小朋友们好,大朋友们好!
我是猫妹,一名爱上Python编程的小学生。
关注我,一起趣味学编程!
爬虫的基本概念
你听过爬虫吗?
计算中的爬虫,又称为网络爬虫、网页蜘蛛、网络机器人,它是一段计算机器代码,可以自动抓取网页上的数据。
网页是由什么组成呢?
网页一般由文本、图像、音频、视频等元素组成。
它们通过HTML、JS、CSS等编程语法排列组合,然后生成网页。也就是说,我们看到的文字、图片、视频等是和HTML等元素混合在一起的。
爬虫所做的工作就是从网页中把我们关心的文本、图像、音频、视频等提取出来,我们不关心HTML等元素,但我们需要按照HTML等的语法来解析网页。
爬虫的基本结构
一个简单的爬虫由四部分组成:URL管理器、网页下载器、网页解析器、数据存储器等。
- URL管理器就是你要下载哪个网页的内容,URL中有超链接,这些链接是否需要下载,下载时需要去重等。
- 网页下载器就是下载网页的内容,将网页的内容下载到本地。常用的两个http请求库有urllib库和request库。前者是Python官方基本模块。后者是性能优越使用广泛的第三方库。
- 网页解析器就是解析网页内容,提取我们关心的信息。用到的知识有正则表达式、lxml库和Beautiful Soup库。
- 数据存储库主要就是存储数据,将数据持久化存储到本地。
为什么Python在爬虫领域独领风骚?
因为有很多成熟好用的相关库,拿来就用,节省了造轮子的时间。
爬虫的工作流程
爬虫的工作流程主要有四步:
- Request发起请求,客户端请求服务器响应。
- Reponse获取响应,此时服务器将所请求的网页送到客户端。
- 解析内容,利用正则表达式、lxml库或Beautiful Soup库提取目标信息。
- 保存数据,将解析后的数据保存到本地,可以是文本、音频、图片、视频等。
如何限制爬虫
目前对网络爬虫的限制主要有两种方式:
1.来源审查:判断User-Agent(在请求头中的一个键值对)进行限制,通过该键值对可以判断发起网络请求的浏览器类型,网站维护人员可以根据这个进行请求限制。
2.发布公告:Robots协议。
Robots协议是一种网站管理员用来告知搜索引擎蜘蛛哪些页面可以抓取,哪些页面不可以抓取的文本文件。
robots.txt是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的漫游器(又称网络爬虫/蜘蛛),此网站中的哪些内容是不能被搜索引擎的漫游器获取的,哪些是可以被获取的。当robots访问一个网站时,它会首先查看该网站根目录下是否存在robots.txt文件,如果存在,它将按照文件中规定的规则进行访问 。
可以查看一些网站的robots.txt文件,比如:
遵纪守法
robots.txt是道德规范,是一个协议,它不是命令,不是强制执行,大家一定要自觉遵守。
爬虫技术是一种自动化获取网络信息的技术,但是如果不遵守相关法律法规,就会触犯法律。
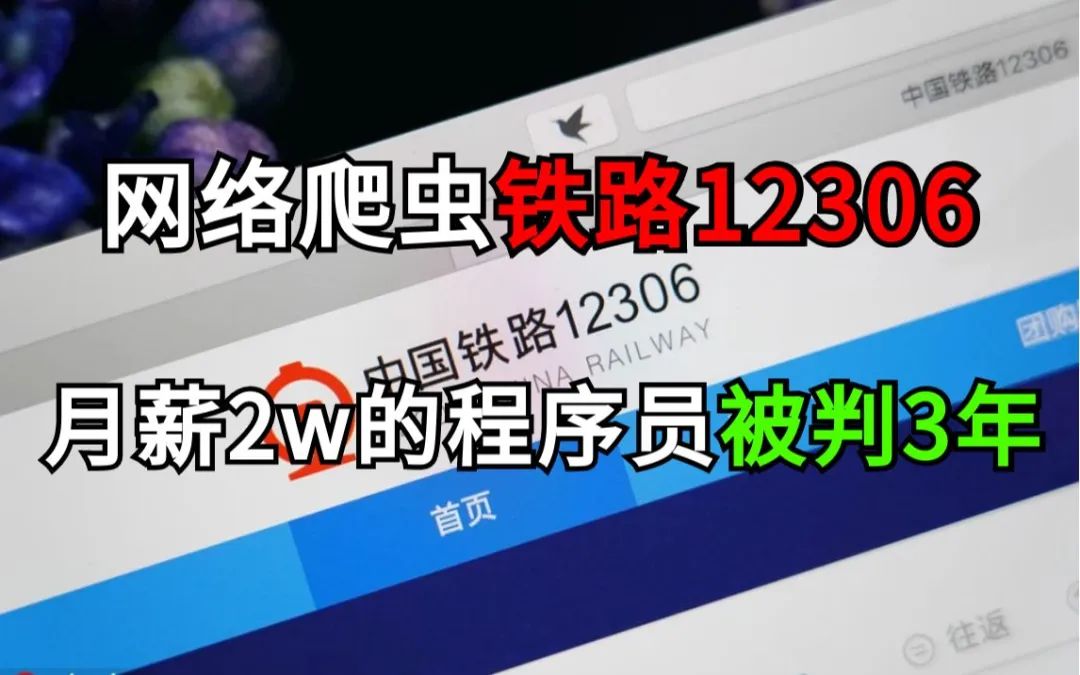
为了避免这种情况,我们可以采取以下措施:
1.在爬虫程序中设置访问限制,避免对目标网站造成过大的访问压力;
2.在爬虫程序中设置合理的请求间隔,避免对目标网站造成过大的访问量;
3.在爬虫程序中设置合理的抓取深度,避免对目标网站造成过大的数据抓取量;
4.在爬虫程序中设置合理的数据存储方式,避免对目标网站造成过大的数据存储压力;
5.在使用爬虫技术时,应该尊重目标网站的隐私权和知识产权,不得侵犯其合法权益 。
好了,我们今天的分享就到这里!
如果遇到什么问题,咱们多多交流,共同解决。
我是猫妹,咱们下次见!