GMOEA代码的运行
引言
GMOEA是南方科大程然老师组2021年发表在IEEE Trans on Cybernetics 的论文,主要的贡献是将GAN应用在了MOP多目标进化中。
论文链接
代码链接
但是EMI只release了算法本身,没有提供求解测试集的脚本。然后本人花了一天一夜把python面向对象编程的知识都学了一遍。从论文的动机,算法内容,实验结果,环境搭建,代码运行,代码解读都系统性的讲解一遍。泣血的经历写出这篇博客。
Generative Adversial Networks(GAN)
GAN 肯定是进五年来深度学习领域最具代表性的工作了。具体我是学习了李沐老师的视频,认真学了好几遍。才理解。
跟李沐学AI-论文精度系列-GAN-哔站视频连接
GAN发表在NIPS2014的原文.pdf
Goodfellow 提供GAN的源码
GAN生成的动机
14年goodfellow在做GAN这个工作的时候,觉得深度学习在辨别模型上做的很好了,但在生成模型上做的不行。原因是要生成数据,需要拟合样本的数据分布,在最大化似然函数的时候计算困难,且随着维度增加计算量爆炸。所以goodfellow便绕开这个困难,说去学习一个数据分布,效果差不多就行。
什么是GAN
GAN做生成模型的,简而言之就是,用一个简单的噪声分布 p z ( z ) p_z(z) pz(z)采样生成一些噪声 z z z。然后映射到真实样本 x x xd的数据分布 p d a t a ( x ) p_{data}(x) pdata(x)上。其中有两个人工神经网络在对抗相互促进学习。一个是生成器 G ( z , θ g ) G(z,\theta_g) G(z,θg)输入噪声,生成fake样本 x ˉ \bar{x} xˉ,有一个可学习的参数 θ g \theta_g θg。然后有个分辨器 D ( x , θ d ) D(x,\theta_d) D(x,θd)输入样本 x x x和 x ˉ \bar{x} xˉ提前打上0-1标签,训练一个二分类器判断哪些样本来自真实数据分布,哪些来自于生成器G。
那么GAN需要同时训练两个神经网络G和D,在训练D时G是固定的,训练G时和D没有关系。那么价值函数如下。是一个两人minmax函数。表示一个对抗的过程。价值函数V表示两个期望,整体是D的期望,首先第一部分表示采样自真实数据分布的样本x,输入分类器D,要让分类器输出应该尽量为D(x)=1,加上log就等于0,第二项是输入噪声到生成器G(z)生成假样本 x ˉ \bar{x} xˉ,再输入到分类器D中,分类器要分类成0,那么整体就是0。如果分类器不完美会犯错,则整体是个负数。所以优化D的参数 θ d \theta_d θd需要使得整个表达式最大化。
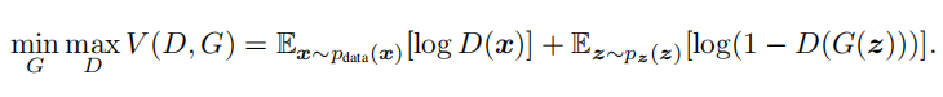
优化生成器G就需要使得第二项,尽可能趋向于负无穷。也就是最小化G。
GAN能做什么
GAN能通过一个简单的数据分布,映射到任何你想生成的分布上。比如图片之间的映射,图片换脸,视频换脸,音乐换声。生成不存在的人脸,生成不存在的花等等。
GAN的训练过程
首先采用两个长为m的batch,一个来自噪声,一个来自于真实样本,用来优化D的参数。这个过程执行k步。
其次再采样一个长为m的噪声,来训练生成器G。这样交替进行。直到两个神经网络都无法进步,达到纳什均衡。

一个生动的比喻
G相当于造假币的人,D相当于警察。G刚开始造假技术水平低,警察通过侦查马上就发现了。随后G就开始改进自己的造假技术,这时警察发现造假更厉害了,于是也提高自己的打假能力。最后再这个对抗的过程中,两方都在进步。最后作者希望G造假者胜出。这样便达到了目的。

GMOEA-- GAN在MOP的应用
GMOEA的动机
说传统MOP的优化框架长这样,生成解主要靠启发式方法。但是启发式方法有时候很难生成想要的解。
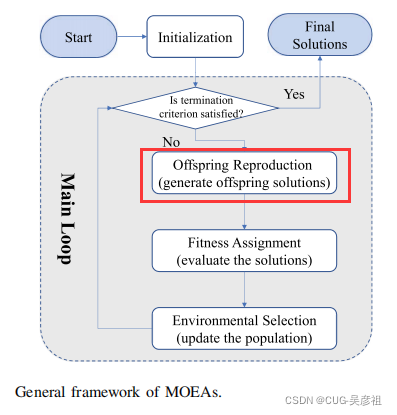
比如遇到上面这种情况,两个父代p1和p2再怎么交叉也很难将解生成在pareto 解集PS附近。所以要用机器学习模型来替换启发式生成方法。
因为MOP中的决策空间可以看做是个数据分布。然后PS是这个数据分布上采样得到的。想用随机的噪声分布来拟合出非支配解的数据分布。所以使用GAN来学习。
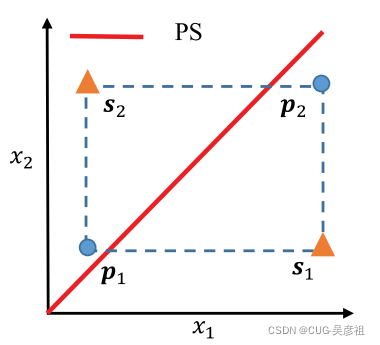
GMOEA的框架
首先初始化,确定参数,随后初始化整个网络确定为训练模式。随后采用SPEA2算法确定非支配解。将非支配解Pr确定为真实样本,非支配解为Pf错误样本。分类器需要分类出样本中的真实样本Pr错误样本Pf和生成器G(z)用噪声生成的假样本。随后采用训练的网络生成子种群。然后再进行环境选择。

GMOEA的网络模型
生成器有两个全连接层两个隐含层,分辨器有一个全连接层和一个隐含层。输出为sigmoid激活函数。用非支配解的均值和协方差矩阵来定位噪声分布。
GMOEA模型训练
第一步计算Pr的均值和协方差矩阵,第二步选取一个长为m的batch,T。然后去掉T。再用噪声分布生成一个样本Z。用来训练分辨器D。这个步骤执行k次。用旁边的价值函数训练。再取样一个噪声来训练G。

GMOEA生成子代
为了防止GAN在训练过程中崩溃,影响子代生成的质量。所以和传统的进化算子GA采用相同的选择概率。并且都会作为GAN的训练样本。
GAN生成子代,先在均匀分布U(0,1)上生成一个D维向量x。再用多元正态分布变换到y上
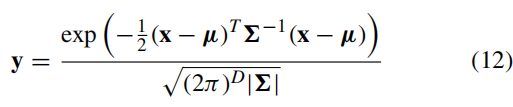
再结合上下界,映射到决策空间去。
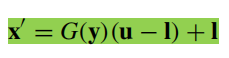
代码运行环境搭建
首先需要一块GPU显卡。论文中用的是1080Ti。我们实验室是3080Ti。
1. 安装Anoconda
在清华的镜像源可以下载,我下载的是Anaconda3-2018-12-31-windows-x86_64这个版本。不用先装python,因为创建虚拟环境的时候可以直接指定安装那个版本的python。
2. 安装cuda
网上有教程,这里安装的是cuda11.3。配置好英伟达这些东西后。
3. 安装cudann
是cuda的神经网络的库。需要添加到cuda安装的地方。
4.安装pycharm
因为运行代码的时候需要调试等。虽然anaconda自带的spyder是个类似于matlab的编辑器。但是个人还是觉得pycharm好用一点。就代码提示自动补全还是很人性化的。pycharm随便安装就行,我安装的是社区版2021.3.3.x64。
5.创建虚拟环境

6.替换项目镜像源和安装包
替换镜像源

安装numpy和scipy等包
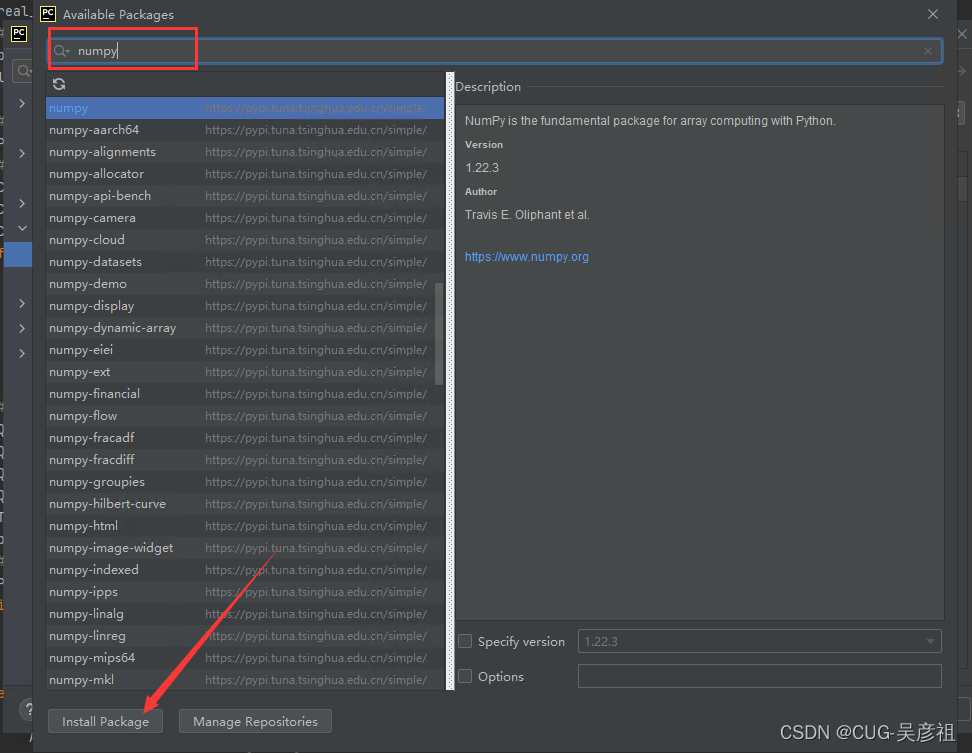
6.激活虚拟环境
进入你pycharm的terminal窗口。
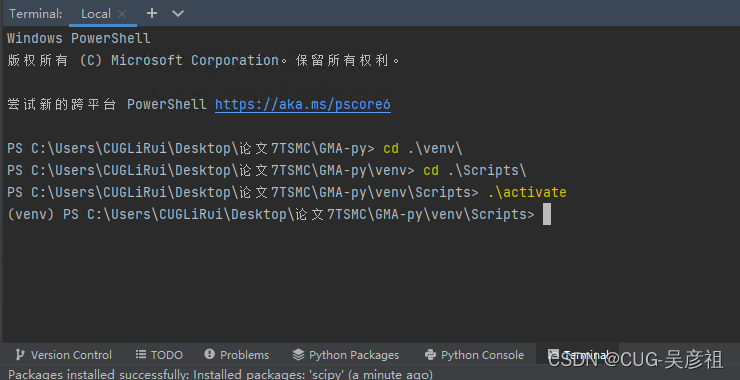
如果激活没有反应。
然后需要用管理员打开powershell,输入Set-ExecutionPolicy RemoteSigned就可以激活。不行就重启pycharm
.\activate
下载pytorch的GPU版本
首先pytorch对应的是torch包,而不叫pytorch。直接去pytorch官网。根据你的配置,选择相应的pip下载命令。在下面这个网址会自动根据你的配置或者你自选配置给你推荐用什么命令。
https://pytorch.org/get-started/locally/
我根据自己的配置,然后选择pip下载。
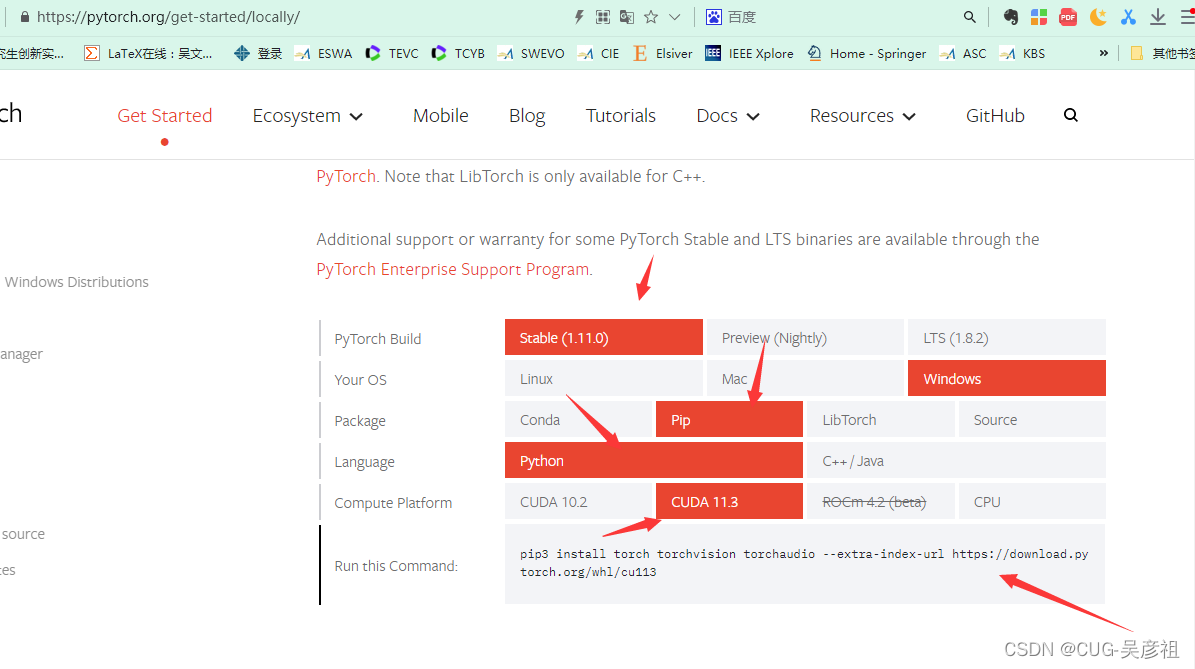
在我刚才激活的pycharm虚拟环境,输入pip命令下载pytorch。
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
随后还要下载torchnn,scipy等包,同理都直接pip
6.运行GMOEA代码
将GMOEA的代码解压拷贝进新解的pycharm项目中。由于GMOEA只给了算法本身没有给运行的脚本。那么就需要我们自己写。
首先直接给出使用GMOEA求解IMF1的,我自己摸索了两天写的脚本可以运行的。
from GMOEA import GMOEA
from IMMOEA_pro import*
from global_parameter import*
from EAreal import*
gp=GlobalParameter(d=30,operator=ea_real,pro=IMMOEA_F1)# problem表示求解问题的对象
G=GMOEA(gp=gp)
population, score=G.run()
print('finish')
首先导入GMOEA的包,还有测试问题IMMOEA的包,然后就是全局参数的包,还有导入进化算法的包。然后新建全局参数,输入的是决策变量维度,产生子种群算子这里是ea_real类,然后是测试问题IMMOEA_F1类。
值得说明的是,这里的全局参数中,输入问题会创建一个problem的对象,这里的参数输入的是self.pro = pro(d=d, m=m,)。而在IMMOEA_pro里面定义的问题类都是继承自test_problem这个父类的。父类中的构造函数是给了ref_num的初始化值,但子类中因为重写的构造函数,所以不会初始化ref_num而是要我给出。
虽然作者在代码里写的是子类的构造函数是生成父类对象来初始化。但是这里运行程序的时候,如果不给出ref_num会报错。
class IMMOEA_F1(test_problem):
def __init__(self, m, d, ref_num):
test_problem.__init__(self, m, d, ref_num)
所以我将全局参数这个类进行了修改。直接按照论文里的设置将ref_num统一设为10000
class GlobalParameter:
"""
This class includes the general parameters for running the algorithm.
We can also define the class of population, which includes all the operations
"""
def __init__(self, m=2, n=100, d=3, eva=10000, decs=None, operator=None, pro=None, run=None):
self.m = m
self.n = n
self.pro = pro(d=d, m=m, ref_num=10000) # Initialize the class of problem
self.d = self.pro.d # objectives
self.lower = self.pro.lower
self.upper = self.pro.upper
self.boundary = (self.lower, self.upper)
self.eva = eva
self.operator = operator
self.result = decs
self.decs = []
self.run = run
随后右键运行main就可以了。我是选择使用python console运行。这样可以观察运行后或者调试过程中的变量值。运行后会自动输出IGD值和评价次数的使用情况。
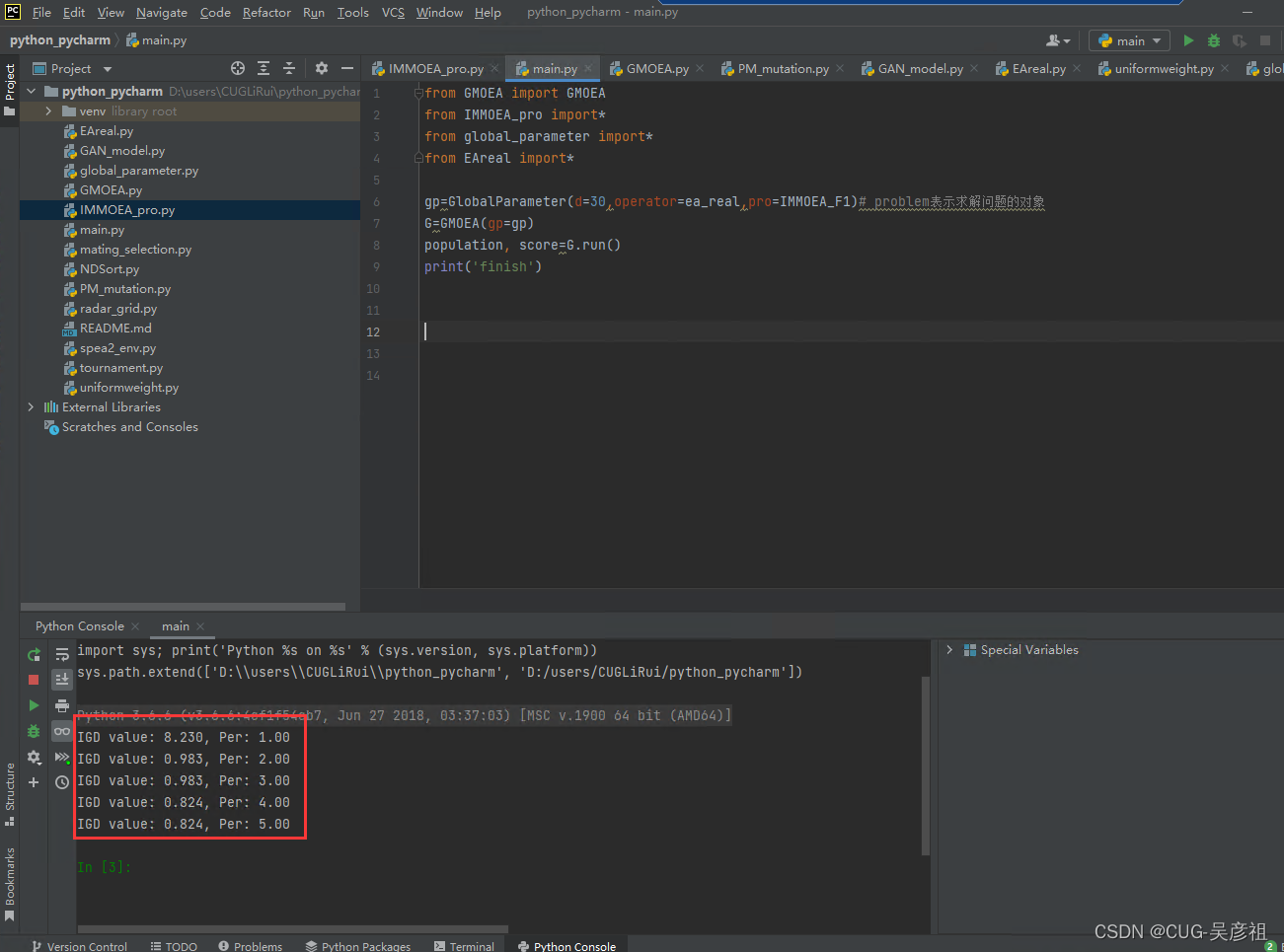
代码解读
首先这篇文章很好的解释了torch中的各种操作例如detach,variable,backforward和forward。这篇文章也讲的很好
我直接贴上我对于GAN_model.py的理解和注释。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
import random
import numpy as np
class Generator(nn.Module):
# initializers
def __init__(self, d, n_noise): # 1-d vector
super(Generator, self).__init__()
self.linear1 = nn.Linear(n_noise, d, bias=True)
self.bn1 = nn.BatchNorm1d(d)
self.linear2 = nn.Linear(d, d, bias=True)
self.bn2 = nn.BatchNorm1d(d)
self.linear3 = nn.Linear(d, d, bias=True)
self.bn3 = nn.BatchNorm1d(d)
# forward method
def forward(self, noise):
x = torch.tanh(self.bn1(self.linear1(noise)))
x = torch.tanh(self.bn2(self.linear2(x)))
x = torch.sigmoid(self.bn3(self.linear3(x)))
return x
class Discriminator(nn.Module):# 高层API编程神经网络的方式,需要传入一个model
# initializers
def __init__(self, d):
super(Discriminator, self).__init__()# 和自定义模型一样,第一句话就是调用父类的构造函数
self.linear1 = nn.Linear(d, d, bias=True)
self.linear2 = nn.Linear(d, 1, bias=True)
# forward method
def forward(self, dec): #定义好网络模型开始训练
x = torch.tanh(self.linear1(dec)) #输入决策变量进入线形层,再输入激活函数进入隐含层
x = torch.sigmoid(self.linear2(x))#输入上一层的输出进入线形层,再输入激活函数作为输出
return x
class GAN(object):
def __init__(self, d, batchsize, lr, epoches, n_noise):
self.d = d
self.n_noise = n_noise
self.BCE_loss = nn.BCELoss()
self.G = Generator(self.d, self.n_noise)
self.D = Discriminator(self.d)
self.G.cuda() #cuda加速
self.D.cuda()
self.G_optimizer = optim.Adam(self.G.parameters(), 4*lr)
self.D_optimizer = optim.Adam(self.D.parameters(), lr)
self.epoches = epoches
self.batchsize = batchsize
def train(self, pop_dec, labels, samples_pool):
self.D.train() #将模块设置为训练模式
self.G.train()
n, d = np.shape(pop_dec)
indices = np.arange(n) #获取下标
center = np.mean(samples_pool, axis=0) #计算采样池的均值
cov = np.cov(samples_pool[:10, :].reshape((d, samples_pool[:10, :].size // d)))#计算采样池的协方差矩阵
iter_no = (n + self.batchsize - 1) // self.batchsize # 迭代次数等于种群数+batch-1整除batch 看有几个batch
for epoch in range(self.epoches): #最多迭代两百次
g_train_losses = 0
for iteration in range(iter_no): #训练每个batch
# train the D with real dataset
self.D.zero_grad() #初始化梯度为0
given_x = pop_dec[iteration * self.batchsize: (1 + iteration) * self.batchsize, :]
given_y = labels[iteration * self.batchsize: (1 + iteration) * self.batchsize]
batch_size = np.shape(given_x)[0]
# (Tensor, cuda, Variable)
given_x_ = Variable(torch.from_numpy(given_x).cuda()).float()
# 将决策变量转为torch的张量类型,使用GPU训练随后转为varibale类型。
given_y = Variable(torch.from_numpy(given_y).cuda()).float()
d_results_real = self.D(given_x_.detach())#调用variable的detach函数 从当前变量分离,求x的梯度
# train the D with fake data
# 在多元高斯噪声上产生噪声变量
fake_x = np.random.multivariate_normal(center, cov, batch_size)
# 修正产生的噪声在0-1的范围
fake_x = torch.from_numpy(np.maximum(np.minimum(fake_x, np.ones((batch_size, self.d))),
np.zeros((batch_size, self.d))))
# 生成一个标签标注是0,.cuda表示在cuda上定义一个张量
fake_y = Variable(torch.zeros((batch_size, 1)).cuda())
fake_x_ = Variable(fake_x.cuda()).float()#torch 转variable
g_results = self.G(fake_x_.detach())#声明varibale对象不需要梯度,也就是在这个地方不能继续反馈不能求导。
d_results_fake = self.D(g_results)#随后再用G生成的结果输入D进行训练
#\符号表示当前行继续到下一行,BCE损失函数表示交叉熵损失函数
d_train_loss = self.BCE_loss(d_results_real, given_y) + \
self.BCE_loss(d_results_fake, fake_y) # vanilla GAN
d_train_loss.backward() #反向传播梯度信息更新参数
self.D_optimizer.step() #优化器更新所有参数
# train the G with fake data
self.G.zero_grad()#初始化梯度
fake_x = np.random.multivariate_normal(center, cov, batch_size)#生成一个噪声
fake_x = torch.from_numpy(np.maximum(np.minimum(fake_x, np.ones((batch_size, self.d))),
np.zeros((batch_size, self.d))))#修正其上下界
fake_x_ = Variable(fake_x.cuda()).float() #转换成一个张量
fake_y = Variable(torch.ones((batch_size, 1)).cuda())#定义其标签
g_results = self.G(fake_x_) #用G产生一个数
d_results = self.D(g_results) #再用G的值来让分辨器分类
g_train_loss = self.BCE_loss(d_results, fake_y) # vanilla GAN loss #来计算G的损失函数
g_train_loss.backward()#反馈训练
self.G_optimizer.step()#更新参数
g_train_losses += g_train_loss.cpu()#G的损失值更新
# after each epoch, shuffle the dataset
random.shuffle(indices)
pop_dec = pop_dec[indices, :]
def generate(self, sample_noises, population_size):
self.G.eval() # set to eval mode
center = np.mean(sample_noises, axis=0).T # mean value
cov = np.cov(sample_noises.T) # convariance
batch_size = population_size
noises = np.random.multivariate_normal(center, cov, batch_size)
noises = torch.from_numpy(np.maximum(np.minimum(noises, np.ones((batch_size, self.d))),
np.zeros((batch_size, self.d))))
decs = self.G(Variable(noises.cuda()).float()).cpu().data.numpy()
return decs
def discrimate(self, off):
self.D.eval() # set to eval mode
batch_size = off.shape[0]
off = off.reshape(batch_size, 1, off.shape[1])
x = Variable(torch.from_numpy(off).cuda(), volatile=True).float()
d_results = self.D(x).cpu().data.numpy()
return d_results.reshape(batch_size)