
1 分析
1 多元线性回归
- 使用模型(根据观测到的值拟合的线性方程)描述一个结果和两个或者两个以上的特征之间的关系
- 实现过程类似于 单特征值
- 通过分析,找出对预测结果影响最大的特征,以及不同变量之间的相关性。y=b0+b1x1+b2x2+...+bnxn
2 预测
- 一个成功的回归分析,必须证明下面预测正确
- 线性性:变量和自变量之间是线性关系。
- 同方差性:总体回归函数中的随机误差项(干扰项)在解释变量条件下具有不变的方差。
- 多元正态性 :多因素共同影响结果
- 没有多重共线性: 自变量间相互关系较弱,或几乎没有。-----例如 虚拟变量陷阱
3 筛选变量
- 变量过多 导致模型不精确
- 变量对结果无作用 却对其他自变量有很大的作用
1.forward selection:一个个加入feature
1)选择一个差异等级(significance level)比如SL=0.05 意味着对结果有95%贡献 (2)建立所有的简单回归的模型,并找到最小的P值 (3)确立一个简单模型,并将拥有最小P值的变量加入此模型 (4)如果P>SL,模型建立成功,否则在进行第三步
2.Backward Elimination:首先包含了所有的feature,然后每个feature都尝试去删除,测试删除的哪个feature对模型准确性有最大的提升,最终删掉对模型提升最高的一个特征。如此类推,直到删除feature并不能提升模型为止。
3.Stepwise则是结合上述两者的方法,当一个feature新加入后,stepwise会尝试删去一个feature,直至达到某个预设的标准。这种方法的缺点是,预设的标准不好定,而且容易陷入到过拟合当中-----https://onlinecourses.science.psu.edu/stat501/node/329/
4.Bi-direction Comparision
4 虚拟变量
- 使用分类数据 将非数字数据加入模型
5 虚拟变量陷阱
- 如果模型中每个定性因素有m个相互排斥的类型, 且模型有截距项,则模型中只能引入m-1个虚拟变量, 否则会出现完全多重共线性
拿性别来说,其实一个虚拟变量就够了,比如 1 的时候是“男”, 0 的时候是”非男”,即为女。如果设置两个虚拟变量“男”和“女”,语义上来说没有问题,可以理解,但是在回归预测中会多出一个变量,多出的这个变量将会对回归预测结果产生影响。一般来说,如果虚拟变量要比实际变量的种类少一个。
2 实操

Step1 数据预处理----类似于 Day1_Data preprocessing
但是要注意 避开虚拟变量陷阱
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
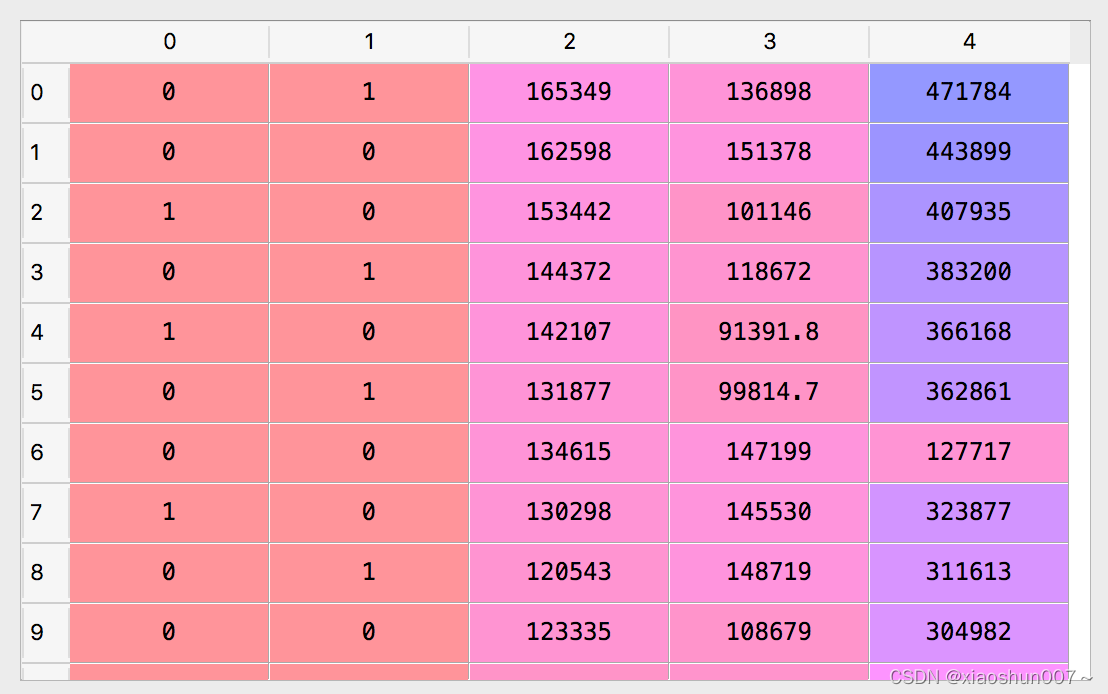
dataset = pd.read_csv('50_Startups.csv')
X = dataset.iloc[ : , :-1].values
Y = dataset.iloc[ : , 4 ].values
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder = LabelEncoder()
X[: , 3] = labelencoder.fit_transform(X[ : , 3])
onehotencoder = OneHotEncoder(categorical_features = [3])
X = onehotencoder.fit_transform(X).toarray()
X = X[: , 1:] ### 避免虚拟变量陷阱
from sklearn.cross_validation import train_test_split ## 分割数据集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size = 0.2, random_state = 0)
PS: 避免虚拟数据陷阱,只选择 两个(3-1)虚拟变量
Step 2: Fitting Multiple Linear Regression to the Training set----类似于Day2-简单线性回归
from sklearn.linear_model import LinearRegression regressor = LinearRegression() regressor.fit(X_train, Y_train) ## 多重线性回归模型应用到训练集
Step 3: Predicting the Test set results
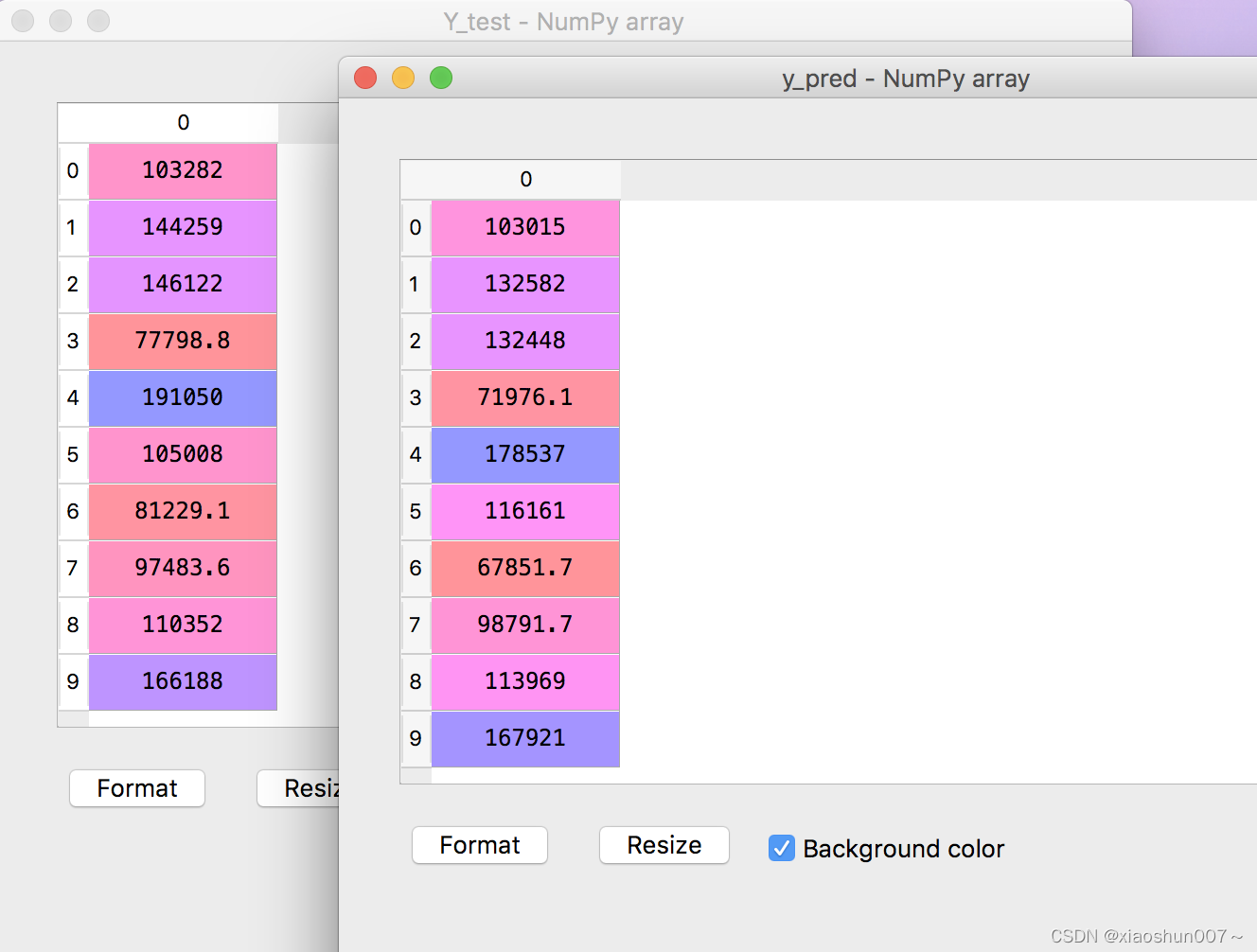
y_pred = regressor.predict(X_test)
扫描二维码关注公众号,回复:
16963198 查看本文章

Step 4: 可视化
plt.scatter(np.arange(10),Y_test, color = 'red',label='y_test') plt.scatter(np.arange(10),y_pred, color = 'blue',label='y_pred') plt.legend(loc=2); plt.show()
