Stability AI 发布了开源视频生成模型 Stable Video Diffusion,该模型基于该公司现有的 Stable Diffusion 文本转图像模型,能够通过对现有图像进行动画化生成视频。
主要特性
- 文本到视频
- 图像到视频
- 14 或 25 帧,576 x 1024分辨率
- 多视图生成
- 帧插值
- 支持3D 场景
- 通过 LoRA 控制摄像机

Stable Video Diffusion 提供两个模型,分别为 SVD 和 SVD-XT。其中,SVD 将静止图像转换为 14 帧的 576x1024 视频,而 SVD-XT 在相同的架构下将帧数提升至 24。
两者都能以每秒 3 到 30 帧的速度生成视频。白皮书显示,这两个模型最初在数百万个视频的数据集上进行训练,然后在数十万到百万数量级的较小数据集上进行“微调”。
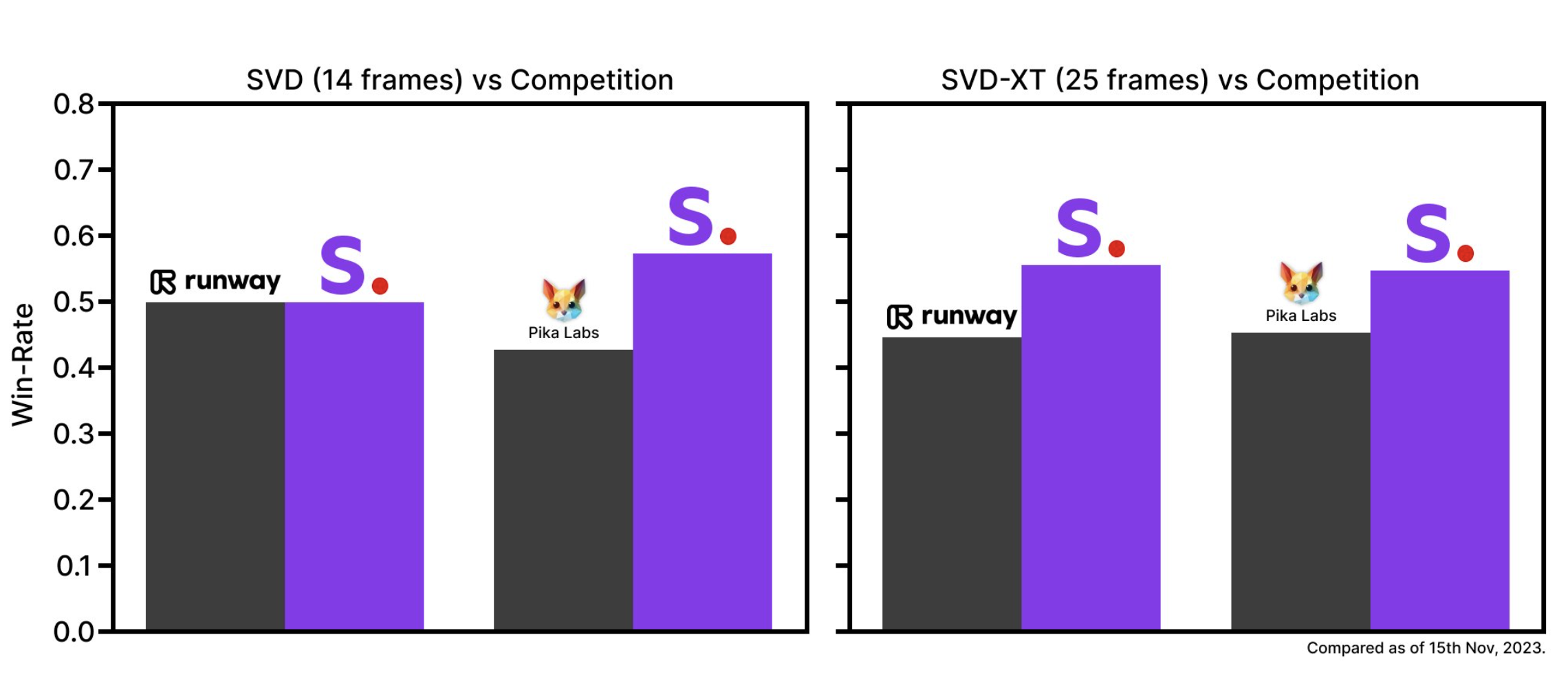
Stability AI 称正在开发一个新的网络平台,包括一个文本到视频的界面。这个工具将展示Stable Video Diffusion在广告、教育、娱乐等多个领域的实际应用。
开源地址