在研究hadoop的过程中,当然需要部署hadoop集群,本文是hadoop集群部署的先导课,要深入研究hadoop,本课程内容是必须学习的。
这里我们使用的是centos6.8+vmware12
1 虚拟机网络模式设置为NAT

最后,重新启动系统。
[root@hadoop101 ~]# sync
[root@hadoop101 ~]# reboot
1.1 克隆虚拟机
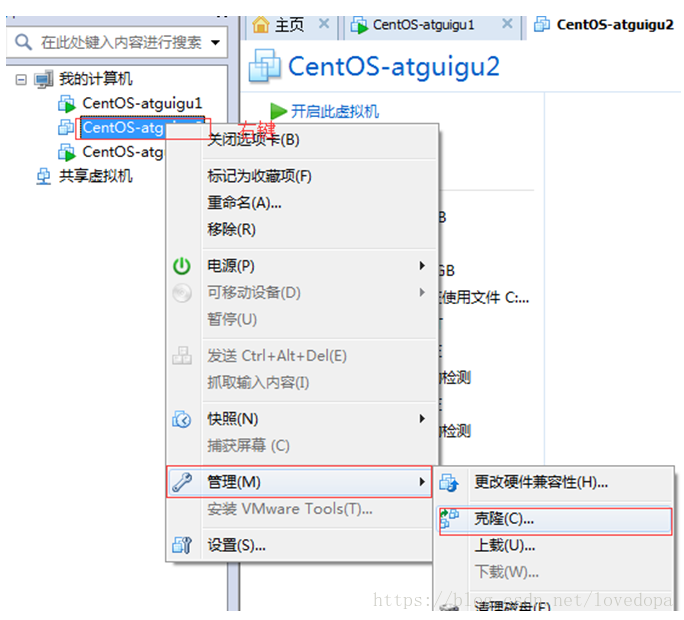


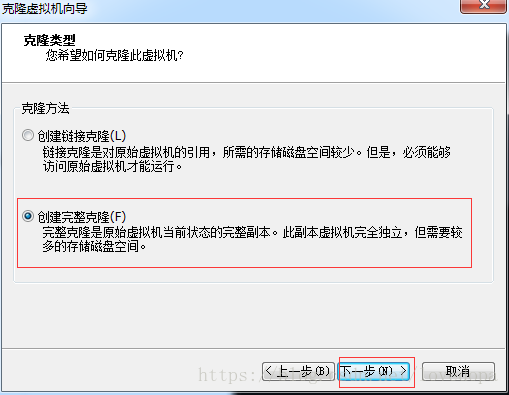



启动虚拟机!
1.2 设置虚拟机为静态ip
1)在终端命令窗口中输入
[root@hadoop101 /]#vim /etc/udev/rules.d/70-persistent-net.rules
进入如下页面,删除eth0该行;将eth1修改为eth0,同时复制物理ip地址

2)修改IP地址
[root@hadoop101 /]# vim /etc/sysconfig/network-scripts/ifcfg-eth0
需要修改的内容有5项:
IPADDR=192.168.1.101
GATEWAY=192.168.1.2
ONBOOT=yes
BOOTPROTO=static
DNS1=192.168.1.2
(1)修改前

(2)修改后

:wq 保存退出
3)执行
[root@hadoop101 /]# service network restart

4)如果报错,reboot,重启虚拟机。
[root@hadoop101 /]# reboot
1.3 修改主机名
1)修改linux的hosts文件
(1)进入Linux系统查看本机的主机名。通过hostname命令查看。
[root@hadoop100 /]# hostname
hadoop100
(2)如果感觉此主机名不合适,我们可以进行修改。通过编辑/etc/sysconfig/network文件。
[root@hadoop100~]# vi /etc/sysconfig/network
修改文件中主机名称
NETWORKING=yes
NETWORKING_IPV6=no
HOSTNAME= hadoop101
注意:主机名称不要有“_”下划线
(3)打开此文件后,可以看到主机名。修改此主机名为我们想要修改的主机名hadoop101。
(4)保存退出。
(5)打开/etc/hosts
[root@hadoop100 ~]# vim /etc/hosts
添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108
192.168.1.109 hadoop109
192.168.1.110 hadoop110
(6)并重启设备,重启后,查看主机名,已经修改成功
2)修改window7的hosts文件
(1)进入C:\Windows\System32\drivers\etc路径
(2)打开hosts文件并添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108
192.168.1.109 hadoop109
192.168.1.110 hadoop110
1.4 关闭防火墙
1)查看防火墙开机启动状态
[root@hadoop101 ~]# chkconfig iptables --list
2)关闭防火墙
[root@hadoop101 ~]# chkconfig iptables off
1.5 创建用户-操作hadoop
)创建itstar用户
在root用户里面执行如下操作
| [root@hadoop101 opt]# adduser itstar [root@hadoop101 opt]# passwd itstar 更改用户 test 的密码 。 新的 密码: 无效的密码: 它没有包含足够的不同字符 无效的密码: 是回文 重新输入新的 密码: passwd: 所有的身份验证令牌已经成功更新。 |
2)设置itstar用户具有root权限
修改 /etc/sudoers 文件,找到下面一行,在root下面添加一行,如下所示:
[root@hadoop101 itstar]# vi /etc/sudoers
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
itstar ALL=(ALL) ALL
修改完毕,现在可以用itstar帐号登录,然后用命令 su - ,即可获得root权限进行操作。
3)在/opt目录下创建文件夹
(1)在root用户下创建module、software文件夹
[root@hadoop101 opt]# mkdir module
[root@hadoop101 opt]# mkdir software
(2)修改module、software文件夹的所有者
[root@hadoop101 opt]# chown itstar:itstar module
[root@hadoop101 opt]# chown itstar:itstar sofrware
[root@hadoop101 opt]# ls -al
总用量 16
drwxr-xr-x. 6 root root 4096 4月 24 09:07 .
dr-xr-xr-x. 23 root root 4096 4月 24 08:52 ..
drwxr-xr-x. 4 itstar itstar 4096 4月 23 16:26 module
drwxr-xr-x. 2 itstar itstar 4096 4月 23 16:25 software
1.6 JDK安装
1)卸载现有jdk
(1)查询是否安装java软件:
[root@hadoop101 opt]# rpm -qa|grep java
(2)如果安装的版本低于1.7,卸载该jdk:
[root@hadoop101 opt]# rpm -e 软件包
2)用SecureCRT工具将jdk、Hadoop-2.7.2.tar.gz导入到opt目录下面的software文件夹下面


3)在linux系统下的opt目录中查看软件包是否导入成功。
[root@hadoop101opt]# cd software/
[root@hadoop101software]# ls
hadoop-2.7.2.tar.gz jdk-8u144-linux-x64.tar.gz
4)解压jdk到/opt/module目录下
[root@hadoop101software]# tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
5)配置jdk环境变量
(1)先获取jdk路径:
[root@hadoop101 jdk1.8.0_144]# pwd
/opt/module/jdk1.8.0_144
(2)打开/etc/profile文件:
[root@hadoop101 jdk1.8.0_144]# vi /etc/profile
在profie文件末尾添加jdk路径:
##JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
(3)保存后退出:
:wq
(4)让修改后的文件生效:
[root@hadoop101 jdk1.8.0_144]# source /etc/profile
(5)重启(如果java -version可以用就不用重启):
[root@hadoop101 jdk1.8.0_144]# sync
[root@hadoop101 jdk1.8.0_144]# reboot
6)测试jdk安装成功
[root@hadoop101 jdk1.8.0_144]# java -version
java version "1.8.0_144"
1.7 hadoop简介
Apache的Hadoop是一个开源的、可靠的、可扩展的系统架构,可利用分布式架构来存储海量数据,以及实现分布式的计算。
Hadoop许使用简单的编程模型在计算机集群中对大型数据集进行分布式处理。可以从单个服务器扩展到数千台机器,
每个机器都提供本地计算和存储,而不是依靠硬件来提供高可用性。
此外,Hadoop集群的高可用性也非常良好,因为框架内的机制是可以够自动检测和处理故障。
hadoop名字的来源:这个名字不是一个缩写,它是一个虚构的名字。该项目的创建者,Doug Cutting如此解释
Hadoop的得名:"这个名字是我孩子给一头吃饱了的棕黄色大象命名的。我的命名标准就是简短,容易发音和拼写,
没有太多的意义,并且不会被用于别处。小孩子是这方面的高手。
1.8 下载hadoop
第一种方式:官网下载 http://hadoop.apache.org/releases.html
第二种方式:百度网盘2.7.1版本 链接: https://pan.baidu.com/s/1Nkp4hQEMWblKqdBvj-lUZA 密码: yy18
下载后,把hadoop上传到/opt/software目录下
1.9 haddoop运行模式
(1)官方网站:
(2)各个版本归档库地址
https://archive.apache.org/dist/hadoop/common/hadoop-2.7.2/
(3)hadoop2.7.2版本详情介绍
http://hadoop.apache.org/docs/r2.7.2/
单机模式:不能使用HDFS,只能使用MapReduce,所以单机模式最主要的目的是在本机调试mapreduce代码
伪分布式模式:用多个线程模拟多台真实机器,即模拟真实的分布式环境。
完全分布式模式:用多台机器(或启动多个虚拟机)来完成部署集群。(本次用这个)
2 安装hadoop
1)进入到Hadoop安装包路径下:
[root@hadoop101 ~]# cd /opt/software/
2)解压安装文件到/opt/module下面
[root@hadoop101 software]# tar -zxf hadoop-2.7.2.tar.gz -C /opt/module/
3)查看是否解压成功
[root@hadoop101 software]# ls /opt/module/
hadoop-2.7.2
4)在/opt/module/hadoop-2.7.2/etc/hadoop路径下配置hadoop-env.sh
(1)Linux系统中获取jdk的安装路径:
[root@hadoop101 jdk1.8.0_144]# echo $JAVA_HOME
/opt/module/jdk1.8.0_144
(2)修改hadoop-env.sh文件中JAVA_HOME 路径:
[root@hadoop101 hadoop]# vi hadoop-env.sh
修改JAVA_HOME如下
export JAVA_HOME=/opt/module/jdk1.8.0_144
5)将hadoop添加到环境变量
(1)获取hadoop安装路径:
[root@ hadoop101 hadoop-2.7.2]# pwd
/opt/module/hadoop-2.7.2
(2)打开/etc/profile文件:
[root@ hadoop101 hadoop-2.7.2]# vi /etc/profile
在profie文件末尾添加jdk路径:(shitf+g)
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
(3)保存后退出:
:wq
(4)让修改后的文件生效:
[root@ hadoop101 hadoop-2.7.2]# source /etc/profile
(5)重启(如果hadoop命令不能用再重启):
[root@ hadoop101 hadoop-2.7.2]# sync
[root@ hadoop101 hadoop-2.7.2]# reboot
6)修改/opt目录下的所有文件所有者为itstar
[root@hadoop101 opt]# chown itstar:itstar -R /opt/
7)切换到itstar用户
[root@hadoop101 opt]# su itstar