火焰图的认识与使用-目录
火焰图的基本认识
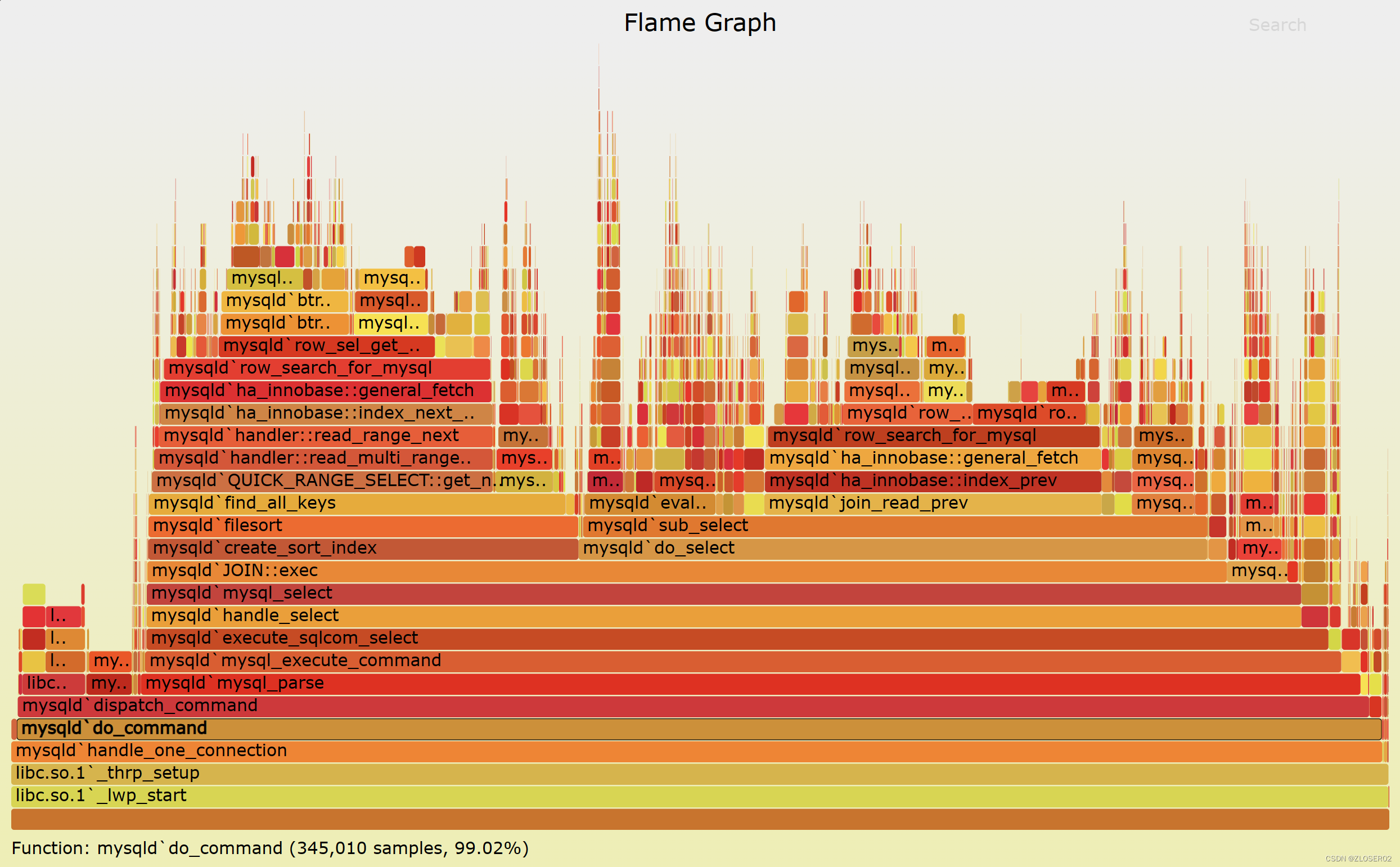
火焰图整个图形看起来就像一个跳动的火焰,这就是它名字的由来。
火焰图有以下特征(on-cpu)
1.每一列代表一个调用栈,每一个格子代表一个函数。
2.纵轴展示了栈的深度,按照调用关系从下到上排列。最顶上格子代表采样时,正在占用 cpu 的函数。
3.横轴的意义是指:火焰图将采集的多个调用栈信息,通过按字母横向排序的方式将众多信息聚合在一起。需要注意的是它并不代表时间。
4.横轴格子的宽度代表其在采样中出现频率,所以一个格子的宽度越大,说明它是瓶颈原因的可能性就越大。
5.火焰图格子的颜色是随机的暖色调,方便区分各个调用信息。
其他的采样方式也可以使用火焰图, on-cpu 火焰图横轴是指 cpu 占用时间,off-cpu 火焰图横轴则代表阻塞时间。
6.采样可以是单线程、多线程、多进程甚至是多 host,进阶用法可以参考附录进阶阅读。
火焰图能做什么
1.可以分析函数执行的频繁程度(占用cpu时间,或者阻塞的时间)。
2.可以分析哪些函数经常阻塞。
3.可以分析哪些函数频繁分配内存。
火焰图类型
常见的火焰图类型有 On-CPU,Off-CPU,还有 Memory,Hot/Cold,Differential 等等。它们有各自适合处
理的场景。

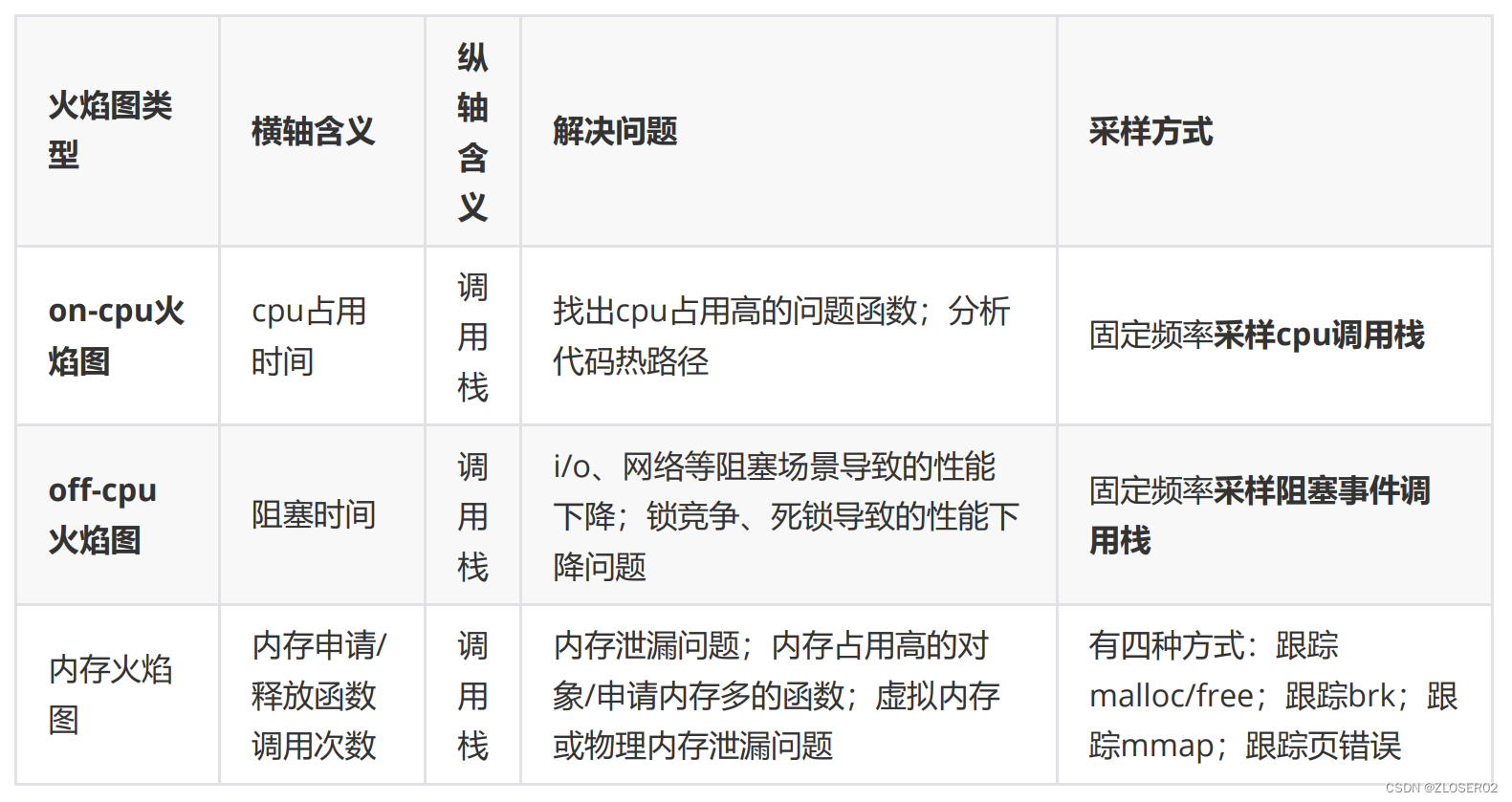
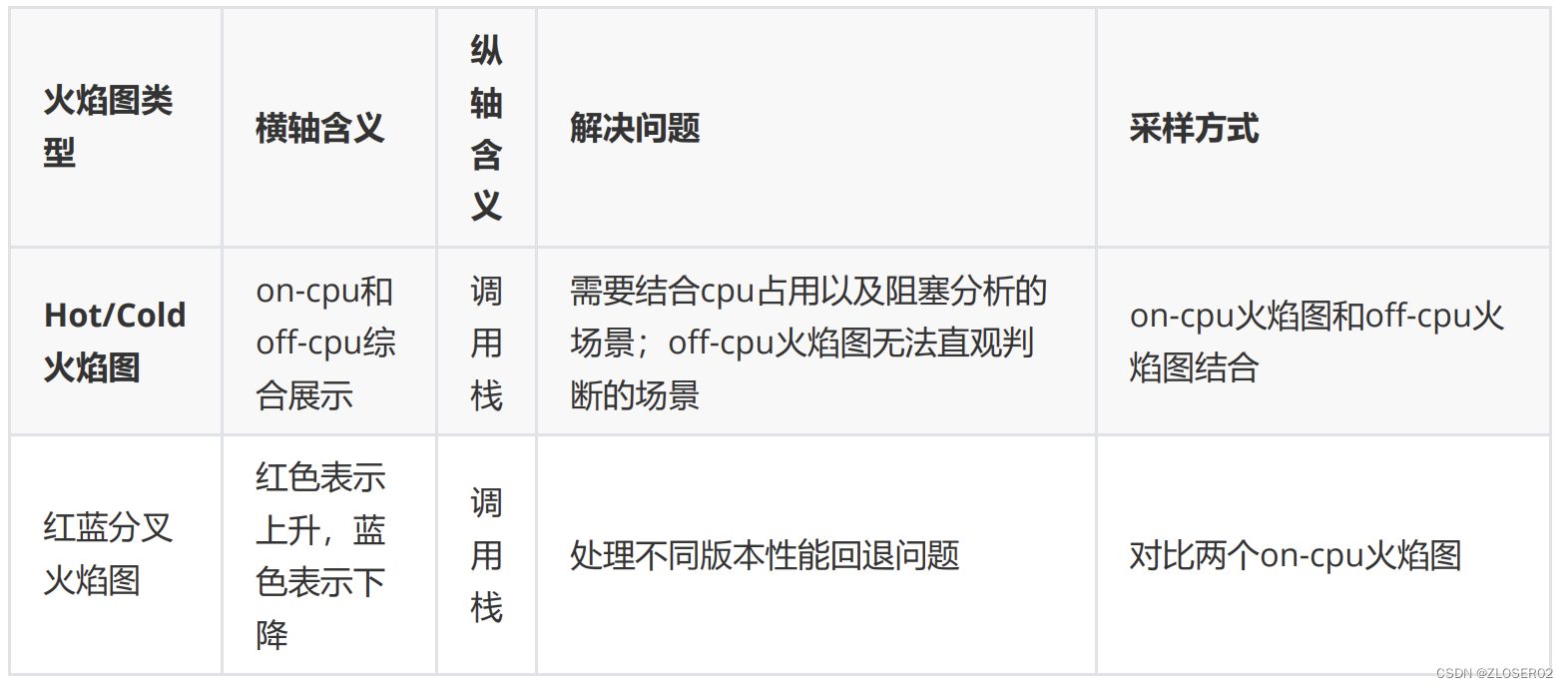
On-CPU 火焰图和Off-CPU火焰图的使用场景
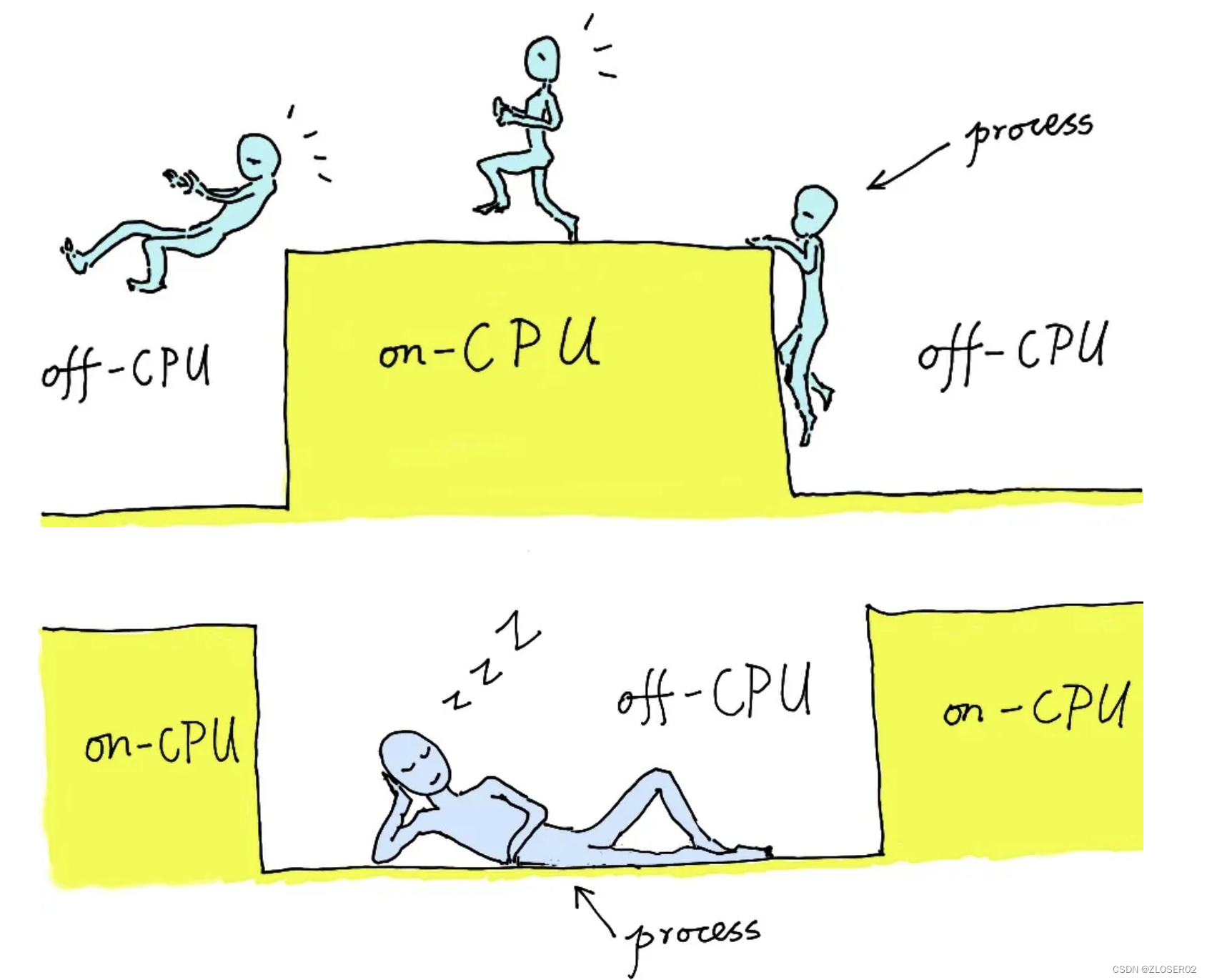
取决于当前的瓶颈到底是什么:
1.如果是 CPU 则使用 On-CPU 火焰图,(先看cpu是不是快到百分百)。
2.如果是 IO 或锁则使用 Off-CPU 火焰图(如果cpu占用率不高,就需要用off-cpu)。
3.如果无法确定, 那么可以通过压测工具来确认:
1.通过压测工具看看能否让 CPU 使用率趋于饱和, 如果能那么使用 On-CPU 火焰图
2.如果不管怎么压, CPU 使用率始终上不来, 那么多半说明程序被 IO 或锁卡住了, 此时适合使用 Off-CPU 火焰图.
4.如果还是确认不了, 那么不妨 On-CPU 火焰图和 Off-CPU 火焰图都搞搞, 正常情况下它们的差异会比较大, 如果两张火焰图长得差不多, 那么通常认为 CPU 被其它进程抢占了.
火焰图分析技巧
- 纵轴代表调用栈的深度(栈桢数),用于表示函数间调用关系:下面的函数是上面函数的父函数。
- 横轴代表调用频次,一个格子的宽度越大,越说明其可能是瓶颈原因。
- 不同类型火焰图适合优化的场景不同:
- 比如 on-cpu 火焰图适合分析 cpu 占用高的问题函数;
- off-cpu 火焰图适合解决阻塞和锁抢占问题。
- 无意义的事情:横向先后顺序是为了聚合,跟函数间依赖或调用关系无关;火焰图各种颜色是为方便区
分,本身不具有特殊含义 - 多练习:进行性能优化有意识的使用火焰图的方式进行性能调优(如果时间充裕)
如何绘制火焰图
注意:采集需要ROOT权限
生成火焰图的流程
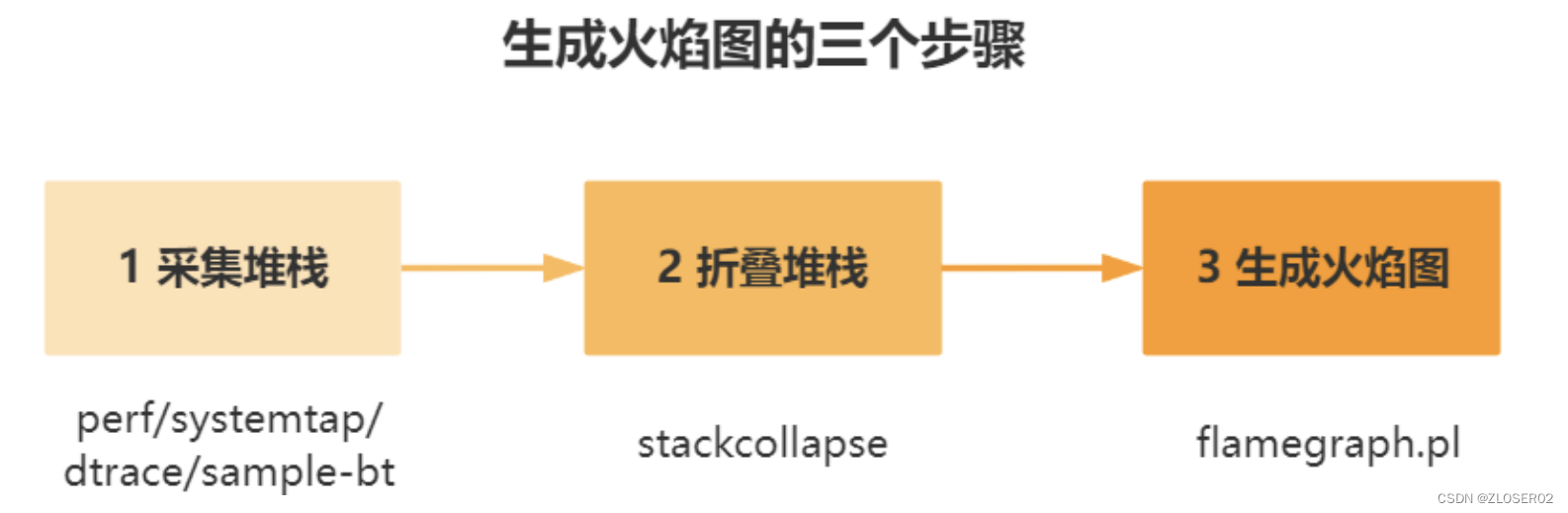
1.生成火焰图的三个步骤
安装火焰图必备工具
1.安装火焰图FlameGraph脚本
1.Brendan D. Gregg 的 Flame Graph 工程实现了一套生成火焰图的脚本。Flame Graph 项目位于 GitHub上:git clone https://github.com/brendangregg/FlameGraph.git
2.使用码云gitee的链接:git clone https://gitee.com/mirrors/FlameGraph.git
用 git 将其 clone下来
记住git clone时 FlameGraph 的路径,绘制火焰图时需要
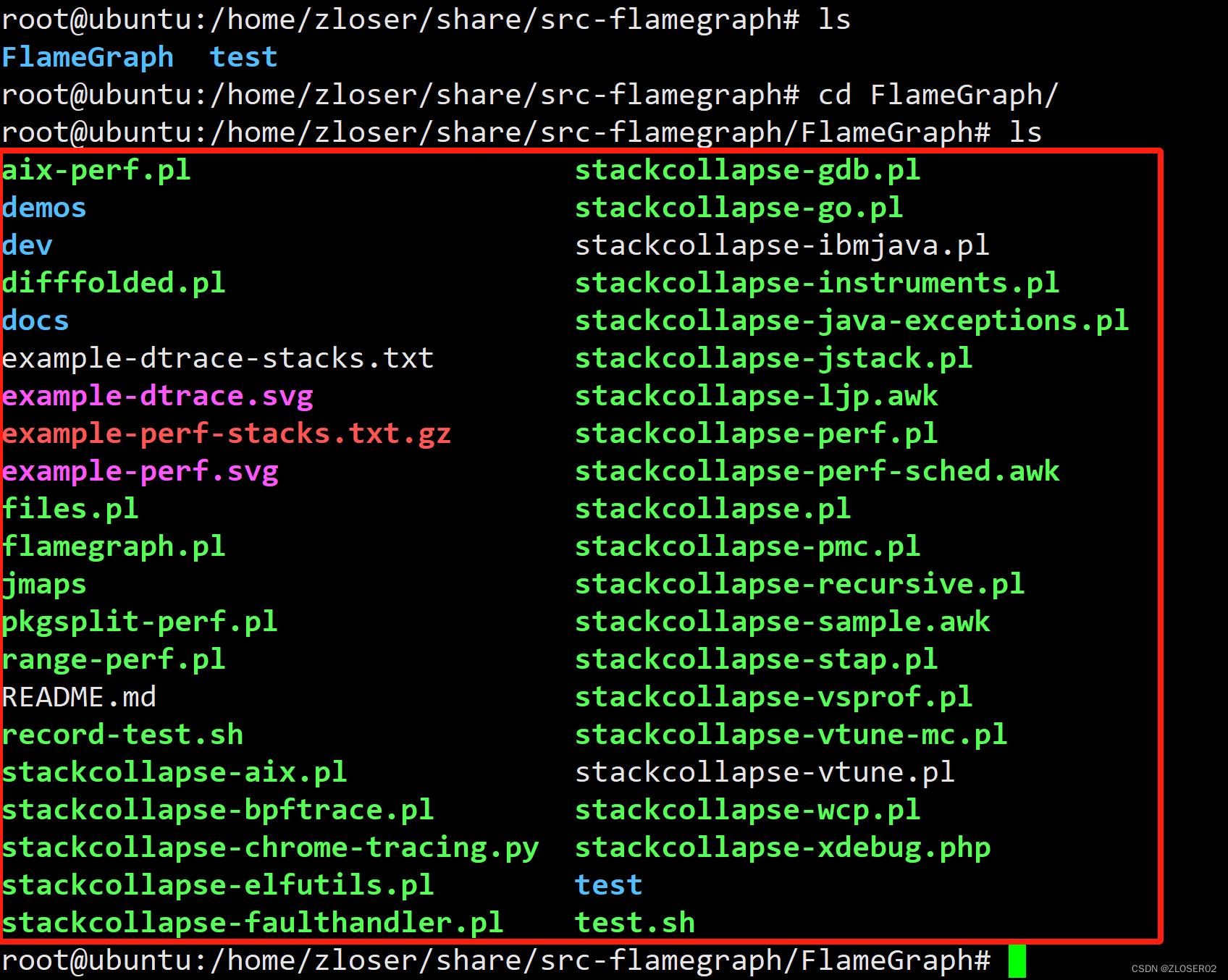
不同的 trace 工具抓取到的信息不同, 因此 Flame Graph 提供了一系列的 stackcollapse(堆栈折叠) 工具.
查看帮助 ./FlameGraph/flamegraph.pl -h==
2.安装火焰图数据采集工具perf
1.系统级性能优化通常包括两个阶段:性能剖析(performance profiling)和代码优化:
(1).性能剖析的目标是寻找性能瓶颈,查找引发性能问题的原因及热点代码。
(2).代码优化的目标是针对具体性能问题而优化代码或编译选项,以改善软件性能。一般在工作中比较关心的是性能瓶颈,特别是算法。
2.当在系统全功能启动的时候,算法一般需要将设备的性能用到极限,而在这个过程中不免出现各类性能上的瓶颈,此时需要分析自身的一些性能瓶颈在什么地方就可以用到专门的性能分析工具perf。
3.perf 命令(performance profiling的缩写), 它是 Linux 系统原生提供的性能分析工具, 会返回 CPU 正在执行的函数名以及调用栈(stack)
具体用法:
perf Examples
Linux kernel profiling with perf
Linux Performance (brendangregg.com)
perf的原理:
每隔一个固定的时间,就在CPU上(每个核上都有)产生一个中断,在中断上看看,当前是哪个pid,哪个函数,然后给对应的pid和函数加一个统计值,这样,我们就知道CPU有百分几的时间在某个pid,或者某个函数上了。
这个原理图示如下:1秒采集99次,1秒采集1000次(采样次数越高容易影响程序性能)
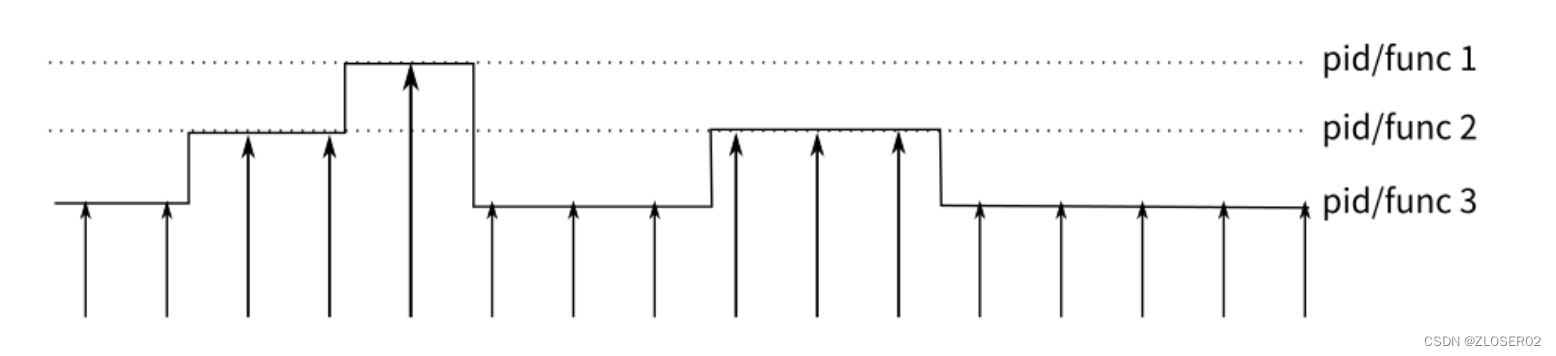
很明显可以看出,这是一种采样的模式,预期:运行时间越多的函数,被时钟中断击中的机会越大,从而推测,那个函数(或者pid等)的CPU占用率就越高。
这种方式可以推广到各种事件,比如ftrace的事件,你可以在这个事件发生的时候上来冒个头,看看击中了谁,然后算出分布,我们就知道谁会引发特别多的那个事件了。
当然,如果某个进程运气特别好,它每次都刚好躲过你发起探测的位置(这时候就需要考虑提高采样频率),你的统计结果可能就完全是错的了。这是所有采样统计都有可能遇到的问题了。
1. 安装perf
安装需要root权限(比如Ubuntu通过sudo su切换到root权限),perf 采集的时候也需要root的权限
apt install linux-tools-common
2. 测试perf是否可用
perf record -F 99 -a -g -- sleep 10
出现报错:
WARNING: perf not found for kernel 5.15.0-89
You may need to install the following packages for this specific kernel:
linux-tools-5.15.0-89-generic
linux-cloud-tools-5.15.0-89-genericYou may also want to install one of the following packages to keep up to date:
linux-tools-generic
linux-cloud-tools-generic
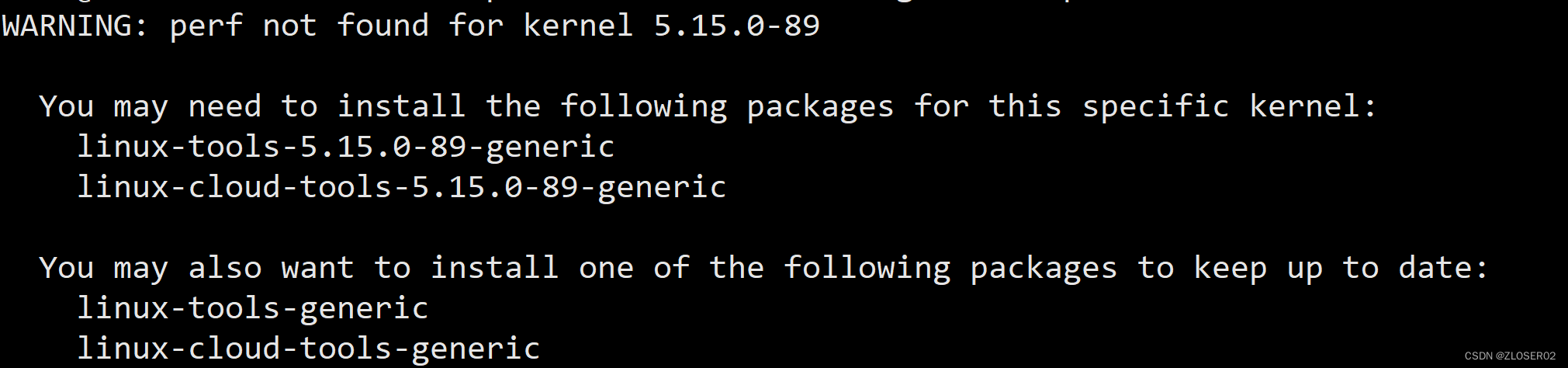
则需要安装linux-tools-generic和linux-cloud-tools-generic,但需选择对应的版本,比如提示的是5.15.0-89,则我们安装5.15.0-89版本:
apt-get install linux-tools-4.15.0-48-generic linux-cloud-tools-4.15.0-48-generic linux-tools-generic linux-cloud-tools-generic
再次测试 perf record -F 99 -a -g -- sleep 10
如果没有报错则在执行测试命令的目录产生 perf.data 文件
3. perf常用命令
查看帮助文档,perf功能非常强大,我们这里只关注record和report功能,record和report也可以继续通过二级命令查询帮助文档。
perf -h
usage: perf [--version] [--help] [OPTIONS] COMMAND [ARGS]
The most commonly used perf commands are:
annotate Read perf.data (created by perf record) and display annotated code
archive Create archive with object files with build-ids found in perf.data file
bench General framework for benchmark suites
buildid-cache Manage build-id cache.
buildid-list List the buildids in a perf.data file
c2c Shared Data C2C/HITM Analyzer.
config Get and set variables in a configuration file.
daemon Run record sessions on background
data Data file related processing
diff Read perf.data files and display the differential profile
evlist List the event names in a perf.data file
ftrace simple wrapper for kernel's ftrace functionality
inject Filter to augment the events stream with additional information
iostat Show I/O performance metrics
kallsyms Searches running kernel for symbols
kmem Tool to trace/measure kernel memory properties
kvm Tool to trace/measure kvm guest os
list List all symbolic event types
lock Analyze lock events
mem Profile memory accesses
record Run a command and record its profile into perf.data
report Read perf.data (created by perf record) and display the profile
sched Tool to trace/measure scheduler properties (latencies)
script Read perf.data (created by perf record) and display trace output
stat Run a command and gather performance counter statistics
test Runs sanity tests.
timechart Tool to visualize total system behavior during a workload
top System profiling tool.
version display the version of perf binary
probe Define new dynamic tracepoints
trace strace inspired tool
See 'perf help COMMAND' for more information on a specific command.
常用的五个命令:
perf list:查看当前软硬件环境支持的性能事件
perf stat:分析指定程序的性能概况
perf top:实时显示系统/进程的性能统计信息
perf record:记录一段时间内系统/进程的性能事件
perf report:读取perf record生成的perf.data文件,并显示分析数据(生成火焰图用的采集命令)
perf record -h
常用命令
-e :指定性能事件(可以是多个,用,分隔列表)
-p :指定待分析进程的 pid(可以是多个,用,分隔列表, nginx , -p 100,101,102,103)
-t :指定待分析线程的 tid(可以是多个,用,分隔列表)
-u :指定收集的用户数据,uid为名称或数字
-a:从所有 CPU 收集系统数据
-g:开启 call-graph (stack chain/backtrace) 记录(backtrace调试功能的实现原理就是利用函数调用
栈中的信息来追踪程序执行的路径和调用关系。)
-C :只统计指定 CPU 列表的数据,如:0,1,3或1-2
-r :perf 程序以SCHED_FIFO实时优先级RT priority运行这里填入的数值越大,进程优先级越高(即
nice 值越小)
-c : 事件每发生 count 次采一次样
-F :每秒采样 n 次
-o <output.data>:指定输出文件output.data,默认输出到perf.data
perf report -h
-i, --input input file name,可以指定要分析的文件名,默认perf.data
生成火焰图实践示例
我们需要先写个简单的测试程序,分main、func_a、func_b、func_c、func_d 5个函数:
main: 调用func_a、func_b、func_c
func_a:调用func_d
这里的目的是演示宽度对应函数占用的cpu时间。
1.编译和执行测试程序
源码:test.c
#include <stdio.h>
void func_d()
{
for (int i = 5 * 10000; i--;);
}
void func_a()
{
for (int i = 10 * 10000; i--;);
func_d();
}
void func_b()
{
for (int i = 20 * 10000; i--;);
}
void func_c()
{
for (int i = 35 * 10000; i--;);
}
int main(void)
{
printf("main into\n");
while (1)
{
for (int i = 30 * 10000; i--;);
func_a();
func_b();
func_c();
}
printf("main end\n");
return 0;
}
该程序用于生成测试程序。
编译:gcc -o test test.c
执行:./test

2. perf 采集数据
通过top指令查看test的pid:perf record -F 99 -p 42850 -g -- sleep 30
perf record 表示采集系统事件, 没有使用 -e 指定采集事件, 则默认采集 cycles(即 CPU clock 周期), -F 99 表示每秒 99 次,-p 42850 是进程号, 即对哪个进程进行分析, -g 表示记录调用栈, sleep 30 则是持续 30 秒.
-F 指定采样频率为 99Hz(每秒99次), 如果 99次 都返回同一个函数名, 那就说明 CPU 这一秒钟都在执行同一个函数, 可能存在性能问题.
为了便于阅读, perf record 命令可以统计每个调用栈出现的百分比, 然后从高到低排列.
perf report -n --stdio
通过 perf report 命令可以展示采样记录,大概介绍下面板参数:
Samples:采样个数
Event count:系统总共发生的事件数
Symbol:函数名,其中 [.] 表示用户空间函数,[k] 表示内核函数
Shared Objec:函数所在的共享库或所在的程序
Command:进程名
Self:该函数的 CPU 使用率
Children:该函数的子函数的 CPU 使用率
# To display the perf.data header info, please use --header/--header-only options.
#
#
# Total Lost Samples: 0
#
# Samples: 2K of event 'cpu-clock:pppH'
# Event count (approx.): 29808080510
#
# Children Self Samples Command Shared Object Symbol >
# ........ ........ ............ ....... ................. .....................>
#
100.00% 0.00% 0 test libc.so.6 [.] 0x00007f05395b6d90
|
---0x7f05395b6d90
main
|
|--34.80%--func_c
|
|--20.70%--func_b
|
--14.33%--func_a
|
--5.05%--func_d
100.00% 30.13% 889 test test [.] main
|
|--69.87%--main
| |
| |--34.80%--func_c
| |
| |--20.70%--func_b
| |
| --14.33%--func_a
| |
| --5.05%--func_d
|
--30.13%--0x7f05395b6d90
main
34.80% 34.73% 1025 test test [.] func_c
|
--34.73%--0x7f05395b6d90
main
func_c
20.70% 20.67% 610 test test [.] func_b
|
--20.67%--0x7f05395b6d90
main
func_b
14.33% 9.28% 274 test test [.] func_a
|
|--9.28%--0x7f05395b6d90
| main
| func_a
|
--5.05%--func_a
func_d
5.05% 5.05% 149 test test [.] func_d
|
---0x7f05395b6d90
main
func_a
func_d
3.折叠堆栈
- 首先用perf script 工具对 perf.data 进行解析
生成折叠后的调用栈:perf script -i perf.data &> perf.unfold

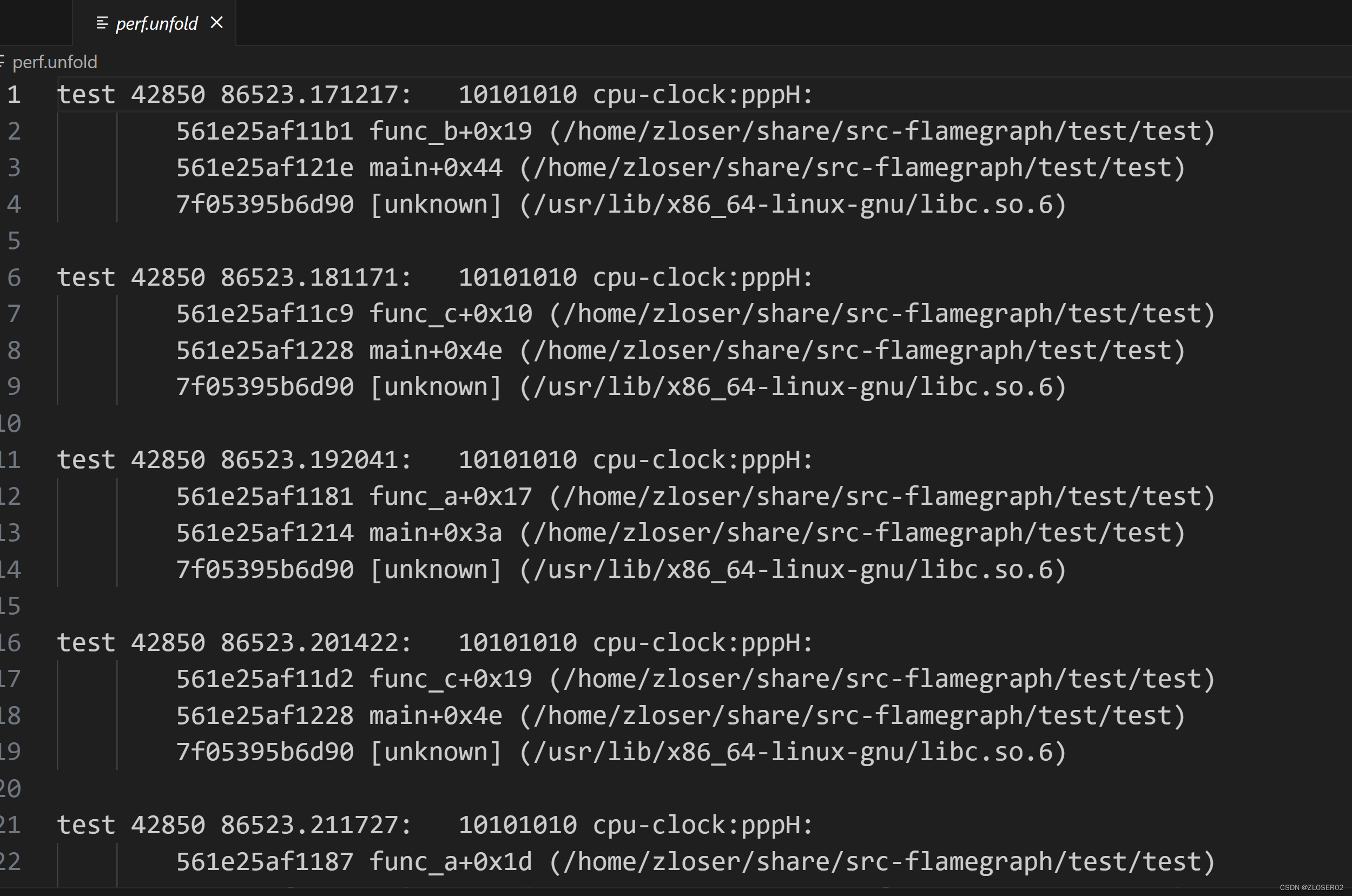
- 然后将解析出来的信息存下来, 供生成火焰图
用 stackcollapse-perf.pl 将 perf 解析出的内容 perf.unfold 中的符号进行折叠 :./FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded
注意: ./FlameGraph/stackcollapse-perf.pl路径为自己的路径,根据自己的情况进行修改
#生成火焰图需要的统计信息
4.生成火焰图
最后生成 svg 图-绘制火焰图:
注意: ./FlameGraph/flamegraph.pl路径为自己的路径,根据自己的情况进行修改
./FlameGraph/flamegraph.pl perf.folded > test_oncpu.svg
我们也可以使用管道将上面的流程简化为一条命令:
注意: ./FlameGraph/stackcollapse-perf.pl路径为自己的路径,根据自己的情况进行修改
perf script | ./FlameGraph/stackcollapse-perf.pl | ./FlameGraph/flamegraph.pl > test_oncpu.svg
perf script默认是输入perf.data,如果需要指明输入数据用perf script -i xxx
5.解析火焰图含义
最后就可以用浏览器打开火焰图进行分析啦.

火焰图是基于 stack 信息生成的 SVG 图片, 用来展示 CPU 的调用栈。
1.y 轴表示调用栈, 每一层都是一个函数. 调用栈越深, 火焰就越高, 顶部就是正在执行的函数, 下方都是它的父函数.
2.x 轴表示抽样数, 如果一个函数在 x 轴占据的宽度越宽, 就表示它被抽到的次数多, 即执行的时间长. 注意,x 轴不代表时间, 而是所有的调用栈合并后, 按字母顺序排列的.
3.火焰图就是看顶层的哪个函数占据的宽度最大. 只要有 “平顶”(plateaus), 就表示该函数可能存在性能问题。
4.颜色没有特殊含义, 因为火焰图表示的是 CPU 的繁忙程度, 所以一般选择暖色调.