目录
2.2.8.RELEASE(支持spring boot2.3.12.RELEASE)
1版本关系
本文章Spring Boot与Spring Cloud版本参见下面完整的pom.xml:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupID>org.springframework.boot</groupID>
<artifactID>spring-boot-starter-parent</artifactID>
<version>2.3.12.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupID>com.example</groupID>
<artifactID>spring-cloud-sleuth-demo1</artifactID>
<version>0.0.1-SNAPSHOT</version>
<name>spring-cloud-sleuth-demo1</name>
<description></description>
<properties>
<java.version>1.8</java.version>
<!--spring cloud要与spring boot版本兼用-->
<release.train.version>Hoxton.SR12</release.train.version>
</properties>
<dependencies>
<dependency>
<groupID>org.springframework.boot</groupID>
<artifactID>spring-boot-starter-web</artifactID>
</dependency>
<dependency>
<groupID>org.springframework.boot</groupID>
<artifactID>spring-boot-starter-test</artifactID>
<scope>test</scope>
</dependency>
<dependency>
<groupID>org.springframework.cloud</groupID>
<artifactID>spring-cloud-starter-sleuth</artifactID>
</dependency>
<dependency>
<groupID>org.springframework.cloud</groupID>
<artifactID>spring-cloud-starter-zipkin</artifactID>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupID>org.springframework.cloud</groupID>
<artifactID>spring-cloud-dependencies</artifactID>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupID>org.springframework.boot</groupID>
<artifactID>spring-boot-maven-plugin</artifactID>
</plugin>
</plugins>
</build>
</project>Spring Cloud要与Spring Boot版本兼容才行,你不会忘了吧。
您可以在Spring官方文档中查看Spring Boot和Spring Cloud的版本兼容性。具体网址为:Spring Cloud 下方有一张Matrix表格,列出了每个版本的Spring Boot和Spring Cloud之间的兼容性。
您可以在Spring Boot官方文档中查看Spring Boot版本和Java版本的依赖关系。具体地,可以阅读“System Requirements”小节,其中列出了每个Spring Boot版本所需要的Java JDK版本。具体文档网址为:Spring Boot Reference Documentation
| Spring Cloud | Spring Boot |
|---|---|
| 2022.0.x aka Kilburn | 3.0.x |
| 2021.0.x aka Jubilee | 2.6.x, 2.7.x (Starting with 2021.0.3) |
| 2020.0.x aka Ilford | 2.4.x, 2.5.x (Starting with 2020.0.3) |
| Hoxton | 2.2.x, 2.3.x (Starting with SR5) |
| Greenwich | 2.1.x |
| Finchley | 2.0.x |
| Edgware | 1.5.x |
| Dalston | 1.5.x |
| Spring Boot | Servlet Name | Servlet Version | Java Version |
|---|---|---|---|
| 1.5.x | Tomcat 8 | 3.1 | Java 7 |
| 1.5.x | Tomcat 7 | 3 | Java 6 |
| 1.5.x | Jetty 9.3 | 3.1 | Java 8 |
| 1.5.x | Jetty 9.2 | 3.1 | Java 7 |
| 1.5.x | Jetty 8 | 3 | Java 6 |
| 1.5.x | Undertow 1.3 | 3.1 | Java 7 |
| 2.0.x | Tomcat 8.5 | 3.1 | Java 8/9 |
| 2.0.x | Jetty 9.4 | 3.1 | Java 8/9 |
| 2.0.x | Undertow 1.4 | 3.1 | Java 8/9 |
| 2.1.x | Tomcat 9.0 | 4 | Java 8 |
| 2.1.x | Jetty 9.4 | 3.1 | Java 8 |
| 2.1.x | Undertow 2.0 | 4 | Java 8 |
| 2.2.x | Tomcat 9.0 | 4 | Java 8 |
| 2.2.x | Jetty 9.4 | 3.1 | Java 8 |
| 2.2.x | Undertow 2.0 | 4 | Java 8 |
| 2.3.x | Tomcat 9.0 | 4 | Java 8 |
| 2.3.x | Jetty 9.4 | 3.1 | Java 8 |
| 2.3.x | Undertow 2.0 | 4 | Java 8 |
| 2.4.x | Tomcat 9.0 | 4 | Java 8 |
| 2.4.x | Jetty 9.4 | 3.1 | Java 8 |
| 2.4.x | Undertow 2.0 | 4 | Java 8 |
| 2.5.x | Tomcat 9.0 | 4 | Java 8 |
| 2.5.x | Jetty 9.4 | 3.1 | Java 8 |
| 2.5.x | Jetty 10.0 | 4 | Java 8 |
| 2.5.x | Undertow 2.0 | 4 | Java 8 |
| 2.6.x | Tomcat 9.0 | 4 | Java 8 |
| 2.6.x | Jetty 9.4 | 3.1 | Java 8 |
| 2.6.x | Jetty 10.0 | 4 | Java 8 |
| 2.6.x | Undertow 2.0 | 4 | Java 8 |
| 2.7.x | Tomcat 9.0 | 4 | Java 8 |
| 2.7.x | Jetty 9.4 | 3.1 | Java 8 |
| 2.7.x | Jetty 10.0 | 4 | Java 8 |
| 2.7.x | Undertow 2.0 | 4 | Java 8 |
| 3.0.x | Tomcat 10.0 | 5 | Java 17 |
| 3.0.x | Jetty 11.0 | 5.1 | Java 17 |
| 3.0.x | Undertow 2.2 (Jakarta EE 9 variant) | 5 | Java 17 |
2简介
Spring Cloud Sleuth是一个分布式跟踪解决方案,它通过生成和管理跨越多个微服务的唯一标识符来协助在分布式系统中精确定位调用链路,帮助开发者更快地定位和解决分布式系统中的问题。此外,Sleuth还支持集成Zipkin等流行的分布式跟踪系统,使得跨越不同微服务的跟踪和调试更加方便。
Spring Cloud Sleuth支持以下协议的跟踪:
-
HTTP:支持HTTP协议下的服务调用跟踪,包括HTTP请求和响应。
-
JMS:支持Java Message Service(JMS)协议下的消息发送和接收跟踪。
-
Kafka:支持Apache Kafka消息系统下的消息发送和接收跟踪。
-
RabbitMQ:支持RabbitMQ消息系统下的消息发送和接收跟踪。
-
gRPC:支持gRPC远程过程调用(RPC)协议下的跟踪。
-
Dubbo:支持阿里巴巴开源的Dubbo分布式服务框架下的调用跟踪。
通过支持这些协议的跟踪,Spring Cloud Sleuth可以帮助开发者在分布式系统中更全面地获取服务调用信息和性能指标,从而更好地诊断和解决各种分布式系统中的问题。
2.1术语
Spring Cloud Sleuth借用了戴珀的术语。
Span:工作的基本单位。例如,发送RPC是一个新的范围,发送响应到RPC也是一个新的范围。Spans由一个唯一的64位ID标识,另一个64位ID标识该Span所属的跟踪。Spans还有其他数据,如描述、时间戳事件、键值注释(标记)、引起它们的Span的ID和进程ID(通常是IP地址)。
Span可以启动和停止,并且可以跟踪它们的计时信息。一旦创建了Span,就必须在将来的某个时候停止它。
开始跟踪的初始范围称为根范围。该Span的ID值等于Trace ID。
Trace:一组形成树形结构的Spans。例如,如果您运行分布式大数据存储,则可能由PUT请求形成跟踪。
Annotation:用于记录事件在时间上的存在。使用Brave工具,我们不再需要为Zipkin设置特殊事件来了解客户端和服务器是谁,请求从哪里开始以及在哪里结束。然而,出于学习的目的,我们标记这些事件以突出显示发生了什么样的操作。
cs:Client Sent:客户已经提出请求。该Annotation指示Span的开始。
sr: Server Received:服务器端收到请求并开始处理。从这个时间戳中减去cs时间戳,可以得到网络延迟。
ss:Server Sent:在请求处理完成时进行Annotated(当响应被发送回客户机时)。从这个时间戳中减去sr时间戳可以得到服务器端处理请求所需的时间。
cr:Client Received:表示Span的结束。客户端已成功接收到来自服务器端的响应。从这个时间戳中减去cs时间戳,可以得到客户机从服务器接收响应所需的全部时间。
下图显示了Span和Trace在系统中的外观,以及Zipkin Annotations:

符号的每一种颜色表示一个Span(从A到G共有7个Span)。
下图显示了Spans的父子关系:
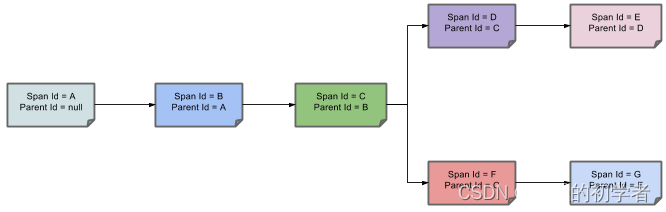
上图中的TraceId = X,Span Id = C为SERVICE2的自定义Span。
2.2调用链可视化
2.2.1使用Zipkin进行分布式跟踪
可以在Zipkin的Web页面看到调用链的跟踪记录与每个Trace的树形结构。


2.2.2错误可视化
Zipkin让您可视化跟踪中的错误。当抛出一个异常并且没有被捕获时,我们在Span上设置适当的标记,然后Zipkin可以正确地为其着色。您可以在Trace列表中看到一个红色的Trace。这是因为抛出了异常。
如果单击该Trace,将看到类似的图片,如下所示:

然后单击其中一个Span,将看到以下内容

Span显示了错误的原因以及与之相关的整个堆栈跟踪。
2.2.3使用Brave进行分布式跟踪
从2.0.0版本开始,Spring Cloud Sleuth使用Brave作为跟踪库。因此,Sleuth不再负责存储上下文,而是将工作委托给Brave。
由于Sleuth的命名和标签惯例与Brave不同,所以我们决定从现在开始遵循Brave的惯例。但是,如果您想使用遗留的Sleuth方法,您可以将spring.sleuth.http.legacy.enabled属性设置为true。
2.2.4将Sleuth添加到项目中
-
Sleuth通过HTTP集成Zipkin
参考上述“1版本关系”中的pom.xml。
application.proterties中添加配置项:
spring.zipkin.base-url=http://127.0.0.1:9411/spring.zipkin.base-url配置用于指定Zipkin服务器的地址,Zipkin是一个开源分布式跟踪系统,用于收集分布式系统的跟踪数据。通过配置该属性,我们可以让我们的应用程序知道Zipkin服务器的位置。这样,我们就可以轻松地将我们的跟踪数据发送到Zipkin服务器上,并在Zipkin的UI中查看分布式系统的跟踪数据。
3调用信息生成与上报原理
3.1初始化配置类
-
SleuthWebProperties
SleuthWebProperties 类是 Spring Cloud Sleuth 中定义的一个配置属性类,主要用于配置 Sleuth Web 相关的属性,如目标 URI 的网络位置、远程调用是否启用跟踪、是否启用过滤器、请求头的名称等。
SleuthWebProperties 类中定义了多个属性,其中一些被其他 Sleuth Web 配置类使用,如 CloseSpanAfterResponseWebFilterProperties、TraceWebServletAutoConfiguration、TraceWebFluxAutoConfiguration、TraceWebClientAutoConfiguration 等。
这些属性包括:
-
enabled:是否开启 Sleuth Web Filter 过滤器。
-
additionalRemoteFields:存储过程/方法出口、出口名称和端口等信息。
-
skipPattern:是否跳过指定的 URL 地址。
-
client:WebClient 客户端的配置属性。
-
exclude:排除某些请求头,避免在分布式链路追踪中影响结果。
通过使用 SleuthWebProperties 类能够为 WebFlux 和 WebClient 对象的跟踪记录提供统一的配置,从而保证配置的正确性和合理性。开发人员也可在需要的情况下通过自定义 SleuthWebProperties 类来进行定制。
-
-
TraceHttpAutoConfiguration
该配置类注册了:
-
HttpTracing实例:Spring Cloud Sleuth中的“HttpTracing”类负责配置和提供一个可以用来跟踪HTTP请求的“Tracing”实例。
在跟踪HTTP请求时,Sleuth捕获有关请求及其交互的上游和下游服务的信息。此信息用于创建可用于诊断应用程序性能或行为问题的跟踪。“HttpTracing”类提供了一种方便的方式来配置和创建一个用于HTTP请求的“Tracing”实例。
“HttpTracing”类提供了配置“Tracing”实例的方法,包括指定“Sampler”的能力。和TraceId128Bit设置。它还提供了创建“HttpClient”和“HttpServer”实例的方法,这些实例被预先配置为使用“Tracing”实例。
“Sampler”能力指的是调用链的采样能力,类中的“HttpSampler”用于对分布式跟踪的http请求和响应进行采样。它提供了一种捕获有关HTTP请求和响应的信息的方法,例如请求和响应头、请求和响应体以及响应状态码。然后可以使用此信息生成跟踪,显示请求如何流经系统,包括处理请求所涉及的任何上游和下游服务。 ' HttpSampler '类提供了创建' HttpClient '和' HttpServer '实例的方法,这些实例被预先配置为使用' Tracing '实例。它还提供了创建“SpanCustomizer”实例的方法,这些实例可用于自定义为特定HTTP请求创建的span。
-
SleuthHttpClientParser实例
' HttpRequestParser '接口和它在' brave. js '中的实现类。Brave库的http '包用于解析http请求并提取相关信息用于分布式跟踪。接口定义了一个方法,' parse ',它接受一个' HttpAdapter '实例和一个' HttpRequest '实例作为参数,并返回一个' SpanCustomizer '实例,该实例可用于自定义为HTTP请求创建的span。 “HttpRequestParser”接口有几个实现类,每个类都被设计用来解析特定格式的HTTP请求。例如,' HttpServerRequestParser '类用于解析服务器接收的HTTP请求,而' HttpClientRequestParser '类用于解析客户端发送的HTTP请求。这些类从HTTP请求中提取诸如请求方法、URL、标头和查询参数等信息,并使用这些信息创建表示请求的范围。
SleuthHttpClientParser '类负责解析客户端发送的HTTP请求,并为分布式跟踪提取相关信息。它是' HttpClientParser '接口的实现,该接口用于解析HTTP请求和响应以进行分布式跟踪。
在跟踪HTTP请求时,Sleuth捕获有关请求及其交互的上游和下游服务的信息。' SleuthHttpClientParser '类从HTTP请求中提取诸如请求方法、URL、报头和查询参数等信息,并使用这些信息创建一个表示请求的Span。然后可以使用这个范围来生成显示请求如何流经系统的跟踪。
-
SleuthHttpServerParser实例
参照SleuthHttpClientParser实例介绍。
-
-
TraceAutoConfiguration
它提供了一组用于跟踪的默认配置,用户可以根据需要自定义这些配置。
“TraceAutoConfiguration”类配置一个“Tracer”bean,它用于创建和管理分布式跟踪的Span。它还配置了一个' SpanReporter ' bean,负责向Zipkin等跟踪系统报告Span。默认情况下,Sleuth使用Brave跟踪库并支持向Zipkin报告,但这可以自定义为使用其他跟踪库或报告系统。
除了配置“Tracer”和“SpanReporter”bean之外,“TraceAutoConfiguration”类还提供了许多其他配置选项,例如自定义跟踪的采样率,从跟踪中排除某些路径或端点,以及自定义与Span相关的标记。
-
ZipkinRestTemplateSenderConfiguration
ZipkinRestTemplateSenderConfiguration '类负责在Spring Boot应用程序中配置和启用Zipkin REST模板发送器。它提供了一组默认配置,用于通过HTTP向Zipkin服务器发送Span,用户可以根据需要自定义这些配置。
' ZipkinRestTemplateSenderConfiguration '类配置一个' RestTemplate ' bean,它用于通过HTTP向Zipkin服务器发送Span。它还配置了一个' ZipkinSpanReporter ' bean,它负责使用' RestTemplate '向Zipkin服务器报告Span。
除了配置' RestTemplate '和' ZipkinSpanReporter ' bean之外,' ZipkinRestTemplateSenderConfiguration '类还提供了许多其他配置选项,例如为Zipkin服务器自定义端点URL的能力,为' RestTemplate '设置连接超时,以及自定义与Span一起发送的HTTP头。
-
其他
配置了一些用于跟踪HTTP请求的bean,包括' TracingFilter ', ' HttpTraceHandler ', ' HttpTraceRepository '和' HttpTraceChannelBinder '。这些bean一起工作以捕获关于传入HTTP请求和传出HTTP响应的信息,并使用该信息创建和管理用于分布式跟踪的范围。
3.2过滤器-请求过滤
过滤器TracingFilter
-
获取TraceContext属性
TraceContext context = (TraceContext) request.getAttribute(TraceContext.class.getName());TraceContext用于表示分布式跟踪的上下文,TraceContext类提供了一种在系统的不同组件之间存储和传播跟踪信息的方法。TraceContext类包含trace和span ID、父span ID和采样决策等信息。此信息可用于关联不同的请求并了解通过系统的请求流。
-
TraceContext不为null,执行过滤器do.Filter(...)方法,执行下一个过滤器。
-
TraceContext为null
- 创建Span
Span span = handler.handleReceive(new HttpServletRequestWrapper(req)); - 显示添加属性
request.setAttribute(SpanCustomizer.class.getName(), span.customizer()); request.setAttribute(TraceContext.class.getName(), span.context()); SendHandled sendHandled = new SendHandled(); request.setAttribute(SendHandled.class.getName(), sendHandled); -
过滤器放行
- 创建Span
3.3调用信息拦截
拦截器SpanCustomizingAsyncHandlerInterceptor
-
获取span信息
@Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object o) { Object span = request.getAttribute(SpanCustomizer.class.getName()); if (span instanceof SpanCustomizer) handlerParser.preHandle(request, o, (SpanCustomizer) span); return true; } - 请求对象添加错误和路线属性
@Override public void afterCompletion( HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) { Object span = request.getAttribute(SpanCustomizer.class.getName()); if (span instanceof SpanCustomizer) { setErrorAttribute(request, ex); setHttpRouteAttribute(request); } }
3.4调用信息上报
过滤器TracingFilter
-
上报响应信息
// we have a synchronous response or error: finish the span HttpServerResponse responseWrapper = HttpServletResponseWrapper.create(req, res, error); handler.handleSend(responseWrapper, span); - 上报流程为
handler.handleSend(responseWrapper, span);-> span.finish();-> finish(0L);-> pendingSpans.finish(context, timestamp);-> spanHandler.end(last.handlerContext, last.span, Cause.FINISHED);-> spanReporter.report(span);-> delegate.report(converted);-> AsyncReporter.report(S next)-> startFlusherThread()(开启上报守护线程,第一次上报开启,该线程一直运行。)-> result.flush(consumer);(守护线程上报)-> sender.sendSpans(nextMessage).execute();-> execute();-> doExecute()-> post(this.message);-> restTemplate.exchange(requestEntity, String.class);
4日志配置
4.1application.propertes配置
单纯的Spring Boot项目,没有集成Spring Cloud Sleuth,默认的日志格式没有MDC信息,日志级别为INFO,示例:
2023-06-07 16:47:49.478 INFO 26496 --- [ main] c.e.s.SpringCloudSleuthDemo2Application : Started SpringCloudSleuthDemo2Application in 1.347 seconds (JVM running for 2.429)引入Sping Cloud Sleuth后,日志格式携带MDC信息,日志级别为INFO,示例:
2023-06-07 16:49:20.663 INFO [server2,,,] 19752 --- [ main] c.e.s.SpringCloudSleuthDemo2Application : Started SpringCloudSleuthDemo2Application in 3.978 seconds (JVM running for 4.775)但是日志级别为INFO,控制台无法记录TraceID、SpanID信息,可以在application.properties中添加日志级别配置:
logging.level.org.springframework.web.servlet.DispatcherServlet=debug控制台日志信息包括MDC完整信息:
2023-06-07 16:52:28.203 DEBUG [server2,4a4ef04528a551e3,4a4ef04528a551e3,true] 29612 --- [nio-8081-exec-1] o.s.web.servlet.DispatcherServlet : GET "/sleuth/hello", parameters={}
2023-06-07 16:52:28.234 DEBUG [server2,4a4ef04528a551e3,4a4ef04528a551e3,true] 29612 --- [nio-8081-exec-1] o.s.web.servlet.DispatcherServlet : Completed 200 OK日志MDC信息显示traceId或者spanId等信息。
-
在Spring Cloud Sleuth中,MDC默认记录[appname,traceId,spanId,exportable]:
-
appname:记录Span的应用程序的名称。
-
traceId:包含span的延迟图的ID。
-
spanId:发生的特定操作的ID。
-
exportable:是否将日志导出到Zipkin。
4.2logback-spring.xml配置
当然,你也可以通过自定义logback-spring.xml配置文件的方式,可以将日志输出到指定路径指定文件中,日志也可以输出为JSON格式。
输出JSON格式需要添加pom依赖:
<dependency>
<groupID>net.logstash.logback</groupID>
<artifactID>logstash-logback-encoder</artifactID>
<version>6.6</version>
</dependency>参考下面的logback-spring.xml配置:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<!-- You can overrIDe this to have a custom pattern -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs-->
<level>DEBUG</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file -->
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file in a JSON format -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<provIDers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"timestamp": "@timestamp",
"severity": "%level",
"service": "${springAppName:-}",
"Trace": "%X{TraceID:-}",
"Span": "%X{SpanID:-}",
"Baggage": "%X{key:-}",
"pID": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</provIDers>
</encoder>
</appender>
<springProfile name="logzio">
<!-- Use shutdownHook so that we can close gracefully and finish the log drain -->
<shutdownHook class="ch.qos.logback.core.hook.DelayingShutdownHook"/>
<appender name="LogzioLogbackAppender" class="io.logz.logback.LogzioLogbackAppender">
<token>${LOGZ_IO_API_TOKEN}</token>
<logzioUrl>https://listener.logz.io:8071</logzioUrl>
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>INFO</level>
</filter>
<debug>true</debug>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<provIDers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"timestamp": "@timestamp",
"severity": "%level",
"service": "${springAppName:-}",
"Trace": "%X{TraceID:-}",
"Span": "%X{SpanID:-}",
"Baggage": "%X{key:-}",
"pID": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</provIDers>
</encoder>
</appender>
<root level="info">
<!-- IMPORTANT: make sure to include this line, otherwise the appender won't be used -->
<appender-ref ref="LogzioLogbackAppender"/>
</root>
</springProfile>
<root level="INFO">
<appender-ref ref="console"/>
<!-- uncomment this to have also JSON logs -->
<!--<appender-ref ref="logstash"/>-->
<!--<appender-ref ref="flatfile"/>-->
</root>
</configuration>将应用程序中的信息以JSON格式记录到build/${spring.application.name}. JSON文件中。
注释掉了两个附加附件:控制台和标准日志文件。
如果使用自定义logback-spring.xml,则必须在引导程序中传递spring.application.name,而不是应用程序属性文件。否则,您的自定义日志回显文件将无法正确读取该属性。
关于追踪日志的记录,我们在后续Spring Boot项目集成时候具体代码演示。
Logback官方网站是 Logback Home,该网站提供了一些示例、文档和源代码,可以帮助用户更好地了解和使用Logback框架。但是,对于Spring应用程序中的logback-spring.xml文件的详细解释和说明,可以参考Spring Boot官方文档 Core Features 以获取更加详细的解释和示例。
5Tracer、Tracing、Span
Trace ID和Span Id是使用HTTP头传播的。当向下游服务发出请求时,Trace ID和Span ID被添加到请求的HTTP头中。然后,下游服务可以从报头中提取这些ID,并使用它们继续跟踪。
5.1Tracer与Tracing
Tracer和Tracing都是Spring Cloud Sleuth提供的用于分布式跟踪的类。
Tracer是用于创建和管理Span对象的主要类。它提供了创建新的Span对象、设置Span对象的范围以及向Span对象添加跟踪信息的方法。
另一方面,Tracing是一个工厂类,用于创建Tracer对象和其他相关对象,如SpanCustomizer和CurrentTraceContext。它提供了用于配置它所创建的Tracer对象的行为的方法,例如采样率和被跟踪的服务的名称。
一般来说,在代码中使用Tracer对象比使用Tracing对象更频繁。跟踪器对象用于创建和管理Span对象,Span对象是用于通过应用程序跟踪请求的主要对象。
但是,跟踪对象对于配置跟踪器对象的行为仍然很重要。通过使用Tracing对象,您可以为Span对象设置采样率,这决定了跟踪请求的频率。您还可以设置正在跟踪的服务的名称,这对于区分分布式系统中的不同服务非常有用。
总之,Tracer是用于创建和管理Span对象的主要类,而Tracing是用于创建Tracer对象并配置其行为的工厂类。
Tracing用于创建和配置Tracer对象。通过将Tracing对象注入到Spring bean中,您可以根据需要使用它来创建和配置Tracer对象。
有几种情况下,你可能想使用@Autowired Tracing跟踪:
-
如果您需要使用自定义配置创建一个新的Tracer对象。通过向bean中注入一个Tracing对象,您可以使用它来创建一个具有自定义配置的新Tracer对象。例如,您可能希望将Tracer对象的采样率设置为特定值,或者您可能希望设置正在跟踪的服务的名称。
-
如果你需要使用SpanCustomizer来定制Span对象。SpanCustomizer是Spring Cloud Sleuth提供的一个接口,它允许您在Span对象启动之前对其进行定制。通过向bean中注入一个Tracing对象,您可以使用它来创建一个SpanCustomizer对象,该对象可用于定制Span对象。
-
如果您需要使用Tracing来访问其他相关对象。Tracing提供了对其他相关对象(如CurrentTraceContext和Propagation.Factory)的访问。这些对象可用于自定义Tracer对象的行为或访问不同上下文中的跟踪信息。
一般来说,当您需要创建或配置Tracer对象,或者需要访问由Tracing提供的其他相关对象时,您应该使用@Autowired Tracing跟踪。通过使用@Autowired Tracing跟踪,您可以利用Spring的依赖注入机制轻松地将Tracing对象注入到bean中,并根据需要使用它们。
5.2Span
观察Span源代码,Span为实现SpanCustomizer接口的抽象方法,其有三个子类:RealSpan、LazySpan和NoopSpan。
public abstract class Span implements SpanCustomizer {...}' RealSpan ', ' LazySpan '和' NoopSpan '是Spring Cloud Sleuth中不同类型的' Span '实现,每个都有自己的目的和行为。
' RealSpan ':这是Spring Cloud Sleuth中' Span '的默认实现。它表示正在被主动跟踪的真实“Span”。' RealSpan '用于捕获有关操作及其关联元数据的信息,例如服务的名称、操作的名称以及操作的开始和结束时间。“RealSpan”用于创建跨多个服务的操作跟踪。
' LazySpan ':这是Spring Cloud Sleuth中' Span '的轻量级实现。它用于表示尚未启动的“Span”。' LazySpan '是在请求' Span '但尚未启动时创建的,并且只有在执行跟踪操作时才启动。通过避免创建不必要的“Span”对象,这有助于减少跟踪的开销。
' NoopSpan ':这是Spring Cloud Sleuth中' Span '的无op实现。它用于表示已禁用或未被跟踪的“Span”。' NoopSpan '在禁用跟踪或请求' Span '但由于某种原因无法创建时使用。' NoopSpan '不捕获有关操作的任何信息,用于在不需要时避免跟踪的开销。
5.2.1SpanCustomizer
SpanCustomizer是Spring Cloud Sleuth提供的一个接口,它允许您在Span对象启动之前对其进行定制。
SpanCustomizer接口有几个方法,可用于向Span对象设置名称,添加Tags、日志(该版本Span不支持)和Baggage(该版本Span不支持setBaggage()方法)项。一些最常用的方法包括:
-
tag(String key, String value):为Span对象添加一个具有指定键和值的标签。
-
name(String name):为Span对象设置名称。
-
log(String event):将指定事件的日志添加到Span对象中(该版本Span不支持)。
-
log(long timestamp, String event):向Span对象添加具有指定时间戳和事件的日志(该版本Span不支持)。
-
setBaggageItem(String key, String value):在Span对象上设置一个具有指定键和值的行李项(该版本Span不支持)。
-
annotate(String value):为Span添加注释。
要使用SpanCustomizer,可以使用Spring的依赖注入机制将其注入到代码中。例如,如果你正在使用Spring Boot,你可以像这样注入SpanCustomizer到bean中:
@Component
public class MyBean {
private final Tracer tracer;
private final SpanCustomizer spanCustomizer;
public MyBean(Tracer tracer, SpanCustomizer spanCustomizer) {
this.tracer = tracer;
this.spanCustomizer = spanCustomizer;
}
public void myMethod() {
Span span = tracer.nextSpan().name("mySpan").start();
try (Tracer.SpanInScope ws = tracer.withSpanInScope(span)) {
spanCustomizer.tag("myTag", "tagValue");
// Your code here
} finally {
span.finish();
}
}
}在本例中,SpanCustomizer与Tracer一起被注入MyBean类。myMethod()方法使用trace . nextspan()创建一个新的Span对象,并将其名称设置为“mySpan”。然后使用SpanCustomizer对象向Span对象添加一个键为“myTag”,值为“tagValue”的标签。
通过使用SpanCustomizer,您可以使用与您的应用程序相关的附加信息来定制Span对象。这可以使在跟踪系统中搜索和分析Span对象变得更容易,并且可以为应用程序的行为提供有价值的见解。
5.2.2生命周期
-
start:当您启动一个span时,将分配它的名称并记录开始时间戳。
-
close:完成Span(记录Span的结束时间),如果对Span进行采样,则有资格进行收集(例如,收集到Zipkin)。
-
continue:创建一个新的span实例。它是它继续的那个的副本。
-
detach:Span不会停止或关闭。它只会从当前线程中移除。
-
create with explicit parent:您可以创建一个新的Span,并为它设置一个显式的父类。
5.3@NewSpan
@NewSpan注释用于在当前跟踪上下文中创建一个新的span。当此注释应用于方法时,Spring Cloud Sleuth将自动为该方法创建一个新的span,并将其添加到当前跟踪上下文中。
该注释可以应用于代码中的方法,以指示它们创建一个新的span。
@NewSpan("mySpan")
public void myMethod() {
// method logic
}当myMethod()方法被调用时,Spring Cloud Sleuth将创建一个名为“mySpan”的新span,并将其添加到当前跟踪上下文中。在myMethod()方法中进行的任何后续方法调用都将包含在该span中。
6数据传递
我这里创建了两个Spring Boot服务server1(localhost:8080)与server2(localhost:8081),用于下面的功能演示。
在Spring Cloud Sleuth中,“Span”表示正在跟踪的工作单元。它包含有关正在执行的操作的信息,例如服务的名称、操作的名称以及操作的开始和结束时间。除了这些基本信息之外,“Span”还可以包含Tag和Baggage。 Tag是键值对,提供关于“Span”的附加信息。它们可用于捕获诸如请求的HTTP状态码、所使用服务的版本或任何其他相关元数据之类的信息。标签由跟踪系统索引,可用于过滤和搜索跨度。 Baggage是一种在分布式跟踪中跨段之间传递数据的机制。它允许数据从一个' Span '传送到另一个' Span ',即使两个' Span '在不同的进程或不同的机器上。Baggage类似于Tag,但它是沿着跟踪上下文传播的,而不是由跟踪系统索引。 Tag和Baggage之间的主要区别在于,Tag用于提供关于' Span '的附加信息,而Baggage用于在跟踪中的' Span '之间传递数据。Tag由跟踪系统索引,可用于搜索和过滤Span,而Baggage没有索引,仅用于在“Span”之间携带数据。
Span上下文的一部分是Baggage,Trace和Span ID是Span上下文的必需部分,Baggage是可选的部分。
Baggage是存储在Span上下文中的一组键值对。Baggage随Trace一起移动,并附在每个Span上。
目前对Baggage的数量和大小没有限制。但是,太多会降低系统吞吐量或增加RPC延迟。在极端情况下,由于超出了传输级消息或报头容量,过多的Baggage可能导致应用程序崩溃。
设置Baggage希望Span在不同服务传播上下文信息的场景中非常有用。例如,如果您有一个分布式系统,其中涉及多个服务来处理请求,那么您可能希望将有关用户或请求本身的信息附加到Span中,所有服务进行关联Span。可以包括用户ID、请求ID或与请求处理相关的任何其他信息。通过将此信息附加到Span,您可以确保它在处理请求所涉及的所有服务之间传播,从而更容易关联和调试。
6.1Tag
为当前Span添加标签并在Zipkin根据标签搜索调用链,标签不会在Span中传递数据。
server1:
package com.example.springcloudsleuthdemo.controller;
import brave.Span;
import brave.Tracer;
import brave.propagation.ExtraFieldPropagation;
import brave.propagation.TraceContext;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.MDC;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
/**
* @Author yangruizeng
* @create 2023/6/5 20:26
* @Description TODO
*/
@RestController
public class SleuthController {
private static final Logger LOGGER = LoggerFactory.getLogger(SleuthController.class);
private static final String PREFIX_URL = "http://localhost:8081/sleuth/";
@Autowired
private RestTemplate restTemplate;
@Autowired
private Tracer tracer;
@GetMapping("/req/a")
public String reqA(){
/**
* trace.nextspan()和trace.currentspan()都是Spring Cloud Sleuth的Tracer类提供的方法。
* nextspan()创建一个新的Span对象并返回它。这个新的Span对象是当前Span对象的子对象(如果有的话)。
* 如果没有当前的Span对象,那么新的Span对象就是根Span对象。
* 另一方面,trace.currentspan()返回当前Span对象。如果当前没有Span对象,则trace.currentspan()返回null。
* 在提供的代码中,tracer.nextSpan()用于创建一个新的Span对象,并将其名称设置为“mySpan”。
* 然后启动这个新的Span对象,并使用try-with-resources块设置其作用域。在这个范围内,一个键为“myTag”,
* 值为“tagValue”的标签被添加到Span对象中。
* 最后,Span对象在Finally块中完成。这意味着设置了Span对象的结束时间戳,并将其发送到跟踪系统。
* 总之,tracer.nextSpan()创建一个新的Span对象,而tracer.currentSpan()返回当前的Span对象。
*
* Span.start()和Span.finish()都是Spring Cloud Sleuth的Span类提供的方法。
* Span.start()用于启动Span对象。这将Span对象的开始时间戳设置为当前时间。
* 一旦启动了Span对象,就可以使用它来记录跟踪信息,如日志、tag和baggage项。
* 在提供的代码中,在使用trace.nextspan()创建Span对象后立即调用Span.start()。这意味着Span对象的开始时间戳在创建后立即设置。
* 另一方面,Span.finish()用于完成Span对象。这将Span对象的结束时间戳设置为当前时间,并将其发送到跟踪系统。
* 一旦Span对象完成,就不能向其添加进一步的跟踪信息。
* 在提供的代码中,在finally块中调用span.finish()。这意味着无论是否抛出异常,都会设置Span对象的结束时间戳。
* 这确保了Span对象总是完成并发送到跟踪系统。
*/
Span span = tracer.currentSpan().name("mySpan1").start();
/**
* SpanInScope
* 它提供了一种为特定作用域激活'Span'的方法,例如线程或请求,并在退出作用域时停用'Span'。
* 当一个'Span'为一个范围激活时,它将成为该范围的活动'Span',并且该范围内的任何后续跟踪操作将与该'Span'相关联。
* 这允许多个“span”在不同的作用域中同时处于活动状态,这对于跟踪涉及多个线程或请求的操作非常有用。
* 'SpanInScope'类提供了为给定范围激活和取消激活'Span'的方法。它还提供了一种方法来检索当前范围的活动“Span”,
* 这对于调试和日志记录非常有用。
*
* 分布式跟踪中“Span”的scope指的是“Span”处于活动状态并可用于跟踪操作的上下文。scope确定哪些操作与“Span”相关联,哪些不关联。
* 在Spring Cloud Sleuth中,“Span”的scope可以通过创建它的上下文来定义。例如,在传入HTTP请求的上下文中创建的'Span'将具有仅限于
* 该请求的作用域。在该请求中发生的任何后续操作,例如数据库查询或远程调用,都将与该' Span '相关联。
* 'Span'的作用域也可以使用' SpanInScope '类来管理,它提供了一种为特定作用域(如线程或请求)激活和停用'Span'的方法。
* 这允许多个“span”在不同的作用域中同时处于活动状态,这对于跟踪涉及多个线程或请求的操作非常有用。
*
* “Tracer”类中的“withSpanInScope”方法用于激活当前作用域的给定“Span”。此方法以'Span'作为参数并返回'Scope'对象,
* 该对象可用于在退出作用域时停用'Span'。
* 当使用'withSpanInScope'为当前范围激活' Span '时,它将成为该范围的活动'Span',并且该范围内的任何后续跟踪操作将与该'Span'相关联。
* 这允许多个“span”在不同的作用域中同时处于活动状态,这对于跟踪涉及多个线程或请求的操作非常有用。
* 'withSpanInScope'方法通常与'Tracer'类的'startScopedSpan'方法一起使用,该方法创建一个新的'Span'并为当前范围激活它。
* 如果需要的话,'withSpanInScope'方法可以用来为不同的作用域激活不同的'Span'。
*/
/**
* 在Java中,try-with-resources是一种语言特性,它允许您声明在try块结束时自动关闭的资源。
* 在此语法中,ResourceType是您想要使用的资源的类型。资源变量是将保存资源的变量的名称。
* 当try块退出时,无论是正常退出还是由于异常退出,资源变量都将自动关闭。这意味着将在资源对象上调用ResourceType类的close()方法。
* try (ResourceType resource = new ResourceType()) {
* // use the resource
* }
* 在提供的代码中,try-with-resources块用于创建跟踪程序。SpanInScope对象。
* 该对象用于设置使用tracer.nextSpan()创建的Span对象的范围。
* 通过使用资源尝试,Tracer。SpanInScope对象在try块结束时自动关闭。
* 这确保了Span对象的范围被正确设置,并且Tracer.SpanInScope对象被正确清理。
*/
try (Tracer.SpanInScope ws = tracer.withSpanInScope(span)) {
// tag
/**
* 如果您使用的是Zipkin等调用链分析工具,则可以在该工具的界面上根据tag搜索span。
* 在Zipkin中,点击“Find Traces”按钮,然后在搜索框中输入您要搜索的标记即可搜索span。
*/
span.tag("myTag1", "tagValue1");
LOGGER.info("mySpan1:{}",span.toString());
ResponseEntity<String> forEntity = restTemplate.getForEntity(PREFIX_URL + "req/b", String.class);
return forEntity.getBody();
} finally {
span.finish();
}
}
}server2:
package com.example.springcloudsleuthdemo2.controller;
import brave.Span;
import brave.Tracer;
import brave.propagation.TraceContext;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.MDC;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @Author yangruizeng
* @create 2023/6/5 20:26
* @Description TODO
*/
@RestController
public class SleuthController {
@Autowired
private Tracer tracer;
private static final Logger LOGGER = LoggerFactory.getLogger(SleuthController.class);
@GetMapping("/hello")
public String helloWorld(){
return "Hello World!";
}
@GetMapping("/req/b")
public String reqB(){
Span span = tracer.currentSpan().name("mySpan2").start();
try {
LOGGER.info("span:{}",span.toString());
return "B";
} finally {
span.finish();
}
}
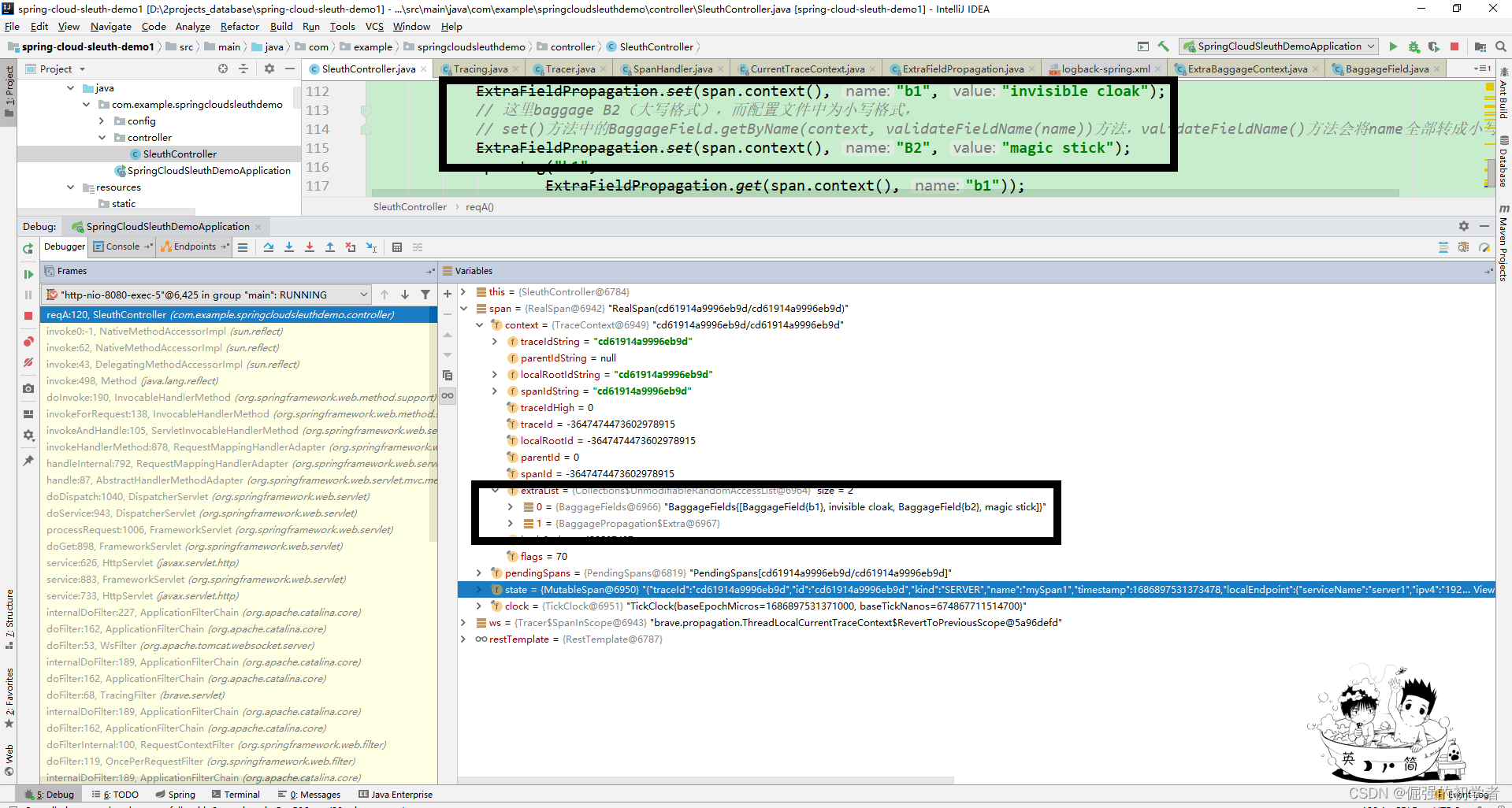
}上述代码,server1服务中“/req/a”请求资源中为当前Span添加“myTag1:tagValue1”标签,debug发现该Span的state属性中,已经有了该标签值,而在server1中的“req/b”中请求资源中的当前Span中的state属性中并没有该标签值,说明Tag不具有传递数据能力。


访问Zipkin的可视化页面,通过Tag搜索:

6.2Baggage
Baggage与Trace一起传播(每个子Span都包含其父的Baggage)。Zipkin对Baggage一无所知,也没有收到这些信息。
从Sleuth 2.0.0开始,您必须在项目配置中显式地传递Baggage键名。
Tags被附加到一个特定的Span。换句话说,它们只针对特定的Span呈现。但是,您可以按Tag搜索以查找Trace,前提是存在具有搜索Tag值的Span。
-
spring.sleuth.Baggage 配置项
spring.sleuth.Baggage 配置项用于设置 Sleuth 中的 Baggage(行李)信息。Baggage是跨请求链路传播的键值对信息,可以随请求一起传递,Sleuth使用MDC或者header来存储和传递Baggage信息。以下是 spring.sleuth.Baggage 可以设置的配置项:
-
remote-fields: 远程传递Baggage信息所使用的header名称,多个header名称使用逗号分隔。 -
propagation-keys: Baggage信息需要跨线程传递,此配置可以设置需要使用哪些名称的Baggage。 -
Baggage-keys:指定的Baggage Field名称添加到Spring Cloud Sleuth的默认Baggage Field列表中。默认情况下,Spring Cloud Sleuth会自动传递一些常用的Baggage Field,例如X-B3-TraceID、X-B3-SpanID等。如果需要传递其他的Baggage Field,可以将其名称添加到spring.sleuth.Baggage-keys配置项中。 -
field-name-prefix: 自定义的Baggage信息名前缀,避免与其他项目的命名产生冲突。 -
whitelist-keys: 要记录的自定义Baggage信息名,如果不设置,则记录所有Baggage信息名。 -
tag-fields: 记录Baggage信息时,将Baggage信息作为Span标签输出,多个Baggage信息使用逗号分隔。 -
spring.sleuth.enabled:是否启用Spring Cloud Sleuth,默认为true。 -
spring.sleuth.sampler.probability:采样率,用于控制是否记录Span,默认为1.0,即记录所有Span。 -
spring.sleuth.async.enabled:是否启用异步Span记录,默认为true。 -
spring.sleuth.log.slf4j.whitelisted-mdc-keys:指定需要记录到MDC中的Baggage Field名称,用于在日志中记录Span信息。 -
spring.sleuth.log.slf4j.enabled:是否启用Slf4j日志记录,默认为true。
使用 spring.sleuth.Baggage 配置项,可以设置Baggage信息的相关配置,实现对跨请求链路的Baggage信息的传递和跟踪,以及输出为Span标签等。
- Baggage的集成:
在server1与server2服务中都添加如下配置:
spring.sleuth.propagation-keys=b1,b2server1:
package com.example.springcloudsleuthdemo.controller;
import brave.Span;
import brave.Tracer;
import brave.propagation.ExtraFieldPropagation;
import brave.propagation.TraceContext;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.MDC;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.client.RestTemplate;
/**
* @Author yangruizeng
* @create 2023/6/5 20:26
* @Description TODO
*/
@RestController
public class SleuthController {
private static final Logger LOGGER = LoggerFactory.getLogger(SleuthController.class);
private static final String PREFIX_URL = "http://localhost:8081/sleuth/";
@Autowired
private RestTemplate restTemplate;
@Autowired
private Tracer tracer;
@GetMapping("/req/a")
public String reqA(){
/**
* trace.nextspan()和trace.currentspan()都是Spring Cloud Sleuth的Tracer类提供的方法。
* nextspan()创建一个新的Span对象并返回它。这个新的Span对象是当前Span对象的子对象(如果有的话)。
* 如果没有当前的Span对象,那么新的Span对象就是根Span对象。
* 另一方面,trace.currentspan()返回当前Span对象。如果当前没有Span对象,则trace.currentspan()返回null。
* 在提供的代码中,tracer.nextSpan()用于创建一个新的Span对象,并将其名称设置为“mySpan”。
* 然后启动这个新的Span对象,并使用try-with-resources块设置其作用域。在这个范围内,一个键为“myTag”,
* 值为“tagValue”的标签被添加到Span对象中。
* 最后,Span对象在Finally块中完成。这意味着设置了Span对象的结束时间戳,并将其发送到跟踪系统。
* 总之,tracer.nextSpan()创建一个新的Span对象,而tracer.currentSpan()返回当前的Span对象。
*
* Span.start()和Span.finish()都是Spring Cloud Sleuth的Span类提供的方法。
* Span.start()用于启动Span对象。这将Span对象的开始时间戳设置为当前时间。
* 一旦启动了Span对象,就可以使用它来记录跟踪信息,如日志、tag和baggage项。
* 在提供的代码中,在使用trace.nextspan()创建Span对象后立即调用Span.start()。这意味着Span对象的开始时间戳在创建后立即设置。
* 另一方面,Span.finish()用于完成Span对象。这将Span对象的结束时间戳设置为当前时间,并将其发送到跟踪系统。
* 一旦Span对象完成,就不能向其添加进一步的跟踪信息。
* 在提供的代码中,在finally块中调用span.finish()。这意味着无论是否抛出异常,都会设置Span对象的结束时间戳。
* 这确保了Span对象总是完成并发送到跟踪系统。
*/
Span span = tracer.currentSpan().name("mySpan1").start();
/**
* SpanInScope
* 它提供了一种为特定作用域激活'Span'的方法,例如线程或请求,并在退出作用域时停用'Span'。
* 当一个'Span'为一个范围激活时,它将成为该范围的活动'Span',并且该范围内的任何后续跟踪操作将与该'Span'相关联。
* 这允许多个“span”在不同的作用域中同时处于活动状态,这对于跟踪涉及多个线程或请求的操作非常有用。
* 'SpanInScope'类提供了为给定范围激活和取消激活'Span'的方法。它还提供了一种方法来检索当前范围的活动“Span”,
* 这对于调试和日志记录非常有用。
*
* 分布式跟踪中“Span”的scope指的是“Span”处于活动状态并可用于跟踪操作的上下文。scope确定哪些操作与“Span”相关联,哪些不关联。
* 在Spring Cloud Sleuth中,“Span”的scope可以通过创建它的上下文来定义。例如,在传入HTTP请求的上下文中创建的'Span'将具有仅限于
* 该请求的作用域。在该请求中发生的任何后续操作,例如数据库查询或远程调用,都将与该' Span '相关联。
* 'Span'的作用域也可以使用' SpanInScope '类来管理,它提供了一种为特定作用域(如线程或请求)激活和停用'Span'的方法。
* 这允许多个“span”在不同的作用域中同时处于活动状态,这对于跟踪涉及多个线程或请求的操作非常有用。
*
* “Tracer”类中的“withSpanInScope”方法用于激活当前作用域的给定“Span”。此方法以'Span'作为参数并返回'Scope'对象,
* 该对象可用于在退出作用域时停用'Span'。
* 当使用'withSpanInScope'为当前范围激活' Span '时,它将成为该范围的活动'Span',并且该范围内的任何后续跟踪操作将与该'Span'相关联。
* 这允许多个“span”在不同的作用域中同时处于活动状态,这对于跟踪涉及多个线程或请求的操作非常有用。
* 'withSpanInScope'方法通常与'Tracer'类的'startScopedSpan'方法一起使用,该方法创建一个新的'Span'并为当前范围激活它。
* 如果需要的话,'withSpanInScope'方法可以用来为不同的作用域激活不同的'Span'。
*/
/**
* 在Java中,try-with-resources是一种语言特性,它允许您声明在try块结束时自动关闭的资源。
* 在此语法中,ResourceType是您想要使用的资源的类型。资源变量是将保存资源的变量的名称。
* 当try块退出时,无论是正常退出还是由于异常退出,资源变量都将自动关闭。这意味着将在资源对象上调用ResourceType类的close()方法。
* try (ResourceType resource = new ResourceType()) {
* // use the resource
* }
* 在提供的代码中,try-with-resources块用于创建跟踪程序。SpanInScope对象。
* 该对象用于设置使用tracer.nextSpan()创建的Span对象的范围。
* 通过使用资源尝试,Tracer。SpanInScope对象在try块结束时自动关闭。
* 这确保了Span对象的范围被正确设置,并且Tracer.SpanInScope对象被正确清理。
*/
try (Tracer.SpanInScope ws = tracer.withSpanInScope(span)) {
// baggage
// 该方法存在问题 无法证明baggage的value值是否添加成功
// 添加baggage的value需要application.properties配置spring.sleuth.propagation-keys=foo,upper_case
// 原理解析:项目启动时候,会加载该TraceBaggageConfiguration.class类到spring容器,实例化Propagation.Factory实例,
// 其中sleuthPropagation()方法会读取PROPAGATION_KEYS = "spring.sleuth.propagation-keys"配置,只有配置的key(baggage name)
// 和默认(traceId、parentId、spanId、sampled、X-B3-TraceId、X-B3-ParentSpanId、X-B3-SpanId、X-Span-Export、spanExportable)
// 的baggage会被添加到span的上下文中。
ExtraFieldPropagation.set(span.context(), "b1", "invisible cloak");
// 这里baggage B2(大写格式),而配置文件中为小写格式,
// set()方法中的BaggageField.getByName(context, validateFieldName(name))方法,validateFieldName()方法会将name全部转成小写格式。
ExtraFieldPropagation.set(span.context(), "B2", "magic stick");
LOGGER.info("mySpan1:{}",span.toString());
ResponseEntity<String> forEntity = restTemplate.getForEntity(PREFIX_URL + "req/b", String.class);
return forEntity.getBody();
} finally {
span.finish();
}
}
}server2:参照Tag部分。
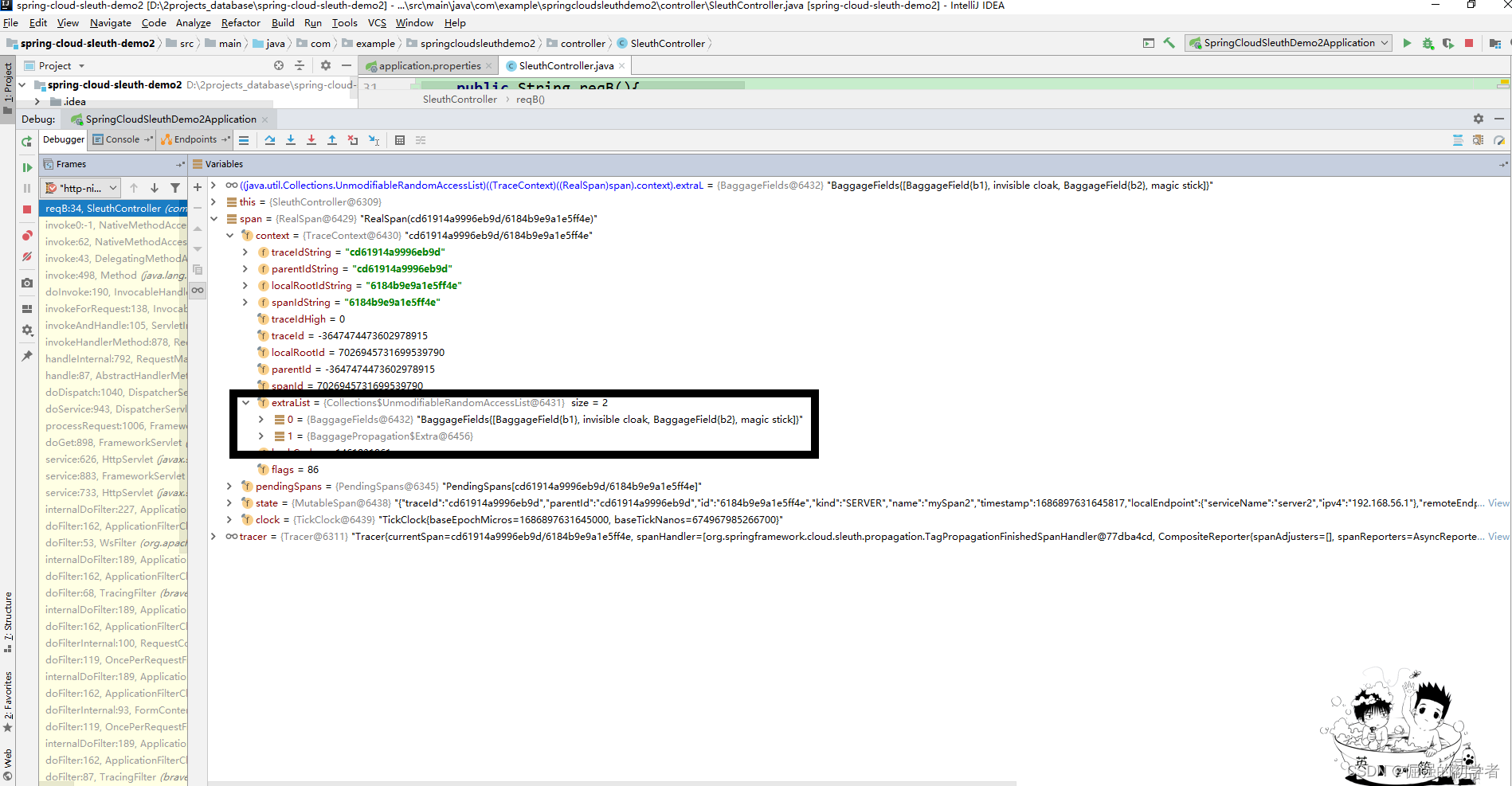
上述代码在server1中“/req/a”请求资源的Span中添加了Baggage,通过debug会发现在server2中的“/req/b”请求资源的额当前Span中也包含上游的Baggage数据,说明Baggage可以传递数据。
7采样
在像Spring Cloud Sleuth这样的分布式跟踪系统中,跟踪通过应用程序的每个请求通常是不可行的。这是因为跟踪每个请求可能会生成大量数据,并且在性能和存储方面可能会很昂贵。
为了解决这个问题,Spring Cloud Sleuth提供了一种抽样机制,允许您根据抽样率选择性地跟踪请求。采样率决定了跟踪请求的百分比。例如,如果采样率设置为0.1,那么只有10%的请求会被跟踪。
可以使用应用程序配置文件中的spring. probe .sampler.probability属性来设置采样率。此属性的值应该是0到1之间的小数,以百分比表示采样率。以采样率为10%为例,可以进行如下配置:
spring.sleuth.sampler.probability=0.1如下图所示,我将采样率设置为0.5,下面5个trace中只有2个被采样上报到Zipkin。


默认情况下,全局采样器对所有跟踪操作应用单一速率。trace.builder.sampler控制这个设置,它默认跟踪每个请求。
Sampler抽象类与SamplerFunction接口是采样控制的两个基础。
Sampler是Spring Cloud Sleuth提供的一个抽象类,用于确定是否应该对Span对象进行采样。它提供了isSampling()方法的默认实现,该方法返回一个布尔值,指示是否应该对Span对象进行采样。
另一方面,SamplerFunction是Spring Cloud Sleuth提供的一个接口,用于确定是否应该对Span对象进行采样。它只有一个方法,trySample(),它接受一个TraceContext对象作为参数,并返回一个布尔值,该值指示是否应该对Span对象进行采样。
Sampler和SamplerFunction之间的主要区别在于Sampler提供了isSampling()方法的默认实现,而SamplerFunction需要您自己实现trySample()方法。这意味着如果您只需要一个简单的采样策略,那么Sampler更容易使用,而如果您需要对应用程序的采样行为进行更细粒度的控制,那么SamplerFunction更灵活。
一般来说,如果您只需要一个简单的采样策略并且不需要自定义采样器的行为,则应该使用Sampler。例如,如果您想对所有请求进行采样,则可以使用AlwaysSampler,如果您想完全禁用跟踪,则可以使用NeverSampler。
另一方面,如果需要对应用程序的采样行为进行更细粒度的控制,则应该使用SamplerFunction。例如,如果您希望基于固定的百分比对请求进行抽样,您可以使用PercentageBasedSampler;如果您需要根据更复杂的标准做出抽样决策,您可以创建自己的SamplerFunction的自定义实现。
总之,Sampler和SamplerFunction都用于确定是否应该对Span对象进行采样,但是Sampler提供了isSampling()方法的默认实现,而SamplerFunction需要您自己实现trySample()方法。如果您只需要一个简单的采样策略,请使用Sampler,如果您需要对应用程序的采样行为进行更细粒度的控制,请使用SamplerFunction。
7.1自定义采样
根据操作的不同,您可能需要应用不同的策略。例如,您可能不希望跟踪对静态资源(如图像)的请求,或者您可能希望跟踪对新api的所有请求。与过滤器、拦截器有异曲同工之妙。下面的例子展示了它是如何在内部工作的:
package com.example.springcloudsleuthdemo.config;
import brave.sampler.Sampler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.Ordered;
import org.springframework.web.filter.RequestContextFilter;
import javax.servlet.http.HttpServletRequest;
/**
* @Author yrz
* @create 2023/6/17 11:00
* @Description TODO
*/
@Configuration
public class SamplerConfig {
private static final Logger LOGGER = LoggerFactory.getLogger(SamplerConfig.class);
@Bean
public Sampler defaultSampler() {
// 对所有的trace总是采样 Spring Cloud Sleuth的默认行为
return Sampler.ALWAYS_SAMPLE;
// 对所有的trace都不采样 也就是在Zipkin等可视化页面上看不到任何调用链信息
// return Sampler.NEVER_SAMPLE;
}
}package com.example.springcloudsleuthdemo.config;
import brave.sampler.Sampler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.Ordered;
import org.springframework.web.filter.RequestContextFilter;
import javax.servlet.http.HttpServletRequest;
/**
* @Author yrz
* @create 2023/6/17 11:00
* @Description TODO
*/
@Configuration
public class SamplerConfig {
private static final Logger LOGGER = LoggerFactory.getLogger(SamplerConfig.class);
/**
* 将当前请求和线程进行绑定,以便在处理HTTP请求时可以轻松访问请求上下文。
* @return
*/
@Bean
public FilterRegistrationBean<RequestContextFilter> requestContextFilter() {
FilterRegistrationBean<RequestContextFilter> registration = new FilterRegistrationBean<>();
registration.setFilter(new RequestContextFilter());
registration.setOrder(Ordered.HIGHEST_PRECEDENCE);
return registration;
}
// 该自定义采样将只采样uri为"/sleuth/hello"的请求,其他的不采样,如果debug不采样的请求资源的当前Span,会发现其类型为NoopSpan。
@Bean(name = "mySampler")
public Sampler mySampler(HttpServletRequest input) {
return new Sampler() {
@Override
public boolean isSampled(long traceId) {
LOGGER.info("mySampler return true uri : {}", input.getRequestURI());
if (input.getRequestURI().equalsIgnoreCase("/sleuth/hello")) {
return true;
}
return false;
}
};
}
}8定制
在Brave 5.7中,您可以为项目提供各种定制器。
-
TracingCustomizer——允许配置插件协作构建跟踪实例。
-
CurrentTraceContextCustomizer ——允许配置插件协作构建CurrentTraceContext的实例。
-
ExtraFieldCustomizer ——允许配置插件协作构建ExtraFieldPropagation.Factory的实例。
Sleuth将搜索这些类型的bean并自动应用自定义。
8.1数据策略
HTTP请求的默认Span数据策略在Brave中描述:github.com/openzipkin/brave/tree/master/instrumentation/http#span-data-policy
要向Span中添加不同的数据,需要根据收集数据的时间注册一个类型为brave.http.HttpRequestParser或brave.http.HttpResponseParser的bean。
Bean名称对应于请求端或响应端,以及它是客户机还是服务器。例如,sleuthHttpClientRequestParser更改在将客户端请求发送到服务器之前收集的内容。
为了方便您,可以使用@HttpClientRequestParser、@HttpClientResponseParser和相应的服务器注释来注入适当的bean或通过它们的静态String NAME字段引用bean名称。
下面是一个在默认值之外添加HTTP url的例子:
@Configuration
class Config {
@Bean(name = { HttpClientRequestParser.NAME, HttpServerRequestParser.NAME })
HttpRequestParser sleuthHttpServerRequestParser() {
return (req, context, span) -> {
HttpRequestParser.DEFAULT.parse(req, context, span);
String url = req.url();
if (url != null) {
span.tag("http.url", url);
}
};
}
}8.2抽样
如果需要客户端/服务器采样,只需注册一个类型为brave的bean。并为客户端采样器命名为sleuthHttpClientSampler,为服务器采样器命名为sleuthHttpServerSampler。
为了方便起见,可以使用@HttpClientSampler和@HttpServerSampler注释注入适当的bean,或者通过它们的静态String NAME字段引用bean名称。
查看Brave的代码,看看如何制作基于路径的采样器的例子github.com/openzipkin/brave/tree/master/instrumentation/http#sampling-policy
如果您想完全重写HttpTracing bean,您可以使用SkipPatternProvider接口来检索不应该采样的span的URL Pattern。下面你可以看到一个在服务器端samplerhttprequest中使用SkipPatternProvider的例子。
@Configuration
class Config {
@Bean(name = HttpServerSampler.NAME)
SamplerFunction<HttpRequest> myHttpSampler(SkipPatternProvider provider) {
Pattern pattern = provider.skipPattern();
return request -> {
String url = request.path();
boolean shouldSkip = pattern.matcher(url).matches();
if (shouldSkip) {
return false;
}
return null;
};
}
}8.3TracingFilter
您还可以修改TracingFilter的行为,TracingFilter是负责处理输入HTTP请求并根据HTTP响应添加标记的组件。您可以通过注册自己的TracingFilter bean实例来定制标记或修改响应头。
在下面的示例中,我们注册TracingFilter bean,添加包含当前Span的跟踪id的ZIPKIN-TRACE-ID响应头,并向Span添加一个带有键custom的标记和一个值标记。
@Component
@Order(TraceWebServletAutoConfiguration.TRACING_FILTER_ORDER + 1)
class MyFilter extends GenericFilterBean {
private final Tracer tracer;
MyFilter(Tracer tracer) {
this.tracer = tracer;
}
@Override
public void doFilter(ServletRequest request, ServletResponse response,
FilterChain chain) throws IOException, ServletException {
Span currentSpan = this.tracer.currentSpan();
if (currentSpan == null) {
chain.doFilter(request, response);
return;
}
// for readability we're returning trace id in a hex form
((HttpServletResponse) response).addHeader("ZIPKIN-TRACE-ID",
currentSpan.context().traceIdString());
// we can also add some custom tags
currentSpan.tag("custom", "tag");
chain.doFilter(request, response);
}
}8.4自定义服务名称
默认情况下,Sleuth假设,当您向Zipkin发送一个span时,您希望该span的服务名称等于spring.application.name属性的值。不过,情况并非总是如此。在某些情况下,您希望为来自应用程序的所有Span显式地提供不同的服务名称。为了实现这一点,你可以将以下属性传递给你的应用程序来覆盖该值(这个例子是一个名为myService的服务):
spring.zipkin.service.name: myService8.5自定义报告Span
在报告Span(例如,向Zipkin)之前,您可能希望以某种方式修改该Span。你可以通过实现一个SpanHandler来实现。
在Sleuth中,我们生成具有固定名称的Span。有些用户希望根据标签的值修改名称。您可以实现SpanHandler接口来更改该名称。
下面的例子展示了如何注册两个实现SpanHandler的bean:
@Bean
SpanHandler handlerOne() {
return new SpanHandler() {
@Override
public boolean end(TraceContext traceContext, MutableSpan span,
Cause cause) {
span.name("foo");
return true; // keep this span
}
};
}
@Bean
SpanHandler handlerTwo() {
return new SpanHandler() {
@Override
public boolean end(TraceContext traceContext, MutableSpan span,
Cause cause) {
span.name(span.name() + " bar");
return true; // keep this span
}
};
}前面的示例导致在报告之前将报告的span的名称更改为foo bar(例如,更改为Zipkin)。
8.6主机定位器
本节介绍如何从服务发现中定义主机。这不是通过服务发现找到Zipkin。
要定义与特定范围对应的主机,我们需要解析主机名和端口。默认的方法是从服务器属性中获取这些值。如果没有设置这些,我们尝试从网络接口检索主机名。
如果您启用了发现客户端,并且希望从服务注册中心的已注册实例中检索主机地址,则必须设置spring.zipkin.locator.discovery.enabled属性(它适用于基于http和基于流的span报告),如下所示:
spring.zipkin.locator.discovery.enabled: true如果想了解更过关于Spring Cloud Sleuth的功能与使用,请查阅对应版本的官网文档(Index of /spring-cloud-sleuth/docs)。
想要获取示例源码请私信我。