法。因为需要大量的交互实验以寻找最优策略,因此是基于计算的。
- 受目标引导的: 与其它机器学习方法相比,强化学习更重视从交互中基于目标导引的学习。RL方法不需要有标签数据(监督学习),也不寻找数据内部的结构(无监督学习),而是完全由我们设计的回报函数指引的。例如,对于棋类游戏,我们的目标就是胜利,我们就可以把胜利的盘面赋予一个正实数回报,失败的盘面赋予负实数的回报,其他情况的回报为零,然后通过学习评估哪个中间状态更有可能导致胜利的状态,根据概率加权把最终结果折扣到中间状态。
- 源自最优控制: RL的数学依据是不完全已知马尔科夫决策过程(Markov Decision Process, MDP)的最优控制,也就动态规划方法。
- 回报是延迟的: 一个动作不仅影响当前的立即回报,同时也会影响下一个状态,通过这个状态影响所有后续的回报,因此不能仅仅考虑当前的回报,而是要把引发的后续回报折算到当前状态上来。
- 算法特有问题:探索(exploration)与利用(exploitation)的平衡(trade off)。所谓探索就是指主动去发现新的信息,尝试非最大价值的动作,因为非最大价值的动作不一定真的不好,很可能是其值函数还没有估计准确,导致偏小了; 所谓利用就是利用当前已知的所有信息,找到最佳的动作序列,达到最大化总回报的目标(从而准确地估计出最优策略的值函数). 一味地探索就需要花费大量的尝试来估计每个动作的好坏,而一味地利用则会错过发现更好的动作的机会,从而陷入局部最优,因此必须要权衡探索和利用. 更深入地,探索和利用问题是由于确定性策略导致的,这使GPI(generalized policy iteration, 后续章节详细介绍)无法收敛到全局最优。
- 更高层的特征:1. 提供一种“决策的通用方法”; 2. 能较好地解决维度诅咒问题; 3. 体现了人工智能回归简单的特点(表明学习的方法不是weak methods)。4. RL可以用于研究对象整体,也可以用于研究对象的一部分(机器人整体/机器人路径规划)。5. 与很多学科密切相关:统计学、优化、神经科学等。
机器学习的三大范式
监督学习:监督学习尝试从一些表示(当前状态, 应该采取的行动)的对应中,泛化出能够在遇到之前没有见过的状态时,做出正确的行动的能力。例如,图像识别问题。数据集包含图片及对应的类别,训练完毕后,给定一张不在数据集中的图片,算法给出正确的类别(泛化)。

无监督学习:无监督学习尝试找出给定的数据中隐含的内在结构与关联。例如聚类问题。数据都是分布在高维空间的点,能不能找到一些高维空间的流形,让这些数据都分布在某个流形上?

强化学习:上面已经有充分的介绍了。可以用在任何决策问题中,例如控制问题、规划问题、棋类、游戏等等。

4.一些可应用强化学习的场景
理解强化学习较好的办法是考虑一些能适用于强化学习算法的问题。例如:
- 象棋游戏。决策既受到预期的对方对策影响,也受到即时收益的影响。
- 炼油厂自适应控制器实时地调整其参数。
- 羚羊出生后半小时就能以20英里每小时的速度奔跑。
- 扫地机器人判断是应该到下一个房间清理,还是回到充电位置充电。
- 人准备早餐的过程:通过人的感官观察环境,根据人的需求确定目标,根据与环境交互实时修正动作。
在上面所有的例子中,环境因动作产生的后果是无法确定性地预料的,所以智能体(agent)必须不断地观察环境并恰当地反应。
5.强化学习的基本概念
- 智能体agent: 决策器
- 能在一定程度上感知当前的环境;
- 可以采取行动影响当前的环境;
- 有一个或者多个与环境状态相关的目标.
- 状态state(控制中的状态空间)
- 可以看做一种对环境的总结,包含了用于确定接下来会发生的事情的所有信息.
- 动作action
- 动作是对智能体所有可以采取的行动的一种抽象,智能体可以通过动作改变当前的状态.
- 策略policy
- 智能体的决策系统,给定当前状态,需要作出决定采取什么样的行动;
- 形式化一点来说,策略是一个由状态空间向动作空间的映射;在一般的情况下,这个映射可以是随机的(stochastic),当然也可以是确定(deterministic)的,可以记状态s下采取动作a的概率为 ,可以依照概率选择动作(stochastic),也可以选择概率最大的动作(deterministic);
- 在某些情况下,策略可能是一个简单的函数或者是一个查找表(lookup table).
- 奖励reward
- 智能体在每作出一个动作后都会收到来自环境的奖励信号(通常是一个标量),代表着对该动作的即时评价反馈,评价越高奖励越大;
- 智能体的任务就是最大化序列所得到奖励的总和.
- 值函数value function
- 回报反应的是立即的、固有的收益;状态的值则反应考虑后续状态的长期的收益;
- 值函数是智能体对每一个状态的评估,代表从这个状态出发,所能得到的奖励总和(折扣的)的期望;
- 奖励信号是由环境给出的(具体的奖励规则是我们根据需要设计的回报函数),而值函数是来自智能体的自我估计;
- 值函数是建立在奖励信号的基础上的,没有奖励信号就没有值函数;
- 与奖励信号不同的是,值函数刻画了这个状态长期意义下的好坏程度;而奖励信号是短期意义下的好坏;奖励信号只有做出那个动作才能得到,值函数则跟具体采取的动作无关,它可以指导助我们决策;
- 对于大部分强化学习算法,核心部分就是如何估计值函数.
- 环境模型environment
- 出于对人类推断(inference)能力的模仿以及对在与环境交互时代价的考虑,部分强化学习算法会考虑让智能体对其交互的环境进行建模,也就是环境模型,环境模型的核心是转移与回报的联合概率: ,在状态s下,执行动作a的条件下,下一个状态s’和回报值r的联合概率;
- 在与实际环境交互前,智能体可以先与其内部的环境模型进行交互,从而加快学习的过程(与实际环境交互学习可能不切实际,且无法超实时加速训练);
- 依据是否建立环境模型,强化学习算法可以被划分成两大类: model based RL和model free RL,model based RL收敛更快,model free RL更加通用;
- 基于模型的算法往往更加复杂.
5.与进化算法对比
本书讨论的强化学习算法都是基于值函数的,其实对于解决这一类问题这不是必须的,生物优化算法也可以看作智能化的算法,它们就不需要值函数,我们分析下它们之间的差异:

- 进化方法:遗传算法、模拟退火、各种群算法等. 每个智能体从与环境交互开始到结束,我们只在最后对其进行一次评估,并不关心在交互过程中每个状态或者行动直接的关系与影响;在小规模问题,或者算力足够,以及在环境的状态只能够被部分观察到的情况下,较RL更有优势. 进化算法是episode-by-episode的.
- 强化学习:注重于智能体与环境互动的过程中所发生的事情,利用的策略其实是一个由状态到动作的映射,往往这样的算法的学习效率更高;智能体在与环境开始交互到结束为止,会去估计每一个到过的状态或者执行过的动作对最终达到的结果有多大的贡献,这样可以得到每个状态和动作更加精确的估价,提升今后决策的可靠性. step-by-step.
注意,进化类算法我们只能说是evolution, 强化学习我们才能说是learning. 顺便提一嘴,我们院里某教授是进化算法方面的大佬.
6.一个具体的例子:Tic-Tac-Toe
这里以井字棋为例,具象化了强化学习算法的过程.
两个玩家轮流的在3×3的棋盘格上放置表示“X”或者“O”的棋子。一方只拥有一种棋子。任何一方首先在一行、一列或者对角行上布满自己的棋子就获胜。如果到最后都没有出现相邻三个同样的棋子,则为平局。理论上,对于一个资深玩家来说,最后的结果必定是平局。因此我们假设对方玩家是一个新手。问题是如何设计一个算法来最大化玩家的胜率[2]?

这个问题有很多求解方法。比如博弈论(minmax),动态规划,经典的优化方法,进化算法等。但各自具有局限性(它们往往假设对手具有同样完美的策略,然而对手的决策很可能是有缺陷的)。这里采用一种基于值函数 的方法。这里值函数表示每一个状态下胜率的大小。状态是每种可能的棋局。值函数既然表示胜率,那么每一步的决策是希望落子之后对应的新状态的值越大越好。状态A比状体B好,言下之意就是A状态下棋局的胜率高于B。假设我们使用表示“X”的棋子,那么对于所有包含3个相邻“X”的状态来说,值为1,因为我们已经赢了。相反如果是三个相邻“O”,状态的值为-1(对方赢了)。假设初始时,其他所有状态的值为0。所有状态和对应的值就构成了一张表,因此这种方法也常常叫做基于表格的方法(table-based)[2]。(这里我修改了原文中的回报,因为原文的方法无法区别平局和失败)。
通过上面值函数的定义,可见要获得一个好的策略,关键是要准确地估计出每个状态的值。然后决策过程就是一个查表的过程。多数时候我们采用贪婪策略,即总是选择使下个状态值最大的下棋策略。有些时候也随机地下几步,主要是为了探索,从而准确计算各个状态下的值[2]。
我们认为后面的盘面会对前面的盘面造成影响,例如我们在胜利盘上任意去掉一个我们的子,则这些前置盘面可以通过一步导向胜利盘,因此如果我们的策略能够分析出哪个后续盘面是能胜利的并选择在对应的位置下棋使该后续盘面发生,这些盘面的 应该趋近于后一个盘面,这样我们用下式计算:
这相当于让前一个状态的v值向后一个状态的v值走一步(之所以用“走一步”的方式,是因为对手的对策可能具有随机性,设置 ,则这个操作在一定程度上能平衡后续盘面出现的概率)。这个式子将会在后续章节中更详细地解释。
每次我们选择动作的时候,我们从当前盘面出发,假设把我们的X分别放到每个空白的地方,得到一系列s’,我们找到v(s’)中最大的作为我们采取的动作,如果最大后续状态有多个,那么我们随机选择一个 ,这种做法是贪婪的,保证我们尽可能胜利。同时,我们根据上式利用v(s’)更新v(s)。

a是对手下棋前的盘面(Sa),b是对手下棋后的盘面(Sb),我们从Sb出发,可以选择多个位置下棋(虚线, Sb’),我们往往选择v(Sb’)最大的那个Sb’,也就是Sc*。注意到,在Sd时,我方选择了非最大后续状态e,这就是探索的过程,我们需要这样的过程来反向更新V(Se)的值。
由于值函数最初是我们随便初始化的,因此是不准确的,为了让各个状态的值函数都收敛到真实值,我们不能只采用贪婪的动作,我们也应该考虑其它动作,这样才能利用上面的公式计算其值函数。随着其它状态的值函数收敛,可能其它状态的值会最终超过我们原先的最好状态的值。这就是探索和利用之间的平衡。
利用Qt实现了上述过程,所实现的与上述介绍有两点差别:1. 胜利状态的值初始化为1.0,失败状态的值初始化为-1.0,其余状态初始化为0;2. 为了编程简便,反向更新的时候,我们不像树状图中的红色箭头一样跳过对方决策的状态,我们也更新对方下棋后的盘面。

每个小图右下角纵轴到顶是1.0,懒得标记;每100次对战计算一次胜率,曲线表示了RL算法与我们人造的有缺陷的算法对战胜率的收敛曲线。训练10000轮后,胜率基本在75%左右。程序上传了Github(源码)和CSDN(csdn搜索:Reinforcement Learning: An Introduction(Second Edition)第一章TicTacToe例子Qt程序)。
如果想要改变对手策略,修改gridarea.cpp中的void GridArea::aiAutoMove()即可。
程序开发环境如图:

7.总结
强化学习发展过程的三条独立线索:animal learning中起源的通过反复试验的线、最优控制起源的值函数和动态规划、时间差分的离散问题的线(tic-tac-toe)。
原文这里介绍了较详细的RL发展历史,有兴趣可以看原文。
8.附:致歉
之前搞过一个新浪博客,没发多少篇东西就莫名其妙被封掉了;说实话对这个事情很失望。后来,在一年多前开通了CSDN,发现CSDN确实友好,很方便写点技术类的东西,就尝试发了两篇文章,是关于NLP的。
其实之前发的东西主要源于自己上的某门课,当时一冲动就顺便写了写,然而NLP并不是我主要学习的方向,后来几乎就一点都不接触了,因此虽然发现博客下面有一些提问,我也注意到了,却没有回复,主要是出于个人水平的原因,怕误导别人。
这一年多也没写文章,确实是比较忙,再加上突然发现印象笔记这个东西,就去印象笔记上写东西去了(也搞了200篇笔记了)。现在觉得,还是应该把自己学习的一些资料和其他人分享,这样既督促自己认真对待每一篇笔记,也是一个向大家请教的平台。
计划这段时间把这一两年积累的一些可能有价值的材料上传CSDN和Github,也算作是为那些个人没能力回复的兄弟们做点事情了(可能对你们没什么用><)。
参考文献
[1].(书在这儿)https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf
https://drive.google.com/file/d/1opPSz5AZ_kVa1uWOdOiveNiBFiEOHjkG/view
[2].(参考的知乎专栏)
https://zhuanlan.zhihu.com/c_1060499676423471104
https://zhuanlan.zhihu.com/p/31492025
