Note 7 - 近似动态规划 Approximate Dynamic Programming
7. 近似动态规划 (Approximate Dynamic Programming)
在前面的章节中,我们研究了经典DP算法的理论基础和它们的高级变化。尽管这些算法具有良好的理论特性,但在许多实际应用中,这些算法仍然是低效的,甚至是不切实际的。这种现象主要是由于维数的诅咒,它在存储或计算方面都会造成潜在的高负担。SDM的一个具有挑战性的应用是边缘计算(edge computing),其中计算和数据存储被推到数据源上。显然,对于任何经典的DP算法来说,边缘的计算能力和存储容量都是非常有限的。更具体地说,本节重点讨论维度诅咒的存储角度。

图7:边缘计算应用。
7.1 近似架构 (Approximation architectures)
总成本函数近似的主要思想是构建一个相对低维的参数化空间来近似总成本函数。具体来说,一个参数化的总成本函数近似器将状态 x ∈ X x\in\mathcal{X} x∈X映射为总成本函数估计值,即。
J : X × R m → R , ( x , θ ) ↦ J ( x , θ ) (7.1) J: \mathcal{X} \times \mathbb{R}^{m} \rightarrow \mathbb{R}, \quad(x, \theta) \mapsto J(x, \theta) \tag{7.1} J:X×Rm→R,(x,θ)↦J(x,θ)(7.1)
其中 θ \theta θ是近似结构的参数(向量)。通过这样的结构,目的是将参数空间的维度从 K K K的向量空间减少到 m m m的向量空间, m ≪ K m\ll K m≪K,即减轻维度的诅咒。值得注意的是,实际的总成本函数不一定位于这样的近似空间中。
7.1.1 线性函数近似 (Linear Function Approximation,LFA)
总成本函数近似的一个简单框架是线性函数近似(LFA)。它的目的是构建一组实值特征,这些特征捕捉所有状态的属性,即。
ϕ : X → R m , x ↦ ϕ ( x ) (7.2) \phi: \mathcal{X} \rightarrow \mathbb{R}^{m}, \quad x \mapsto \phi(x) \tag{7.2} ϕ:X→Rm,x↦ϕ(x)(7.2)
然后将总成本函数近似为这些特征的线性组合,即:
J l : X × R m → R , ( x , θ ) ↦ θ ⊤ ϕ ( x ) (7.3) J_{l}: \mathcal{X} \times \mathbb{R}^{m} \rightarrow \mathbb{R}, \quad(x, \theta) \mapsto \theta^{\top} \phi(x) \tag{7.3} Jl:X×Rm→R,(x,θ)↦θ⊤ϕ(x)(7.3)
通过将所有特征向量收集到一个矩阵中,即
Φ ( x ) : = [ ϕ ( x 1 ) , … , ϕ ( x K ) ] ∈ R m × K , (7.4) \Phi(x):=\left[\phi\left(x_{1}\right), \ldots, \phi\left(x_{K}\right)\right] \in \mathbb{R}^{m \times K}, \tag{7.4} Φ(x):=[ϕ(x1),…,ϕ(xK)]∈Rm×K,(7.4)
我们可以把近似总成本函数的空间确定为 Φ ( x ) \Phi(x) Φ(x)的行的张成,即
J l : = { Φ ( x ) ⊤ h ∣ x ∈ X , h ∈ R m } ⊂ R K (7.5) \mathcal{J}_{l}:=\left\{\Phi(x)^{\top} h \mid x \in \mathcal{X}, h \in \mathbb{R}^{m}\right\} \subset \mathbb{R}^{K} \tag{7.5} Jl:={
Φ(x)⊤h∣x∈X,h∈Rm}⊂RK(7.5)
当然,假设所有的特征向量都是不同的,所以总成本函数的线性近似仍可区分对于诱导性策略。为了确保每个近似值 J ∈ J l J\in\mathcal{J}_{l} J∈Jl都由 h ∈ R m h\in\mathbb{R}^{m} h∈Rm相对于指定的特征矩阵 ϕ ( x ) \phi(x) ϕ(x)所代表,线性映射 h ↦ Φ ( x ) ⊤ h h \mapsto \Phi(x)^{\top} h h↦Φ(x)⊤h需要是单射(一对一映射)。因此,我们假设特征矩阵是满秩的。
Assumption 7.1 特征矩阵的秩
特征矩阵 Φ ( x ) ∈ R m × K \Phi(x)\in \mathbb{R}^{m \times K} Φ(x)∈Rm×K 的秩是 m m m。
有趣的是,经典的DP算法可以被容易地建模为一个线性总成本函数近似。让我们把表格查询特征(tabular lookup features)定义为
ϕ table ( x ) : = ( 1 x 1 ( x ) , … , 1 x K ( x ) ) ⊤ , (7.6) \phi^{\text {table }}(x):=\left(\mathbf{1}_{x_{1}}(x), \ldots, \mathbf{1}_{x_{K}}(x)\right)^{\top}, \tag{7.6} ϕtable (x):=(1x1(x),…,1xK(x))⊤,(7.6)
其中指示函数 1 x i : X → { 0 , 1 } 1_{x_{i}}: \mathcal{X} \rightarrow\{0,1\} 1xi:X→{
0,1} 被定义为
1 x i ( x ) : = { 1 , if x = x i 0 , otherwise (7.7) \mathbf{1}_{x_{i}}(x):= \begin{cases}1, & \text { if } x=x_{i} \\ 0, & \text { otherwise }\end{cases} \tag{7.7} 1xi(x):={
1,0, if x=xi otherwise (7.7)
尽管MDP的模型假定状态空间的有限性是 D P \mathrm{DP} DP和RL求解的基础,但许多工程问题并没有这种连续状态空间的便利,如机器人技术。为了使DP或RL方法在解决具有连续状态空间的MDP问题时都是可行的,建立一种构建线性总成本函数近似空间的机制具有很大的实际用途。最流行的技术之一是瓦片编码(tile coding),如图8所示。
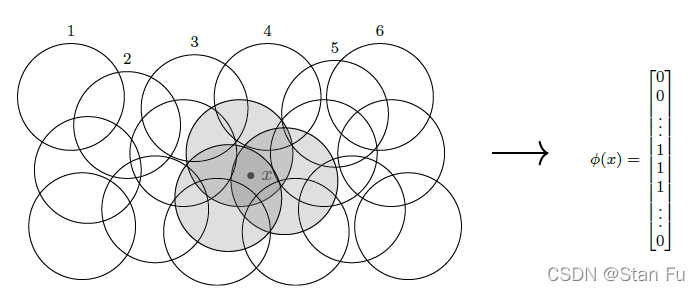
图8:瓦片编码。对于具有连续状态空间的MDP问题,每个圆盘代表一个用于生成特征的局部指标函数。
具体来说,瓦片编码的主要思想是假设相邻的状态具有相同的重要性,因此总成本函数。让我们定义连续状态空间 X \mathcal{X} X中的开放子集 N k ∈ X \mathcal{N}_{k} \in \mathcal{X} Nk∈X, for k = 1 , … , τ k=1, \ldots, \tau k=1,…,τ。 我们假设这些开放子集的联合覆盖了状态空间,即。
⋃ k = 1 τ N k = X (7.8) \bigcup_{k=1}^{\tau} \mathcal{N}_{k}=\mathcal{X} \tag{7.8} k=1⋃τNk=X(7.8)
我们可以定义相同的指示函数为
1 N i ( x ) : = { 1 , if x ∈ N i 0 , otherwise \mathbf{1}_{\mathcal{N}_{i}}(x):= \begin{cases}1, & \text { if } x \in \mathcal{N}_{i} \\ 0, & \text { otherwise }\end{cases} 1Ni(x):={ 1,0, if x∈Ni otherwise
然后,可以通过以下方式构建一个瓦片编码特征向量
ϕ tile ( x ) : = ( 1 N 1 ( x ) , … , 1 N τ ( x ) ) ⊤ . \phi^{\text {tile }}(x):=\left(\mathbf{1}_{\mathcal{N}_{1}}(x), \ldots, \mathbf{1}_{\mathcal{N}_{\tau}}(x)\right)^{\top} . ϕtile (x):=(1N1(x),…,1Nτ(x))⊤.
有了线性总成本函数近似的构造,然后就可以直接构造经典的DP算法了。
7.1.2 神经网络函数逼近 (Neural Function Approximation)
深度强化学习(DRL)的最新发展表明,神经网络(NNs)在解决具有大型或连续状态空间的挑战性RL问题方面具有卓越的性能。历史上,神经网络(NN)被用来近似总成本函数已经有几十年了。最近NN在解决模式识别、计算机视觉和语音识别等挑战性问题上的成功,进一步引发了人们对NN应用于总成本函数的努力。基于NN的总成本函数近似(NN-VFA)方法已经在许多具有挑战性的领域中证明了其卓越的性能,例如Atari游戏和围棋游戏。尽管取得了这些进展,对基于NN-VFA的算法的充分理解仍然是一个开放的问题,而且对更具挑战性的应用有着巨大的需求。
一个经典的NN由许多连接的基本计算单元组成,称为神经元,见图9,呈层状结构,如多层感知器(MLP),见图9。
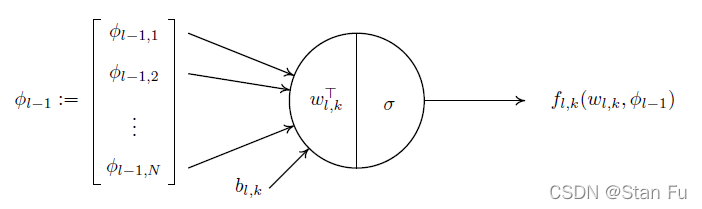
图9:单一感知器神经元的图示。
让 σ : R → R \sigma: \mathbb{R} \rightarrow \mathbb{R} σ:R→R 是一个单位激活函数,传统上它被选择为非常数、有界、连续和单调增长。常见的例子有Sigmoid函数
σ ( x ) = 1 1 + e − x , (7.9) \sigma(x)=\frac{1}{1+e^{-x}}, \tag{7.9} σ(x)=1+e−x1,(7.9)
和整流线性单元(ReLU)。
σ ( x ) = { 0 , for x ≤ 0 x , for x > 0 (7.10) \sigma(x)= \begin{cases}0, & \text { for } x \leq 0 \\ x, & \text { for } x>0\end{cases} \tag{7.10} σ(x)={ 0,x, for x≤0 for x>0(7.10)
更确切地说,让我们用 L L L表示MLP结构中的层数,用 n l n_{l} nl表示第 l l l层的处理单元数, l = 1 , … , L l=1, \ldots, L l=1,…,L。 具体来说,用 l = 0 l=0 l=0,我们指的是输入层,并设定 n 0 = K n_{0}=K n0=K, n L = 1 n_{L}=1 nL=1。这里,我们用 σ ′ : R → R \sigma^{\prime}: \mathbb{R} \rightarrow \mathbb{R} σ′:R→R 是激活函数 σ \sigma σ 的一阶导数。
对于MLP结构中的第 ( l , k ) (l, k) (l,k)个单元,指的是第 l l l层中的第 k k k个单元,我们定义相应的单元映射为
f l , k ( w l , k , ϕ l − 1 ) : = σ ( w l , k ⊤ ϕ l − 1 − b l , k ) , (7.11) f_{l, k}\left(w_{l, k}, \phi_{l-1}\right):=\sigma\left(w_{l, k}^{\top} \phi_{l-1}-b_{l, k}\right), \tag{7.11} fl,k(wl,k,ϕl−1):=σ(wl,k⊤ϕl−1−bl,k),(7.11)
其中, ϕ l − 1 ∈ R n l − 1 \phi_{l-1} \in \mathbb{R}^{n_{l-1}} ϕl−1∈Rnl−1 表示来自第 ( l − 1 ) (l-1) (l−1)层的输出, w l , k ∈ R n l − 1 w_{l, k} \in \mathbb{R}^{n_{l-1}} wl,k∈Rnl−1 和 b l , k ∈ R b_{l, k} \in \mathbb{R} bl,k∈R分别是与第 ( l , k ) (l, k) (l,k)单元相关的权重向量和偏置。请注意,一般来说,偏差 b l , k b_{l, k} bl,k是一个与虚拟单元相关的自由变量。然而,通过下面的分析,为了表述方便,我们把它固定为公式(7.11)中的一个常数标量。然后,我们可以通过堆叠该层的所有单元映射,简单地定义第 l l l层映射为
f l ( W l , ϕ l − 1 ) : = [ f l , 1 ( w l , 1 , ϕ l − 1 ) , … , f l , n l ( w l , n l , ϕ l − 1 ) ] ⊤ (7.12) f_{l}\left(W_{l}, \phi_{l-1}\right):=\left[f_{l, 1}\left(w_{l, 1}, \phi_{l-1}\right), \ldots, f_{l, n_{l}}\left(w_{l, n_{l}}, \phi_{l-1}\right)\right]^{\top} \tag{7.12} fl(Wl,ϕl−1):=[fl,1(wl,1,ϕl−1),…,fl,nl(wl,nl,ϕl−1)]⊤(7.12)
其中 W l : = [ w l , 1 , … , w l , n l ] ∈ R n l − 1 × n l W_{l}:=\left[w_{l, 1}, \ldots, w_{l, n_{l}}\right] \in \mathbb{R}^{n_{l-1} \times n_{l}} Wl:=[wl,1,…,wl,nl]∈Rnl−1×nl 是第 l l l个权重矩阵。具体来说,让我们用 ϕ 0 ∈ R K \phi_{0} \in \mathbb{R}^{K} ϕ0∈RK表示输入,那么第 l l l层的输出被递归定义为 ϕ l : = f l ( W l , ϕ l − 1 ) \phi_{l}:=f_{l}\left(W_{l}, \phi_{l-1}\right) ϕl:=fl(Wl,ϕl−1) 注意,MLP的最后一层通常采用自映射作为激活函数,即 ϕ L : = W L ⊤ ϕ L − 1 \phi_{L}:=W_{L}^{\top} \phi_{L-1} ϕL:=WL⊤ϕL−1。最后,用 W : = R K × n 1 × … × R n L − 1 \mathcal{W}:=\mathbb{R}^{K \times n_{1}} \times \ldots \times \mathbb{R}^{n_{L-1}} W:=RK×n1×…×RnL−1来表示MLP中所有参数矩阵的集合。我们将所有的层间映射组合起来,定义整个MLP网络的映射
f : W × R K → R , ( W , x ) ↦ f L ( W L , ⋅ ) ∘ … ∘ f 1 ( W 1 , x ) (7.13) f: \mathcal{W} \times \mathbb{R}^{K} \rightarrow \mathbb{R}, \quad(\mathbf{W}, x) \mapsto f_{L}\left(W_{L}, \cdot\right) \circ \ldots \circ f_{1}\left(W_{1}, x\right) \tag{7.13} f:W×RK→R,(W,x)↦fL(WL,⋅)∘…∘f1(W1,x)(7.13)
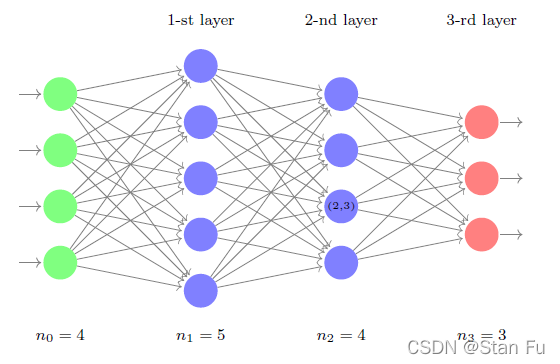
图10:一个有两个隐藏层的MLP。
有了这样的结构,我们可以定义一组参数化的总成本函数,由一个给定的MLP架构规定为
F : = { f ( W , ⋅ ) : R K → R ∣ W ∈ W } (7.14) \mathcal{F}:=\left\{f(\mathbf{W}, \cdot): \mathbb{R}^{K} \rightarrow \mathbb{R} \mid \mathbf{W} \in \mathcal{W}\right\} \tag{7.14} F:={
f(W,⋅):RK→R∣W∈W}(7.14)
更具体地说,我们用 F ( K , n 1 , … , n L − 1 , 1 ) \mathcal{F}\left(K, n_{1}, \ldots, n_{L-1}, 1\right) F(K,n1,…,nL−1,1)来表示MLP的架构,即每层的单元数。让我们用 F x ( W ) : = f ( W , x ) F_{x}(\mathbf{W}):=f(\mathbf{W}, x) Fx(W):=f(W,x)表示状态为 x x x的MLP在 W \mathbf{W} W的评估,用 F ( x , W ) : = [ F x 1 ( W ) , … , F x K ( W ) ] ⊤ ∈ R K F(x, \mathbf{W}):=\left[F_{x_{1}}(\mathbf{W}), \ldots, F_{x_{K}}(\mathbf{W})\right]^{\top} \in \mathbb{R}^{K} F(x,W):=[Fx1(W),…,FxK(W)]⊤∈RK表示 一个近似的总成本函数,MLP的近似总成本函数集被定义为
J n : = { F ( x , W ) ∣ x ∈ X , W ∈ W } ⊂ R K (7.15) \mathcal{J}_{n}:=\{F(x, \mathbf{W}) \mid x \in \mathcal{X}, \mathbf{W} \in \mathcal{W}\} \subset \mathbb{R}^{K} \tag{7.15} Jn:={ F(x,W)∣x∈X,W∈W}⊂RK(7.15)
7.2 贝尔曼残差最小化 (Bellman Residual Minimisation )
对于正在选择的总成本函数的特定近似架构,重要的是调查质量和方法,以确定最佳总成本函数的最佳近似。
定义 7.1 最佳总成本函数的直接估计 (Direct estimate of optimal total cost function).
给定一个无限范围的MDP { X , U , p , g , γ } \{\mathcal{X}, \mathcal{U}, p, g, \gamma\} { X,U,p,g,γ},和一个封闭子集 J ⊂ R K \mathcal{J} \subset \mathbb{R}^{K} J⊂RK,那么最优总成本函数 J D J_{D} JD的直接最优估计为
J D ∈ argmin J ∈ J ∥ J − J ∗ ∥ ∞ (7.16) J_{D} \in \underset{J \in \mathcal{J}}{\operatorname{argmin}}\left\|J-J^{*}\right\|_{\infty} \tag{7.16} JD∈J∈Jargmin∥J−J∗∥∞(7.16)
解决方案 J D J_{D} JD的质量以其相关GIP的真实总成本来衡量。
Proposition 7.1 最优直接估计的约束
给定一个无限范围的MDP { X , U , p , g , γ } \{\mathcal{X}, \mathcal{U}, p, g, \gamma\} { X,U,p,g,γ}和一个封闭子集 J ⊂ R K \mathcal{J} \subset \mathbb{R}^{K} J⊂RK, J D ∈ J J_{D} \in \mathcal{J} JD∈J是 J ∗ J^{*} J∗的最优直接估计, π D \pi_{D} πD是关于 J D J_{D} JD的贪婪策略,那么我们有
∥ J π D − J ∗ ∥ ∞ ≤ 2 ( 1 + γ ) 1 − γ min J ∈ J ∥ J − J ∗ ∥ ∞ . (7.17) \left\|J^{\pi_{D}}-J^{*}\right\|_{\infty} \leq \frac{2(1+\gamma)}{1-\gamma} \min _{J \in \mathcal{J}}\left\|J-J^{*}\right\|_{\infty} . \tag{7.17} ∥JπD−J∗∥∞≤1−γ2(1+γ)J∈Jmin∥J−J∗∥∞.(7.17)
Proof.
通过应用无穷范数的三角不等式,我们可以得到
∥ T g J − J ∥ ∞ ≤ ∥ T g J − J ∗ ∥ ∞ + ∥ J ∗ − J ∥ ∞ ≤ ( 1 + γ ) ∥ J − J ∗ ∥ ∞ . (7.18) \begin{aligned} \left\|\mathrm{T}_{\mathfrak{g}} J-J\right\|_{\infty} & \leq\left\|\mathrm{T}_{\mathfrak{g}} J-J^{*}\right\|_{\infty}+\left\|J^{*}-J\right\|_{\infty} \\ & \leq(1+\gamma)\left\|J-J^{*}\right\|_{\infty} . \end{aligned} \tag{7.18} ∥TgJ−J∥∞≤∥TgJ−J∗∥∞+∥J∗−J∥∞≤(1+γ)∥J−J∗∥∞.(7.18)
根据 Proposition 4.2 4.2 4.2有
∥ J π D − J ∗ ∥ ∞ ≤ 2 1 − γ ∥ T g J D − J D ∥ ∞ ≤ 2 ( 1 + γ ) 1 − γ ∥ J D − J ∗ ∥ ∞ = 2 ( 1 + γ ) 1 − γ min J ∈ J ∥ J − J ∗ ∥ ∞ . (7.19) \begin{aligned} \left\|J^{\pi_{D}}-J^{*}\right\|_{\infty} & \leq \frac{2}{1-\gamma}\left\|\mathrm{T}_{\mathfrak{g}} J_{D}-J_{D}\right\|_{\infty} \\ & \leq \frac{2(1+\gamma)}{1-\gamma}\left\|J_{D}-J^{*}\right\|_{\infty} \\ &=\frac{2(1+\gamma)}{1-\gamma} \min _{J \in \mathcal{J}}\left\|J-J^{*}\right\|_{\infty} . \end{aligned} \tag{7.19} ∥JπD−J∗∥∞≤1−γ2∥TgJD−JD∥∞≤1−γ2(1+γ)∥JD−J∗∥∞=1−γ2(1+γ)J∈Jmin∥J−J∗∥∞.(7.19)
即证。
很明显,这种对最佳总成本的直接评估只是理论上的讨论。我们需要开发更可行的机制来寻找最佳近似值。定理3.1中所示的最佳贝尔曼算子的充分和必要条件表明,使用最佳贝尔曼算子下的残余误差来估计最佳总成本函数的可能措施如下
定义 7.2 最佳总成本函数的间接估计 (Indirect estimate of optimal total cost function).
给定一个无限范围的MDP X , U , p , g , γ {\mathcal{X}, \mathcal{U}, p, g, \gamma} X,U,p,g,γ,和一个封闭子集 J ⊂ R K \mathcal{J} \subset \mathbb{R}^{K} J⊂RK,那么最优总成本函数 J B J_{B} JB的最优间接估计为
J B ∈ argmin J ∈ J ∥ T g J − J ∥ ∞ (7.20) J_{B} \in \underset{J \in \mathcal{J}}{\operatorname{argmin}}\left\|\mathrm{T}_{\mathfrak{g}} J-J\right\|_{\infty} \tag{7.20} JB∈J∈Jargmin∥TgJ−J∥∞(7.20)
注意, J J J与 T g J \mathrm{T}_{\mathfrak{g}} J TgJ之间的差值的最大范数被称为贝尔曼残差(Bellman residual) 。
Proposition 7.2 最优间接估计的约束
给定一个无限范围的MDP { X , U , p , g , γ } \{\mathcal{X}, \mathcal{U}, p, g, \gamma\} { X,U,p,g,γ},并让 J B ∈ J J_{B} \in \mathcal{J} JB∈J是 J ∗ J^{*} J∗的最优间接估计, π B \pi_{B} πB是关于 J B J_{B} JB的贪婪策略。那么我们有
∥ J π B − J ∗ ∥ ∞ ≤ 2 ( 1 + γ ) 1 − γ min J ∈ J ∥ J − J ∗ ∥ ∞ . (7.21) \left\|J^{\pi_{B}}-J^{*}\right\|_{\infty} \leq \frac{2(1+\gamma)}{1-\gamma} \min _{J \in \mathcal{J}}\left\|J-J^{*}\right\|_{\infty} . \tag{7.21} ∥JπB−J∗∥∞≤1−γ2(1+γ)J∈Jmin∥J−J∗∥∞.(7.21)
Proof.
通过应用无穷范数的三角不等式,我们可以得到
∥ T g J − J ∥ ∞ ≤ ∥ T g J − J ∗ ∥ ∞ + ∥ J ∗ − J ∥ ∞ ≤ ( 1 + γ ) ∥ J − J ∗ ∥ ∞ . (7.22) \begin{aligned} \left\|\mathrm{T}_{\mathfrak{g}} J-J\right\|_{\infty} & \leq\left\|\mathrm{T}_{\mathfrak{g}} J-J^{*}\right\|_{\infty}+\left\|J^{*}-J\right\|_{\infty} \\ & \leq(1+\gamma)\left\|J-J^{*}\right\|_{\infty} . \end{aligned} \tag{7.22} ∥TgJ−J∥∞≤∥TgJ−J∗∥∞+∥J∗−J∥∞≤(1+γ)∥J−J∗∥∞.(7.22)
直接的有
∥ T g J B − J B ∥ ∞ = min J ∈ J ∥ T g J − J ∥ ∞ ≤ ( 1 + γ ) min J ∈ J ∥ J − J ∗ ∥ ∞ . (7.23) \begin{aligned} \left\|\mathrm{T}_{\mathfrak{g}} J_{B}-J_{B}\right\|_{\infty} &=\min _{J \in \mathcal{J}}\left\|\mathrm{T}_{\mathfrak{g}} J-J\right\|_{\infty} \\ & \leq(1+\gamma) \min _{J \in \mathcal{J}}\left\|J-J^{*}\right\|_{\infty} . \end{aligned} \tag{7.23} ∥TgJB−JB∥∞=J∈Jmin∥TgJ−J∥∞≤(1+γ)J∈Jmin∥J−J∗∥∞.(7.23)
该结果由命题4.2得出。
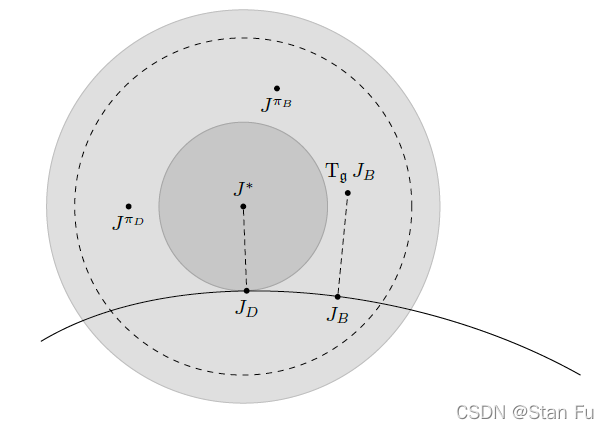
图11:参数化总成本近似的误差界限。
有趣的是,如Propositions 7.1和7.2所示,直接和间接方法所提供的误差界限是相等的。因此,利用贝尔曼残差最小化作为计算工具来估计最优总成本是安全的。另一个有趣的观察表明,只有当最优总成本位于给定的近似集时,两个误差界线才会变成零。显然,来自命题4.3的结果确保了当近似空间被适当构建时,GIP π B \pi_{B} πB可以是最优的。
Corollary 7.1 最优策略 π B \pi_{B} πB的充分不必要约束
给定一个无限范围的MDP X , U , p , g , γ {\mathcal{X}, \mathcal{U}, p, g, \gamma} X,U,p,g,γ,并让 J B ∈ J J_{B} \in \mathcal{J} JB∈J是 J ∗ J^{*} J∗的最优间接估计, π B \pi_{B} πB是关于 J B J_{B} JB的贪婪策略,最优总成本和任何非最优总成本之间的差距由 ρ : = min π ∉ P d m ∗ ∥ J π − J ∗ ∥ ∞ > 0 \rho:=\min _{\pi \notin \mathfrak{P}_{d m}^{*}}\left\|J^{\pi}-J^{*}\right\|_{\infty}>0 ρ:=minπ∈/Pdm∗∥Jπ−J∗∥∞>0定义。 如果满足以下条件。
min J ∈ J ∥ J − J ∗ ∥ ∞ ≤ ρ ( 1 − γ ) 2 ( 1 + γ ) (7.24) \min _{J \in \mathcal{J}}\left\|J-J^{*}\right\|_{\infty} \leq \frac{\rho(1-\gamma)}{2(1+\gamma)} \tag{7.24} J∈Jmin∥J−J∗∥∞≤2(1+γ)ρ(1−γ)(7.24)
那么 π B \pi_{B} πB 就是最优的。
7.3 近似价值迭代 (Approximate Value Iteration)
很明显,公式(7.20)中给出的上述贝尔曼残差是很难优化的,特别是由于 T g \mathrm{T}_{\mathfrak{g}} Tg的评估而涉及的离散优化。一个实际的解决方案是采用VI的过程,即在给定的近似架构中对一步最优Bellman算子进行近似评估。
让我们采用线性函数近似架构,让 J k = Φ ⊤ θ k J_{k}=\Phi^{\top} \theta_{k} Jk=Φ⊤θk是最佳总成本函数的估计。最佳贝尔曼算子 T g \mathrm{T}_{\mathrm{g}} Tg对 J k J_{k} Jk的一次应用不一定位于同一个子空间 J \mathcal{J} J中,如图12所描述。

图12:拟合值迭代算法。从总成本函数 J k J_{k} Jk的第 k k k次估计开始,应用最佳Bellman算子 T g J k \mathrm{T}_{\mathfrak{g}} J_{k} TgJk。
为了将其结果 T g J k \mathrm{T}_{\mathfrak{g}} J_{k} TgJk带回 J k J_{k} Jk回到近似空间 J \mathcal{J} J,我们需要应用一个与无穷范数相关的适当的正交投影。具体来说,我们有如下更新规则
J k + 1 = Π ∞ T g J k (7.25) J_{k+1}=\Pi_{\infty} \mathrm{T}_{\mathfrak{g}} J_{k} \tag{7.25} Jk+1=Π∞TgJk(7.25)
其中 Π ∞ \Pi_{\infty} Π∞是关于无穷大准则的正交投影
Π ∞ ( J ) = Φ ⊤ argmin θ ∈ R m ∥ J − Φ ⊤ θ ∥ ∞ . (7.26) \Pi_{\infty}(J)=\Phi^{\top} \underset{\theta \in \mathbb{R}^{m}}{\operatorname{argmin}}\left\|J-\Phi^{\top} \theta\right\|_{\infty} . \tag{7.26} Π∞(J)=Φ⊤θ∈Rmargmin∥∥J−Φ⊤θ∥∥∞.(7.26)
这种投影VI算法被称为拟合VI算法(fitted VI algorithm) 。可以证明,拟合VI收敛到一个唯一的固定点。不幸的是,解决无穷大规范下的最小化问题在数值上是不可行的。为了缓解这种困难,我们可以采用范数的等价性来开发一种数值上可行的算法。
众所周知,对于一个给定的 x ∈ R m x\in\mathbb{R}^{m} x∈Rm,以下关系成立
∥ x ∥ ∞ ≤ ∥ x ∥ 2 (7.27) \|x\|_{\infty} \leq\|x\|_{2} \tag{7.27} ∥x∥∞≤∥x∥2(7.27)
那么,一个近似的VI步可以被定义为
J k + 1 ∈ argmin J ∈ J ∥ J − T g J k ∥ 2 2 . (7.28) J_{k+1} \in \underset{J \in \mathcal{J}}{\operatorname{argmin}}\left\|J-\mathrm{T}_{\mathfrak{g}} J_{k}\right\|_{2}^{2} . \tag{7.28} Jk+1∈J∈Jargmin∥J−TgJk∥22.(7.28)
由于我们局限于一个LFA架构,所以很容易采用正交投影的解决方案。让我们定义 Π : = Φ ⊤ ( Φ Φ ⊤ ) − 1 Φ \Pi:=\Phi^{\top}\left(\Phi \Phi^{\top}\right)^{-1} \Phi Π:=Φ⊤(ΦΦ⊤)−1Φ,我们可以像Algorithm 9那样直接构建一个具有LFA的近似VI。

需要注意的是,Algorithm 9不能保证收敛性,这是因为组成的操作符 ( Π T g ) : R K → R K \left(\Pi T_{\mathfrak{g}}\right): \mathbb{R}^{K} \rightarrow \mathbb{R}^{K} (ΠTg):RK→RK对于 ∣ ⋅ ∥ 2 |\cdot\|_{2} ∣⋅∥2或 ∣ ⋅ ∥ ∞ |\cdot\|_{\infty} ∣⋅∥∞来说都不是一个收缩。这种现象在近似DP的背景下被称为范数不匹配(norm mismatch) 。
在本节的其余部分,我们研究近似VI的通用框架的收敛性。对于一个给定的估计值 J k J_{k} Jk,一个近似的VI步骤被计算为找到一个新的估计值,但要达到一定的误差,如下面的不等式,并对所有 k = 0 , 1 , … , ∞ k=0,1, \ldots, \infty k=0,1,…,∞ 进行计算
∥ J k + 1 − T g J k ∥ ∞ ≤ δ . (7.29) \left\|J_{k+1}-\mathrm{T}_{\mathfrak{g}} J_{k}\right\|_{\infty} \leq \delta . \tag{7.29} ∥Jk+1−TgJk∥∞≤δ.(7.29)
在这里,可以用范数之间的等价关系来指定误差界限 δ \delta δ,即:
∥ J k + 1 − T g J k ∥ ∞ ≤ ∥ J k + 1 − T g J k ∥ 2 . (7.30) \left\|J_{k+1}-\mathrm{T}_{\mathfrak{g}} J_{k}\right\|_{\infty} \leq\left\|J_{k+1}-\mathrm{T}_{\mathfrak{g}} J_{k}\right\|_{2} . \tag{7.30} ∥Jk+1−TgJk∥∞≤∥Jk+1−TgJk∥2.(7.30)
图13说明了一个通用AVI算法的基本思路。
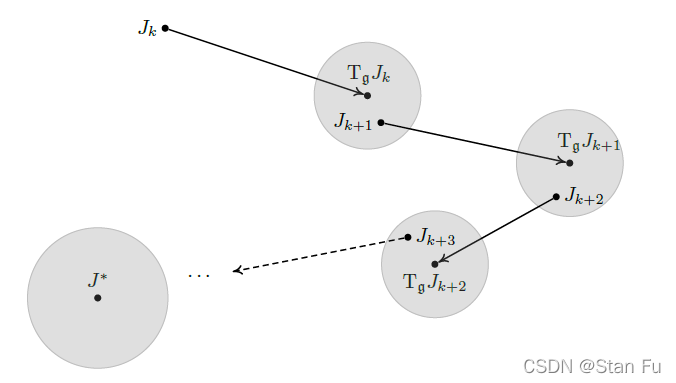
图13:近似值迭代算法。这里,总成本函数估计值周围的每个圆盘象征着总成本函数近似的误差容限。
在下面的Proposition 中,我们从估计值和最佳总成本函数之间的误差或差异方面来研究其性能。
Proposition 7.3 近似VI算法的误差界限 (Error bounds for approximate VI algorithm)
给定一个无限范围的MDP { X , U , p , g , γ } \{\mathcal{X}, \mathcal{U}, p, g, \gamma\} { X,U,p,g,γ},由近似 V I VI VI算法产生的 J k J_{k} Jk序列满足以下不等式
lim k → ∞ ∥ J k − J ∗ ∥ ∞ ≤ δ 1 − γ (7.31) \lim _{k \rightarrow \infty}\left\|J_{k}-J^{*}\right\|_{\infty} \leq \frac{\delta}{1-\gamma} \tag{7.31} k→∞lim∥Jk−J∗∥∞≤1−γδ(7.31)
Proof.
定义 J 0 ∈ R K J_{0} \in \mathbb{R}^{K} J0∈RK 是总成本函数的初始估计。我们可以将无穷范数的三角形不等式应用于近似VI的第 k k k输出与精确VI算子的第 k k k输出之间的差值,如下所示
∥ J k − T g k J 0 ∥ ∞ = ∥ J k − T g J k − 1 + T g J k − 1 − T g 2 J k − 2 + … … − T g k − 1 J 1 + T g k − 1 J 1 − T g k J 0 ∥ ∞ ≤ ∥ J k − T g J k − 1 ∥ ∞ + ∥ T g J k − 1 − T g 2 J k − 2 ∥ ∞ + ∥ T g k − 1 J 1 − T g k J 0 ∥ ∞ ≤ δ + γ δ + … + γ k − 1 δ , (7.32) \begin{aligned} \left\|J_{k}-\mathrm{T}_{\mathfrak{g}}^{k} J_{0}\right\|_{\infty}=& \| J_{k}-\mathrm{T}_{\mathfrak{g}} J_{k-1}+\mathrm{T}_{\mathfrak{g}} J_{k-1}-\mathrm{T}_{\mathfrak{g}}^{2} J_{k-2}+\ldots \\ & \ldots-\mathrm{T}_{\mathfrak{g}}^{k-1} J_{1}+\mathrm{T}_{\mathfrak{g}}^{k-1} J_{1}-\mathrm{T}_{\mathfrak{g}}^{k} J_{0} \|_{\infty} \\ \leq &\left\|J_{k}-\mathrm{T}_{\mathfrak{g}} J_{k-1}\right\|_{\infty}+\left\|\mathrm{T}_{\mathfrak{g}} J_{k-1}-\mathrm{T}_{\mathfrak{g}}^{2} J_{k-2}\right\|_{\infty}+\left\|\mathrm{T}_{\mathfrak{g}}^{k-1} J_{1}-\mathrm{T}_{\mathfrak{g}}^{k} J_{0}\right\|_{\infty} \\ \leq & \delta+\gamma \delta+\ldots+\gamma^{k-1} \delta, \end{aligned} \tag{7.32} ∥∥Jk−TgkJ0∥∥∞=≤≤∥Jk−TgJk−1+TgJk−1−Tg2Jk−2+……−Tgk−1J1+Tgk−1J1−TgkJ0∥∞∥Jk−TgJk−1∥∞+∥∥TgJk−1−Tg2Jk−2∥∥∞+∥∥Tgk−1J1−TgkJ0∥∥∞δ+γδ+…+γk−1δ,(7.32)
其中第二个不等式是由于最佳贝尔曼算子的收缩特性 T g \mathrm{T}_{\mathfrak{g}} Tg。根据几何级数的特性,我们得到
∥ J k − T g k J 0 ∥ ∞ ≤ 1 − γ k 1 − γ δ (7.33) \left\|J_{k}-\mathrm{T}_{\mathfrak{g}}^{k} J_{0}\right\|_{\infty} \leq \frac{1-\gamma^{k}}{1-\gamma} \delta \tag{7.33} ∥∥Jk−TgkJ0∥∥∞≤1−γ1−γkδ(7.33)
让极限 k → ∞ k \rightarrow \infty k→∞,结果由Proposition 3.5中的VI算法的收敛性得出,即 lim k → ∞ T g k J 0 = J ∗ \lim _{k \rightarrow \infty} \mathrm{T}_{\mathfrak{g}}^{k} J_{0}=J^{*} limk→∞TgkJ0=J∗。
与经典的VI算法类似,就近似VI算法产生的估计总成本函数而言,可以一系列贪婪诱导性策略。通过回顾Theorem 4.1中GIP的直接误差界限,我们直接得出以下属性
lim k → ∞ ∥ J π k − J ∗ ∥ ∞ ≤ 2 γ 1 − γ lim k → ∞ ∥ J k − J ∗ ∥ ∞ ≤ 2 γ δ ( 1 − γ ) 2 (7.34) \begin{aligned} \lim _{k \rightarrow \infty}\left\|J^{\pi_{k}}-J^{*}\right\|_{\infty} & \leq \frac{2 \gamma}{1-\gamma} \lim _{k \rightarrow \infty}\left\|J_{k}-J^{*}\right\|_{\infty} \\ & \leq \frac{2 \gamma \delta}{(1-\gamma)^{2}} \end{aligned} \tag{7.34} k→∞lim∥Jπk−J∗∥∞≤1−γ2γk→∞lim∥Jk−J∗∥∞≤(1−γ)22γδ(7.34)
其中 J π k J^{\pi_{k}} Jπk是相对于近似VI算法的第 k k k次迭代的GIP。
Corollary 7.2 一般AVI算法的有界性
给定一个无限范围的MDP { X , U , p , g , γ } \{\mathcal{X}, \mathcal{U}, p, g, \gamma\} { X,U,p,g,γ},让 J k J_{k} Jk 是由近似VI算法产生的总成本函数估计序列。让我们用 π k \pi_{k} πk表示关于 J k J_{k} Jk的相应的贪婪诱导策略,那么GIP的总成本函数 π k \pi_{k} πk满足以下属性
lim k → ∞ ∥ J π k − J ∗ ∥ ∞ ≤ 2 γ δ ( 1 − γ ) 2 (7.35) \lim _{k \rightarrow \infty}\left\|J^{\pi_{k}}-J^{*}\right\|_{\infty} \leq \frac{2 \gamma \delta}{(1-\gamma)^{2}} \tag{7.35} k→∞lim∥Jπk−J∗∥∞≤(1−γ)22γδ(7.35)
Remark 7.1 公差 δ \delta δ与误差 ρ \rho ρ的关系
正如我们已经讨论过的,上述误差界限可以是保守的。为了能够从AVI算法的结果中检索出一个最优策略,我们回顾一下命题4.3的结果。设 ρ > 0 \rho>0 ρ>0为最佳总成本函数和其最接近的总成本函数之间的误差,如公式(4.11)所定义。预计AVI算法极限处的误差界限将服从以下不等式
lim k → ∞ ∥ J k − J ∗ ∥ ∞ ≤ δ 1 − γ < ρ ( 1 − γ ) 2 γ (7.36) \lim _{k \rightarrow \infty}\left\|J_{k}-J^{*}\right\|_{\infty} \leq \frac{\delta}{1-\gamma}<\frac{\rho(1-\gamma)}{2 \gamma} \tag{7.36} k→∞lim∥Jk−J∗∥∞≤1−γδ<2γρ(1−γ)(7.36)
作为结果,我们有
δ < ρ ( 1 − γ ) 2 2 γ (7.37) \delta<\frac{\rho(1-\gamma)^{2}}{2 \gamma} \tag{7.37} δ<2γρ(1−γ)2(7.37)
显然,公差 δ \delta δ的选择取决于 ρ \rho ρ的总成本,不幸的是,这在一般情况下是无法获得的。
7.3 Example: E-Bus
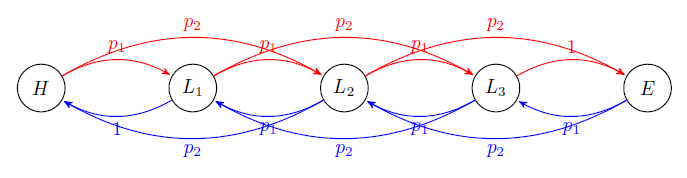
Consider a group of electric buses running round trips 24 hours a day. The task is to identify optimal operating actions at different battery states. The battery’s endurance and charging speed gradually decrease with the increase of battery life. Hence, for different buses, they have different transition probabilities between battery states. The following figure illustrates the state transitions between different states.
- Five states: H H H - high battery, E E E - empty battery, L 1 , L 2 , L 3 L_{1}, L_{2}, L_{3} L1,L2,L3 : three different low level battery statuses
- Two actions: S S S- continue to serve, C - charge
- Numbers on the edges refer to transition probabilities. p 1 = 0.4 , p 2 = 0.6 p_{1}=0.4, p_{2}=0.6 p1=0.4,p2=0.6
- Discount factor γ = 0.9 \gamma=0.9 γ=0.9 .
We choose the number of unserviced passengers as the local costs:
- In the high battery state, if it keeps the service, the unserviced passenger number is 0 .
- In all the low battery stats, if it keeps the service, the unserviced passenger number is 2 .
- In all the low battery state and empty battery, if it charges the battery, the unserviced passenger number is 5 .
Task 1: Implement Value Iteration (VI) and Approximate Value Iteration (AVI) algorithm with Linear Function approximation (LFA) using the feature matrix
Φ = [ − 0.40 − 0.44 − 0.45 − 0.46 − 0.48 − 0.07 0.73 − 0.61 0.21 − 0.23 ] \Phi=\left[\begin{array}{ccccc} -0.40 & -0.44 & -0.45 & -0.46 & -0.48 \\ -0.07 & 0.73 & -0.61 & 0.21 & -0.23 \end{array}\right] Φ=[−0.40−0.07−0.440.73−0.45−0.61−0.460.21−0.48−0.23]
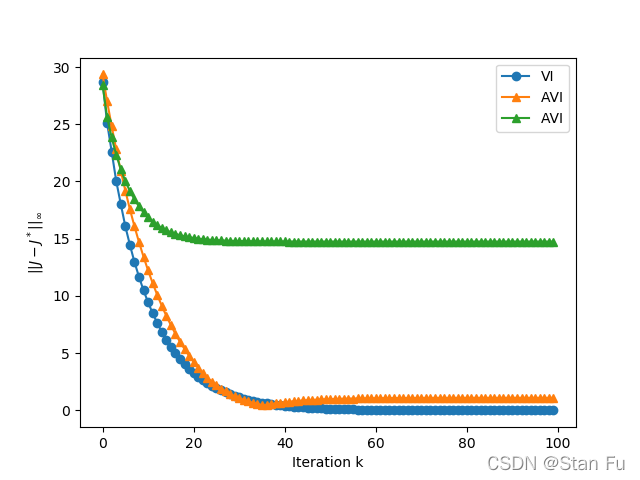
Compare their convergence speeds in terms of the difference from each iterate to the corresponding accumulation point ∥ J k − J ∗ ∥ ∞ \left\|J_{k}-J^{*}\right\|_{\infty} ∥Jk−J∗∥∞ against the index of sweep k k k .
Task 2: Given the gap between the optimal total cost and any non-optimal total cost ( ρ : = min π ∉ P d m ∗ ∥ J π − J ∗ ∥ ∞ = 0.239 \rho:= \min _{\pi \notin \mathfrak{P}_{d m}^{*}}\left\|J^{\pi}-J^{*}\right\|_{\infty}=0.239 ρ:=minπ∈/Pdm∗∥Jπ−J∗∥∞=0.239 ), check conditions on optimality in policy according to Eq. (7.24).
Task 3: If we use a random-generated feature matrix Φ \Phi Φ , repeat the aforementioned two tasks, what can we observe? Discussion: how do we choose the feature matrix Φ \Phi Φ .
7.3.1 相关代码
import random
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
matplotlib.rcParams.update(matplotlib.rcParamsDefault)
INIT_J = 0 # define initial total cost
ITER_N = 100 # the number of iterations
# transition probability
p1 = 0.4
p2 = 0.6
# cost of each state-action pair
ghs = 0
gl1s = gl2s = gl3s = 2
gec = gl3c = gl2c = gl1c = 5
# discount factor
gamma = 0.9
##
# using VI to get optimal_J. i.e. J*:
k = 0
jh = jl1 = jl2 = jl3 = je = INIT_J
while k < 200:
jh_ = p1 * (ghs + gamma * jl1) + p2 * (ghs + gamma * jl2)
jl1_ = min(p1 * (gl1s + gamma * jl2) + p2 * (gl1s + gamma * jl3), gl1c + gamma * jh)
jl2_ = min(p1 * (gl2s + gamma * jl3) + p2 * (gl2s + gamma * je),
p1 * (gl2c + gamma * jl1) + p2 * (gl2c + gamma * jh))
jl3_ = min(gl3s + gamma * je, p1 * (gl3c + gamma * jl2) + p2 * (gl3c + gamma * jl1))
je_ = p1 * (gec + gamma * jl3) + p2 * (gec + gamma * jl2)
jh, jl1, jl2, jl3, je = jh_, jl1_, jl2_, jl3_, je_
k += 1
jh_optim, jl1_optim, jl2_optim, jl3_optim, je_optim = jh, jl1, jl2, jl3, je
print('After VI we get the optimal costs {:.4f} {:.4f} {:.4f} {:.4f} {:.4f}'.format(jh_optim, jl1_optim, jl2_optim,
jl3_optim, je_optim))
##
# VI
jh = jl1 = jl2 = jl3 = je = INIT_J
vi_converge = []
for k in range(ITER_N):
jh_ = p1 * (ghs + gamma * jl1) + p2 * (ghs + gamma * jl2)
jl1_ = min(p1 * (gl1s + gamma * jl2) + p2 * (gl1s + gamma * jl3), gl1c + gamma * jh)
jl2_ = min(p1 * (gl2s + gamma * jl3) + p2 * (gl2s + gamma * je),
p1 * (gl2c + gamma * jl1) + p2 * (gl2c + gamma * jh))
jl3_ = min(gl3s + gamma * je, p1 * (gl3c + gamma * jl2) + p2 * (gl3c + gamma * jl1))
je_ = p1 * (gec + gamma * jl3) + p2 * (gec + gamma * jl2)
jh, jl1, jl2, jl3, je = jh_, jl1_, jl2_, jl3_, je_
k += 1
# calculate the infinite norm of ||J_k - J*||
infinity_gap = max(
abs(jh - jh_optim),
abs(jl1 - jl1_optim),
abs(jl2 - jl2_optim),
abs(jl3 - jl3_optim),
abs(je - je_optim)
)
vi_converge.append(infinity_gap)
plt.plot(range(ITER_N), vi_converge, 'o-', label='VI')
plt.ylabel(r"$\|\| J - J^*\|\|_{\infty}$")
plt.xlabel('Iteration k')
##
# Approximate value iteration using specific features
phi = np.array([[-0.4, -0.44, -0.45, -0.46, -0.48],
[-0.07, 0.73, -0.61, 0.21, -0.23]])
inv = np.linalg.inv(phi @ phi.T)
PI = phi.T @ inv @ phi
# boundary of optimal indirect estimate
rho = 0.239
boundary = rho * (1 - gamma) / (2 * (1 + gamma))
print('Upper bound = {}, '.format(boundary))
J_AVI = np.array([0, 0, 0, 0, 0])
J_OPT = np.array([jh_optim, jl1_optim, jl2_optim, jl3_optim, je_optim])
print('\t and the left hand side = {}'.format(min(abs(PI @ J_OPT - J_OPT))))
avi_converge = []
for k in range(ITER_N):
# TgJk
jh, jl1, jl2, jl3, je = J_AVI
jh_ = p1 * (ghs + gamma * jl1) + p2 * (ghs + gamma * jl2)
jl1_ = min(p1 * (gl1s + gamma * jl2) + p2 * (gl1s + gamma * jl3), gl1c + gamma * jh)
jl2_ = min(p1 * (gl2s + gamma * jl3) + p2 * (gl2s + gamma * je),
p1 * (gl2c + gamma * jl1) + p2 * (gl2c + gamma * jh))
jl3_ = min(gl3s + gamma * je, p1 * (gl3c + gamma * jl2) + p2 * (gl3c + gamma * jl1))
je_ = p1 * (gec + gamma * jl3) + p2 * (gec + gamma * jl2)
J_AVI = np.array([jh_, jl1_, jl2_, jl3_, je_])
# orthogonal projector
J_AVI = PI @ J_AVI
if min(abs(J_AVI - J_OPT)) <= boundary:
print('After {} iterations, the policy is optimal'.format(k))
avi_converge.append(max(abs(J_AVI - J_OPT)))
plt.plot(range(ITER_N), avi_converge, '^-', label='AVI')
##
# Approximate value iteration using random features
phi = np.random.rand(2, 5)
inv = np.linalg.inv(phi @ phi.T)
PI = phi.T @ inv @ phi
# boundary of optimal indirect estimate
rho = 0.239
boundary = rho * (1 - gamma) / 2 * (1 + gamma)
J_AVI_rand = np.array([0, 0, 0, 0, 0])
avi_converge_rand = []
for k in range(ITER_N):
# TgJk
jh, jl1, jl2, jl3, je = J_AVI_rand
jh_ = p1 * (ghs + gamma * jl1) + p2 * (ghs + gamma * jl2)
jl1_ = min(p1 * (gl1s + gamma * jl2) + p2 * (gl1s + gamma * jl3), gl1c + gamma * jh)
jl2_ = min(p1 * (gl2s + gamma * jl3) + p2 * (gl2s + gamma * je),
p1 * (gl2c + gamma * jl1) + p2 * (gl2c + gamma * jh))
jl3_ = min(gl3s + gamma * je, p1 * (gl3c + gamma * jl2) + p2 * (gl3c + gamma * jl1))
je_ = p1 * (gec + gamma * jl3) + p2 * (gec + gamma * jl2)
J_AVI_rand = np.array([jh_, jl1_, jl2_, jl3_, je_])
# orthogonal projector
J_AVI_rand = PI @ J_AVI_rand
if min(abs(J_AVI_rand - J_OPT)) <= boundary:
print('After {} iterations, the policy is optimal'.format(k))
avi_converge_rand.append(max(abs(J_AVI_rand - J_OPT)))
plt.plot(range(ITER_N), avi_converge_rand, '^-', label='AVI')
plt.legend()
plt.show()
7.3.2 输出结果
After VI we get the optimal costs 26.1268 28.5141 29.3736 30.7331 31.9256
Upper bound = 0.006289473684210525,
and the left hand side = 0.20402763408068125
After 44 iterations, the policy is optimal
7.3.3 Feature matrix Φ \Phi Φ
- Calculate J π J^{\pi} Jπ for all the possible policies. J π ∈ R 8 × 5 J^{\pi} \in \mathbb{R}^{8 \times 5} Jπ∈R8×5
So, how to establish a J π J^{\pi} Jπ for all the possible policies? - Singular value decomposition (SVD): J π = U Σ V ∗ J^{\pi}=\mathbf{U \Sigma V}^{*} Jπ=UΣV∗.
- Select the first two component of V ∗ \mathbf{V}^{*} V∗ as Φ \Phi Φ