文章目录
1、简介
在使用Python爬虫时,需要模拟发起网络请求,主要用到的库有requests库和python内置的urllib库,一般建议使用requests,它是对urllib的再次封装。
urllib、urllib2、urllib3均能通过网络访问互联网上的资源文件。
- urllib:Python2和Python3内置的网络请求库,Python3的urllib实际是Python2版本中urllib和urllib2的合并。
- urllib2:它只存在于Python2版本的内置库中,功能与urllib基本类似,主要上urllib的增强 。
- urllib3:Python2和Python3均可以使用,但这不是标准库,需要使用pip安装使用,urllib3提供了线程安全池和文件post等。urllib3 是一个功能强大、用户友好的 Python HTTP客户端。大部分 Python 生态系统已经在使用 urllib3,你也应该这样做。urllib3带来了Python中标准库缺少的许多关键功能。
补充:在Python2中urllib和urllib2一般搭配使用的。urllib具有urllib2没有的功能,而urllib2具有urllib没有的功能。
2、功能介绍
2.1 urllib库和requests库
- (1)urllib库
urllib库的response对象是先创建http的request对象,装载到reques.urlopen里完成http请求。
返回的是http的rresponse对象,实际上是html属性。使用.read().decode()解码后转化成了str字符串类型,decode解码后中文字符能够显示出来。
from urllib import request
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36'
}
url = "http://www.baidu.com"
req = request.Request(url, headers=headers)
response = request.urlopen(req)
print(response)
data = response.read().decode()
print(data)
- (2)requests库
requests库调用是requests.get方法传入url和参数,返回的对象是Response对象,打印出来是显示响应状态码。
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/8.9 Mobile Safari/537.36"
}
url = "http://www.baidu.com"
response = requests.get(url, params=wd, headers=headers)
text = response.text
content = response.content
print(text)
print(content)
- (3)对比结果
Python爬虫时,更建议用requests库。因为requests比urllib更为便捷,requests可以直接构造get,post请求并发起,而urllib.request只能先构造get,post请求,再发起。
2.2 urllib库的模块
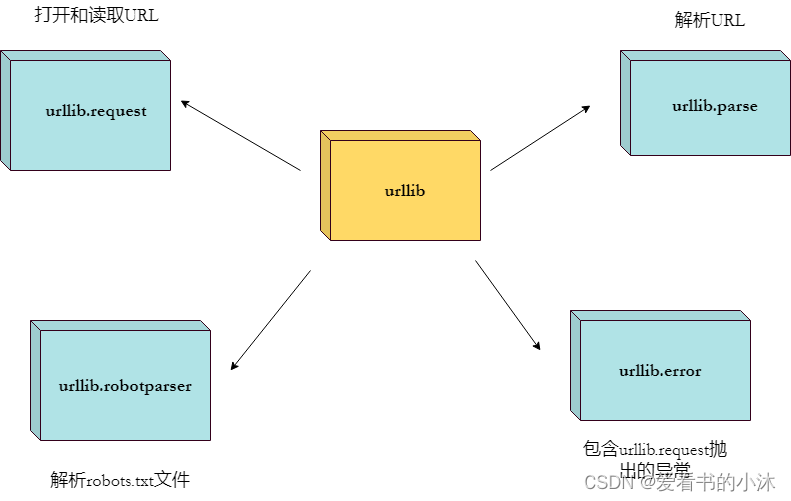
- urllib 包 包含以下几个模块:
urllib.request - 打开和读取 URL。
urllib.error - 包含 urllib.request 抛出的异常。
urllib.parse - 解析 URL。
urllib.robotparser - 解析 robots.txt 文件。
https://docs.python.org/3/library/urllib.html
2.2.1 urllib.request
urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。
urllib.request 可以模拟浏览器的一个请求发起过程。
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
- 使用 urlopen 打开一个 URL:
from urllib.request import urlopen
myURL = urlopen("https://api.money.126.net/data/feed/1000002,1000001,1000881,0601398,money.api")
print(myURL.read())
#print(myURL.read(300)) # 读取指定长度的文本
#print(myURL.readline()) # 读取一行内容
#lines = myURL.readlines() # 读取文件的全部内容,它会把读取的内容赋值给一个列表变量。
2.2.2 urllib.error
urllib.error 模块为 urllib.request 所引发的异常定义了异常类,基础异常类是 URLError。
urllib.error 包含了两个方法,URLError 和 HTTPError。
import urllib.request
import urllib.error
myURL1 = urllib.request.urlopen("https://www.baidu.com/")
print(myURL1.getcode()) # 200
try:
myURL2 = urllib.request.urlopen("https://www.baidu.com/no.html")
except urllib.error.HTTPError as e:
if e.code == 404:
print(404) # 404
2.2.3 urllib.parse
urllib.parse 用于解析 URL,格式如下:
urllib.parse.urlparse(urlstring, scheme=‘’, allow_fragments=True)
from urllib.parse import urlparse
o = urlparse("https://api.money.126.net/data/feed/1000002,1000001,1000881,0601398,money.api")
print(o)
2.2.4 urllib.robotparser
urllib.robotparser 用于解析 robots.txt 文件。
robots.txt(统一小写)是一种存放于网站根目录下的 robots 协议,它通常用于告诉搜索引擎对网站的抓取规则。
import urllib.robotparser
rp = urllib.robotparser.RobotFileParser()
rp.set_url("http://www.musi-cal.com/robots.txt")
rp.read()
rrate = rp.request_rate("*")
print(rrate.requests)
print(rrate.seconds)
print(rp.crawl_delay("*"))
print(rp.can_fetch("*", "http://www.musi-cal.com/cgi-bin/search?city=San+Francisco"))
print(rp.can_fetch("*", "http://www.musi-cal.com/"))
2.3 入门示例
- urllib发起GET请求
from urllib import request
res = request.urlopen("http://httpbin.org/get")
print(res.read().decode()) # red()方法读取的数据是bytes的二进制格式,需要解码
- urllib发起POST请求
from urllib import request
res = request.urlopen("http://httpbin.org/post", data=b'hello=world')
print(res.read().decode())
- urllib为请求添加Headers
from urllib import request
url = "http://httpbin.org/get"
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'}
req = request.Request(url=url, headers=headers) # 传递的Request对象
res = request.urlopen(req)
print(res.read().decode())
3、代码示例
3.1 urlib 获取网页(1)
将 url 对应的网页下载到本地
# -*- coding: UTF-8 -*-
import urllib.request
def get_html(url):
# TODO(You): 请在此实现代码
return html
if __name__ == '__main__':
url = "http://www.baidu.com"
html = get_html(url)
print(html)
def get_html(url):
response = urllib.request.urlopen(url)
buff = response.read()
html = buff.decode("utf8")
return html
3.2 urlib 获取网页(2) with header
# -*- coding: UTF-8 -*-
import urllib.request
def get_html(url, headers):
req = urllib.request.Request(url)
for key in headers:
req.add_header(key, headers[key])
response = urllib.request.urlopen(req)
buff = response.read()
html = buff.decode("utf8")
return html
if __name__ == '__main__':
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36"
}
url = "http://www.baidu.com"
html = get_html(url, headers)
print(html)
3.3 urllib post请求
- 一个Post请求的例子:
# -*- coding: UTF-8 -*-
import urllib.request
import urllib.parse
def get_response(url, data):
data = bytes(urllib.parse.urlencode(data), encoding='utf8')
response = urllib.request.urlopen(
url, data
)
buff = response.read()
result = buff.decode("utf8")
return result
if __name__ == '__main__':
data = {
"key1": "value1",
"key2": "value2"
}
url = "http://httpbin.org/post"
html = get_response(url, data)
print(html)
- 另一个Post请求的例子:
import urllib.request as rq
import urllib.parse as ps
url='https://www.python.org/search/'
dictionary = {
'q': 'urllib' }
data = ps.urlencode(dictionary)
data = data.encode('utf-8')
req = rq.Request(url,data)
res = rq.urlopen(req)
print(res.read())
4、urllib3相关示例
- 安装urllib3库:
# https://pypi.org/project/urllib3/
python -m pip install urllib3
- urllib3发起GET请求
import urllib3
http = urllib3.PoolManager() # 线程池生成请求
res = http.request('GET', 'http://httpbin.org/get')
print(res.data.decode())
- urllib3发起POST请求
import urllib3
http = urllib3.PoolManager() # 线程池生成请求
res = http.request('POST', 'http://httpbin.org/post', fields={
'hello': 'world'})
print(res.data.decode())
- urllib3设置headers
headers = {
'X-Something': 'value'}
res = http.request('POST', 'http://httpbin.org/post', headers=headers, fields={
'hello': 'world'})
5、Chrome调试
Chrome 是由 Google 开发的免费网页浏览器,对于前端开发来说(尤其是调试代码)非常方便。
在 Chrome 浏览器中可以通过如下快捷键打开开发者界面:
- (1)按下快捷键: F12
- (2)按下快捷键: Ctrl+Shift+i
- (3)右击页面,选择"检查"来开启开发者工具。

调试工具打开如下,最常用的调试功能为:
Element 标签页: 用于查看和编辑当前页面中的 HTML 和 CSS 元素。
Console 标签页:用于显示脚本中所输出的调试信息,或运行测试脚本等。
Source 标签页:用于查看和调试当前页面所加载的脚本的源文件。
Network 标签页:用于查看 HTTP 请求的详细信息,如请求头、响应头及返回内容等。
结语
如果您觉得该方法或代码有一点点用处,可以给作者点个赞,或打赏杯咖啡;╮( ̄▽ ̄)╭
如果您感觉方法或代码不咋地//(ㄒoㄒ)//,就在评论处留言,作者继续改进;o_O???
如果您需要相关功能的代码定制化开发,可以留言私信作者;(✿◡‿◡)
感谢各位大佬童鞋们的支持!( ´ ▽´ )ノ ( ´ ▽´)っ!!!