题目来源于leetcode,解法和思路仅代表个人观点。传送门。
难度:困难
时间:4h
题目
给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词。
单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
示例 1:
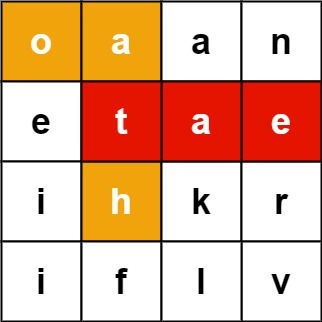
输入:board = [["o","a","a","n"],["e","t","a","e"],["i","h","k","r"],["i","f","l","v"]], words = ["oath","pea","eat","rain"]
输出:["eat","oath"]
示例 2:
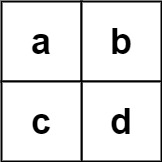
输入:board = [["a","b"],["c","d"]], words = ["abcb"]
输出:[]
提示:
m == board.length
n == board[i].length
1 <= m, n <= 12
board[i][j]是一个小写英文字母
1 <= words.length <= 3 * 104
1 <= words[i].length <= 10
words[i] 由小写英文字母组成
words 中的所有字符串互不相同
思路
字典树
「208. 实现 Trie (前缀树) 的官方题解」
没有什么特别难想到的思路,
就是根据words建立字典树,然后dfs每一个border[i][j],
主要难度在代码实现上,这里放上官方题解。

代码
class Solution {
public:
struct Node{
/*
* 注:第一个根结点是不用于存储信息的
*/
string word; //用于存储结尾的字符串
bool isEnd; //字符串是否结尾
int cnt; //以当前字符结尾的字符串数量 == this->cnt - next->cnt
Node* next[26];
Node(){
this->word = "";
this->isEnd = false;
this->cnt = 0;
for(int i=0;i<26;i++){
next[i] = nullptr;
}
}
};
void insert_dfs(Node* root,string& s,int index){
if(index >= s.length()){
root->isEnd = true;
root->word = s;
return;
}
char ch = s[index++];
if(root->next[ch - 'a'] == nullptr){
//分配空间
root->next[ch - 'a'] = new Node();
}
//计数
root->next[ch - 'a']->cnt++;
/*
* 注:insert_dfs()中的root参数不可传入nullptr,否则后续new的结点会找不到。
*/
//继续插
insert_dfs(root->next[ch - 'a'],s,index);
}
void insert_loop(Node* root,const string& s){
int n = s.length();
/*
* 注:需要用临时node代替root进行迭代,否则会改变root指针
*/
Node* node = root;
for(int i=0;i<n;i++){
char ch = s[i];
if(node->next[ch - 'a'] == nullptr){
node->next[ch - 'a'] = new Node();
}
node = node->next[ch - 'a'];
//计数
node->cnt++;
}
node->word = s;
node->isEnd = true;
}
//方向数组
int dirs[4][2] = {
{
1, 0}, {
-1, 0}, {
0, 1}, {
0, -1}};
//因为答案可能重复,而且需要按照字典序排列
set<string> my_set;
void dfs(vector<vector<char>>& board,int i,int j,Node* root){
/*
* 注意:
* return的顺序
* 1. 越界错误判断
* 2. 减枝
*
* 记录答案后,并不return。因为,该结点可能只是另一个串的前缀。如"abc","abcd"
*
* trick:
* 利用【方向】数组,利用循环遍历每个方向。
*/
//错误判断
if(i<0 || i>=board.size() || j<0 || j>=board[0].size() || board[i][j] == '#'){
return;
}
char ch = board[i][j];
//指向下一个结点
root = root->next[ch - 'a'];
//减枝
if(root == nullptr){
return;
}
//记录答案
if(root->isEnd == true){
my_set.insert(root->word);
}
//标记
board[i][j] = '#';
//上下左右搜索
for(int k=0;k<4;k++){
int next_i = i + dirs[k][0];
int next_j = j + dirs[k][1];
dfs(board,next_i,next_j,root);
}
//解除标记
board[i][j] = ch;
}
vector<string> findWords(vector<vector<char>>& board, vector<string>& words) {
//构建字典树
Node* root = new Node();
for(auto& word:words){
// insert_dfs(root,word,0);
insert_loop(root,word); //迭代稍微快一点点
}
vector<string> ans;
int m = board.size();
int n = board[0].size();
/*
* 遍历每个结点,进行dfs,根据字典树判断是否满足条件。
* 把满足条件的加入my_set中
*/
for(int i=0;i<m;i++){
for(int j=0;j<n;j++){
dfs(board,i,j,root);
}
}
//遍历 集合my_set,加入到答案中
for(auto& key:my_set){
ans.emplace_back(key);
}
return ans;
}
};
算法复杂度
时间复杂度: O ( m × n × 3 l − 1 ) O(m×n×3^{l−1}) O(m×n×3l−1),其中 m m m 是二维网格的高度, n n n 是二维网格的宽度, l l l 是最长单词的长度。我们需要遍历 m × n m \times n m×n 个单元格,每个单元格最多需要遍历 4 × 3 l − 1 4 \times 3^{l-1} 4×3l−1条路径。
空间复杂度: O ( k × l ) O(k×l) O(k×l),其中 k k k 是 words \textit{words} words的长度, l l l 是最长单词的长度。最坏情况下,我们需要 O ( k × l ) O(k \times l) O(k×l) 用于存储前缀树。