ID3->C4.5->C5.0

Decision Tree theory
1、所有的数据放在根节点
2、分堆

注意事项:
1、属性选择的结果是目标变量偏向于一个值
2、砍树。(防止过拟合)


1、越倾向于1越平均化;倾向于0越偏某一类。 交叉熵在0-1之间。



注意事项
1、决策树和规则不一样。规则是提取的精华。决策树是有繁琐的规则在的。
2、分类规则的算法和决策树不一样。WEKA提供。modeler不提供分类规则算法。
ID3的缺点:
1、字段选择的时候,喜欢分支度越多。使得一个分支趋向于0或者1。因为这样会使Information Gain增大。(比如 ID进入决策树,在测试机无法预测。
2、所有的变量是离散的。无法处理离散的数据。
3、没法处理空值
4、无法砍树,无法防止过拟合。
ID3 每个节点的分支度不同。
C4.5的改进: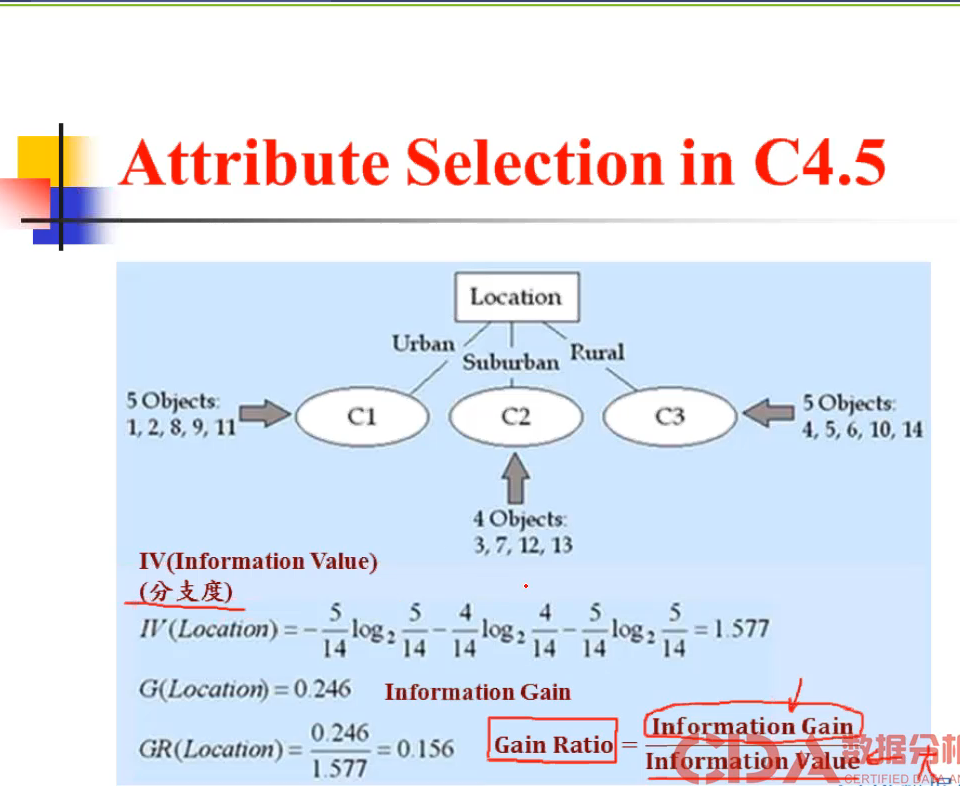
C4.5的特点
1、可以处理数值型数据。找Gain ration 的最大切点。可以分为二叉树的类型;类别型的话有几类分几类。

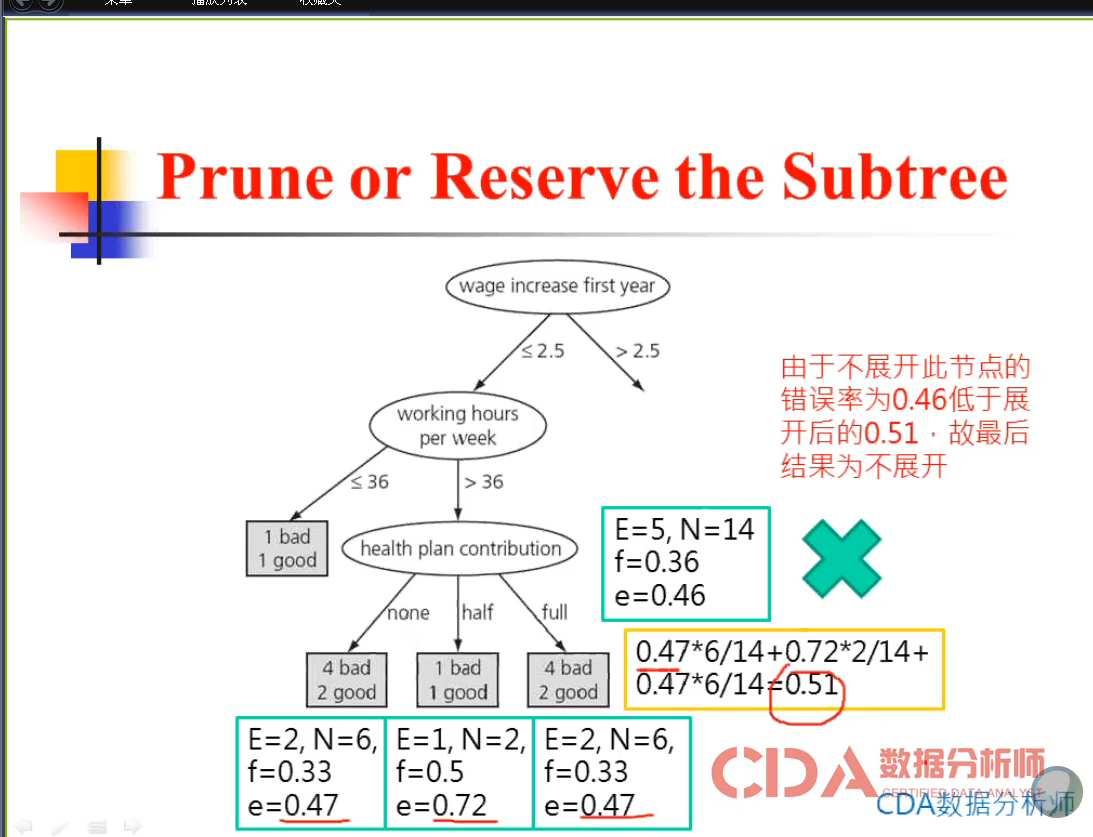
2、可以砍树。
修剪法:从下往上(C4.5/CART)
盆栽法:(top-down)--CHAID
在25% 的信息水准下:
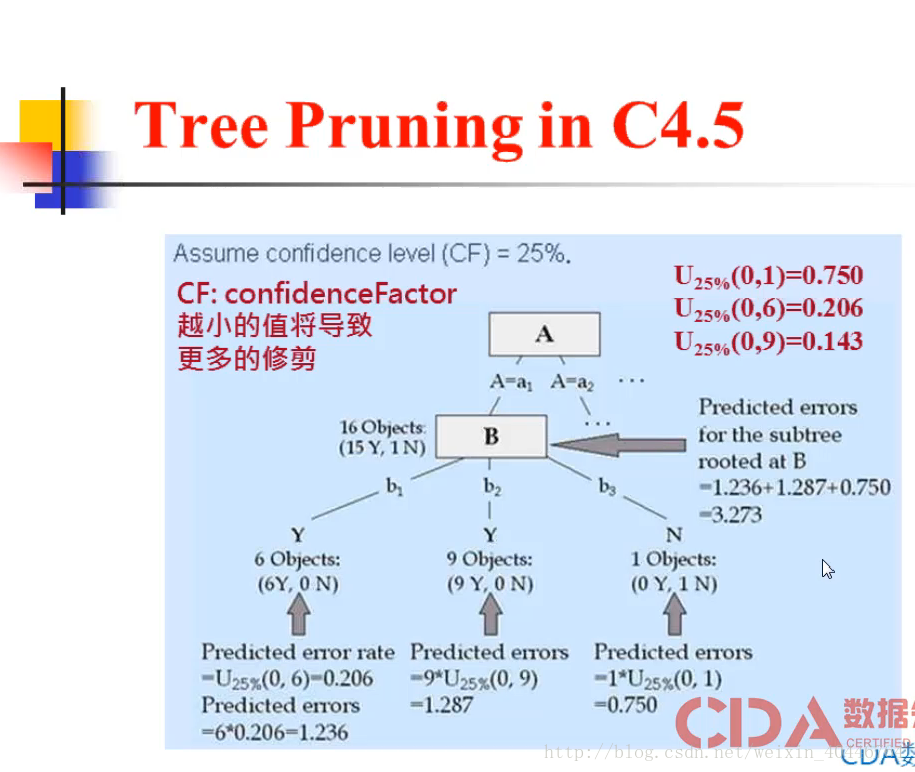


在这样的水平下,在信息水准的水平下。错误率会提升。

3、C4.5可以处理空值和数值型的字段。
CART算法:


Gini =[0-1/2] 之间 0(偏某类)-1/2 (平均)
熵: 越趋向于1越平均。

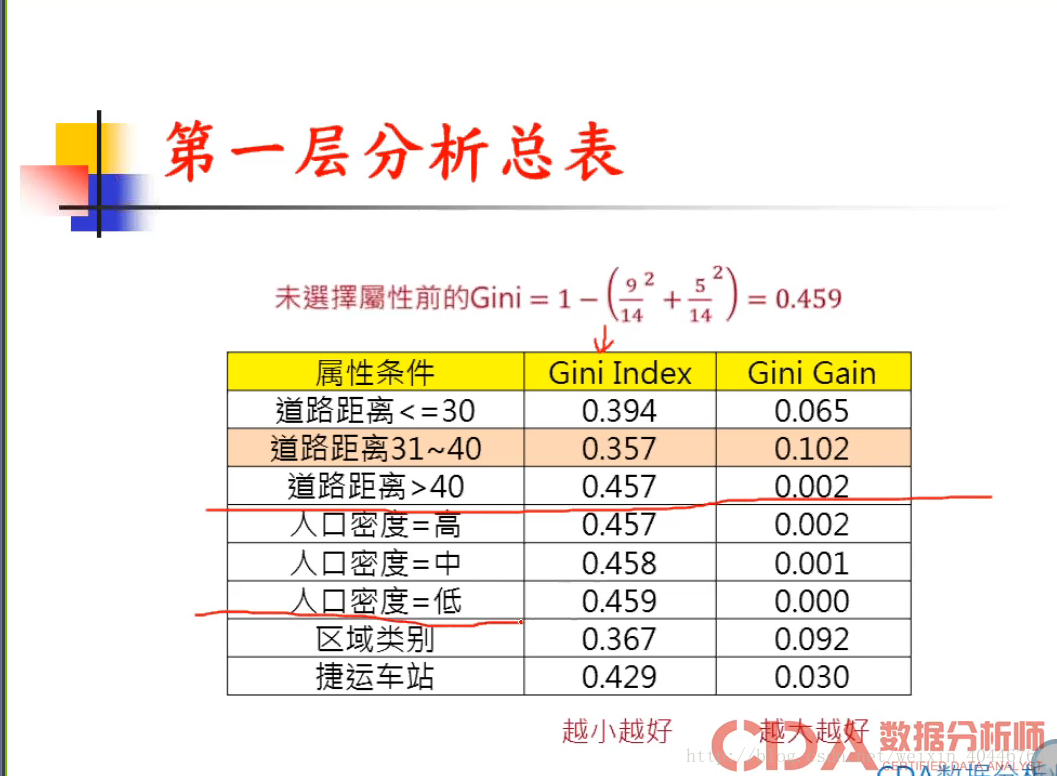
注意事项:
1、可以重复使用各个节点。
2、CART的砍树方法:

CART:可以处理数值型字段;可以砍树。
CHAID:


