欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://spike.blog.csdn.net/article/details/132473686
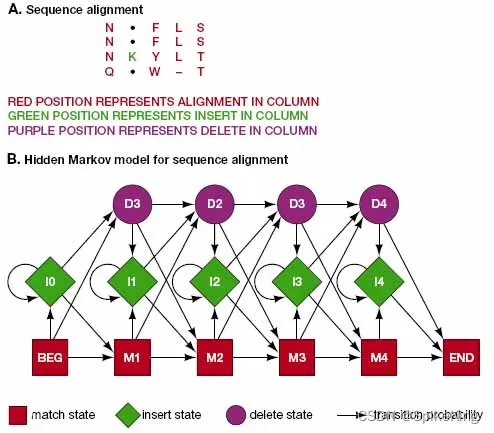
HHsearch 是基于 HMM-HMM 比较的算法实现的搜索工具,可以用来检测蛋白质的远缘同源性,生成高质量的序列比对,用于同源建模和功能预测。优点是可以利用蛋白质序列的共进化信息,提高搜索的灵敏度和准确度。还可以使用多种结构域数据库进行搜索,包括PDB、SCOP、Pfam等,增加了搜索的覆盖度和多样性。
在 AlphaFold 中,HHsearch 用于模版搜索,搜索 PDB70 库。有时,仅有 MSA 文件,没有模版文件 (pdb_hits.hhr) 时,输入已搜索的 UniRef MSA 文件,使用 HHsearch 进行模版 (Template) 搜索。
1. OpenFold 中 Template 逻辑
在 OpenFold Multimer 中,所支持的 MSA 与 Template 文件夹结构,如下:
alignments/
├── A
│ ├── bfd_uniref_hits.a3m
│ ├── mgnify_hits.sto
│ ├── pdb_hits.sto
│ ├── uniprot_hits.sto
│ └── uniref90_hits.sto
└── B
├── bfd_uniref_hits.a3m
├── mgnify_hits.sto
├── pdb_hits.sto
├── uniprot_hits.sto
└── uniref90_hits.sto
其中 Template 文件,支持 pdb_hits.sto 或者 pdb_hits.hhr 两种格式,源码位于 openfold/data/data_pipeline.py ,即:
if ext == ".hhr":
hits = parsers.parse_hhr(read_template(start, size))
all_hits[name] = hits
elif name == "pdb_hits.sto":
hits = parsers.parse_hmmsearch_sto(
read_template(start, size),
input_sequence,
)
all_hits[name] = hits
2. 搜索 Template 文件
参考 OpenFold 脚本 scripts/precompute_alignments_mmseqs.py 的 hhsearch 部分,即:
hhsearch_pdb70_runner = hhsearch.HHSearch(
binary_path=args.hhsearch_binary_path, databases=[args.pdb70])
for d in os.listdir(args.output_dir):
dpath = os.path.join(args.output_dir, d)
if not os.path.isdir(dpath):
continue
for fname in os.listdir(dpath):
fpath = os.path.join(dpath, fname)
# 使用 uniref 文件搜索 pdb 70 的库
if "uniref" not in fname or not os.path.splitext(fname)[-1] == ".a3m":
continue
with open(fpath, "r") as fp:
a3m = fp.read()
hhsearch_result = hhsearch_pdb70_runner.query(a3m)
pdb70_out_path = os.path.join(dpath, "pdb70_hits.hhr")
with open(pdb70_out_path, "w") as f:
f.write(hhsearch_result)
现有的 MSA 格式,目前只能使用 mmdb_uniref30_hits 搜索 pdb70,即:
8slg/
├── 8slg.fasta
├── A
│ ├── jackhmmer_uniprot_hits.sto
│ ├── mmdb_envdb_hits.a3m
│ ├── mmdb_pdb70_hits.a8
│ └── mmdb_uniref30_hits.a3m
└── B
├── jackhmmer_uniprot_hits.sto
├── mmdb_envdb_hits.a3m
├── mmdb_pdb70_hits.a8
└── mmdb_uniref30_hits.a3m
结合 AlphaFold 与 OpenFold 的模版搜索逻辑,开发脚本 main_search_template.py。
测试脚本:
python scripts/main_search_template.py -i mydata/mini_fasta_msa/ -b /opt/conda/envs/alphafold/bin/hhsearch -p af2_data_dir/pdb70/pdb70
单条处理时间,约 1min 左右,即:

[Info] fasta: 1%|▌ | 6/1169 [05:36<18:54:27, 58.53s/it]
输出文件如下:
apt-get install tree
tree 8slg/
# 文件结构,已包括 pdb70_hits.hhr
8slg/
├── 8slg.fasta
├── A
│ ├── jackhmmer_uniprot_hits.sto
│ ├── mmdb_envdb_hits.a3m
│ ├── mmdb_pdb70_hits.a8
│ ├── mmdb_uniref30_hits.a3m
│ └── pdb70_hits.hhr
└── B
├── jackhmmer_uniprot_hits.sto
├── mmdb_envdb_hits.a3m
├── mmdb_pdb70_hits.a8
├── mmdb_uniref30_hits.a3m
└── pdb70_hits.hhr
参考:
其他
main_search_template.py 的源码,如下:
#!/usr/bin/env python
# -- coding: utf-8 --
"""
Copyright (c) 2022. All rights reserved.
Created by C. L. Wang on 2023/8/24
"""
import argparse
import os
import sys
from multiprocessing import Pool
from pathlib import Path
from tqdm import tqdm
p = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
if p not in sys.path:
sys.path.append(p)
from myutils.project_utils import traverse_dir_files, traverse_dir_files_for_large
from scripts.tools import hhsearch
class MainSearchTemplate(object):
"""
搜索 Template 使用 HHSearch
"""
def __init__(self):
pass
@staticmethod
def process_msa_dir(hhsearch_binary_path, pdb70_path, msa_dir, input_tag="uniref30_hits.a3m"):
"""
处理 msa 文件,搜索 template 结构
:param hhsearch_binary_path: hhsearch 二进制文件
:param pdb70_path: pdb70 路径
:param msa_dir: msa 文件夹
:param input_tag: 输入标志
:return: None,直接写入
"""
assert os.path.isdir(msa_dir)
hhsearch_pdb70_runner = hhsearch.HHSearch(
binary_path=hhsearch_binary_path, databases=[pdb70_path])
path_list = traverse_dir_files(msa_dir)
for path in path_list:
file_name = os.path.basename(path)
if file_name == "pdb70_hits.hhr": # 不需要处理
return
for path in path_list:
file_name = os.path.basename(path)
if input_tag in file_name:
# 使用 uniref 文件搜索 pdb 70 的库
assert "uniref" in file_name and os.path.splitext(file_name)[-1] == ".a3m"
with open(path, "r") as fp:
a3m = fp.read()
msa_folder = os.path.dirname(path)
hhsearch_result = hhsearch_pdb70_runner.query(a3m)
pdb70_out_path = os.path.join(msa_folder, "pdb70_hits.hhr")
with open(pdb70_out_path, "w") as f:
f.write(hhsearch_result)
else:
continue
@classmethod
def process_msa_dir_wrapper(cls, params):
hhsearch_binary_path, pdb70_path, msa_dir = params
cls.process_msa_dir(hhsearch_binary_path, pdb70_path, msa_dir)
@classmethod
def process(cls, hhsearch_binary_path, pdb70_path, input_dir):
"""
搜索 Template 文件
"""
print(f"[Info] hhsearch_binary_path: {hhsearch_binary_path}")
print(f"[Info] pdb70_path: {pdb70_path}")
print(f"[Info] input_dir: {input_dir}")
assert os.path.isdir(input_dir)
path_list = traverse_dir_files_for_large(input_dir)
msa_folders = set()
for path in path_list:
if path.endswith(".a3m"):
msa_folders.add(os.path.dirname(path))
msa_folders = sorted(list(msa_folders))
print(f"[Info] msa folders 路径: {len(msa_folders)}")
params_list = []
for msa_dir in msa_folders:
params_list.append((hhsearch_binary_path, pdb70_path, msa_dir))
num_proc = 40
pool = Pool(processes=num_proc)
list(tqdm(pool.imap(cls.process_msa_dir_wrapper, params_list), desc="[Info] fasta"))
pool.close()
pool.join()
# 单进程 debug
# for params in tqdm(params_list, "[Info] fasta"):
# cls.process_msa_dir_wrapper(params)
print(f"[Info] 全部处理完成! {input_dir}")
def main():
parser = argparse.ArgumentParser()
parser.add_argument(
"-i",
"--input-dir",
help="the input file of fasta.",
type=Path,
required=True,
)
parser.add_argument(
"-b",
"--hhsearch-binary-path",
help="as the name.",
type=Path,
required=True
)
parser.add_argument(
"-p",
"--pdb70-path",
help="as the name.",
type=Path,
required=True
)
args = parser.parse_args()
input_dir = str(args.input_dir)
hhsearch_binary_path = str(args.hhsearch_binary_path)
pdb70_path = str(args.pdb70_path)
print(f"[Info] hhsearch_binary_path: {hhsearch_binary_path}")
print(f"[Info] pdb70_path: {pdb70_path}")
print(f"[Info] input_dir: {input_dir}")
assert os.path.isdir(input_dir) and os.path.isfile(hhsearch_binary_path)
st = MainSearchTemplate()
st.process(hhsearch_binary_path, pdb70_path, input_dir)
if __name__ == '__main__':
main()