目录
Tesla V100-SXM2-32gb 英伟达驱动安装
屏蔽原本的驱动
屏蔽nouveau开源版本的GPU驱动;
当系统安装完成之后,会安装系统开源的NVIDIA驱动版本,名称为nouveau。下面将屏蔽该驱动。
首先,创建/etc/modprobe.d/blacklist-nouveau.conf文件,
sudo vim /etc/modprobe.d/blacklist-nouveau.conf
将下面内容添加进去:
blacklist nouveau
blacklist lbm-nouveau
options nouveau modeset=0
alias nouveau off
alias lbm-nouveau off
创建/etc/modprobe.d/nouveau-kms.conf文件,将options nouveau mdeset=0添加进去:
sudo vim /etc/modprobe.d/nouveau-kms.conf
启动一下:
$ echo options nouveau modeset=0 | sudo tee -a /etc/modprobe.d/nouveau-kms.conf
更新一下initramfs
sudo update-initramfs -u
重启服务器:
sudo reboot
查看nouveau模块是否加载,不显示的话就表示已经禁用:
sudo lsmod | grep nouveau
方法1:官网离线下载安装
下载驱动
系统安装完成之后,进入系统,使用lspci 命令查询一下GPU是否存在、型号信息是什么。
sudo lspci |grep -i nvidia
2f:00.0 3D controller: NVIDIA Corporation GV100GL [Tesla V100 PCIe 16GB] (rev a1)
86:00.0 3D controller: NVIDIA Corporation GV100GL [Tesla V100 PCIe 16GB] (rev a1)
下载NVIDIA Tesla V100驱动;
通过lspci查询到GPU的型号之后,访问官网https://www.nvidia.com/download/index.aspx?lang=en-us下载驱动程序可以按照如下选择,选择产品类型、系列、型号、然后根据自己的操作系统来选择。
注意:如果操作系统是Linux,尽量选择Linux 32-bit/Linux 64-bit
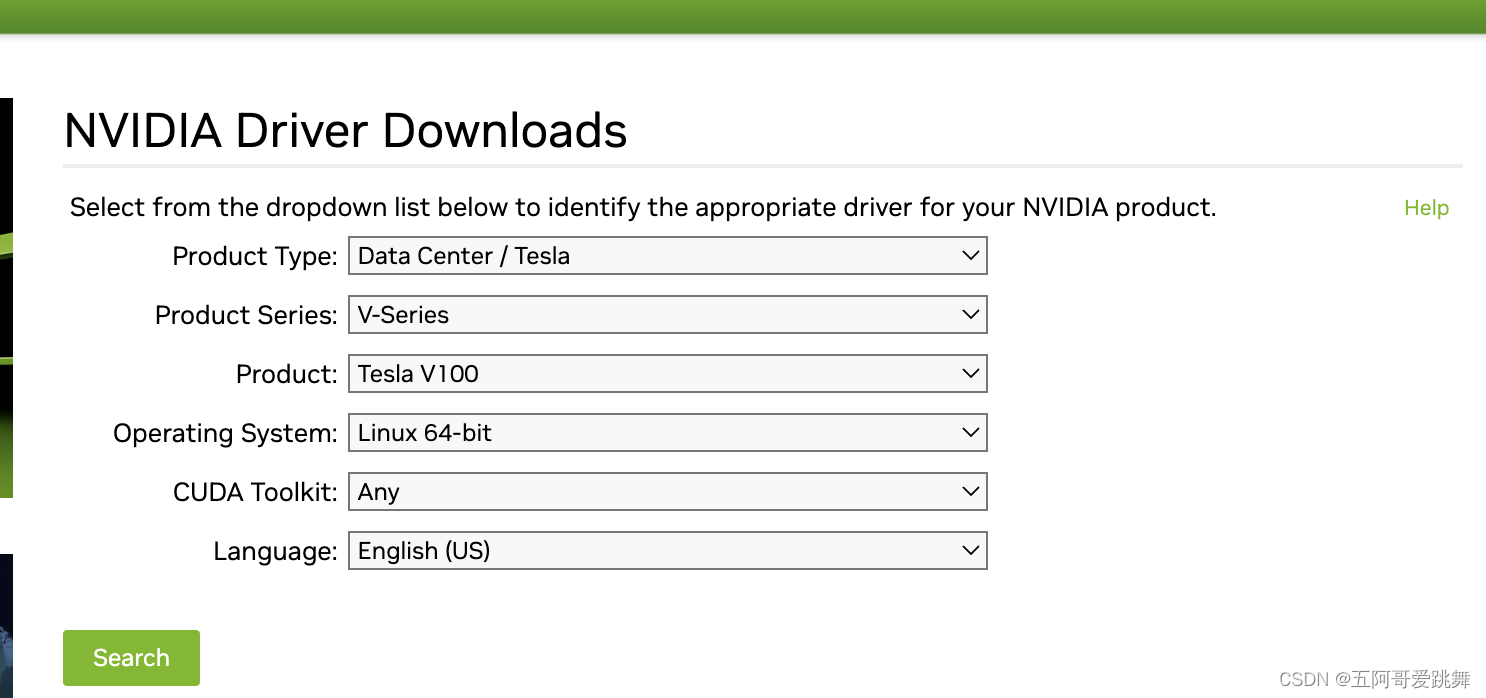
下载后安装
安装gcc等依赖包
当安装GPU驱动时,提示缺少相关的依赖包,在此,我们需要提前安装相关的依赖包,目前需要用到的是gcc , g++ , make :
sudo apt install gcc g++ make
方法2:在线安装
添加nvidia驱动的ppa源并进行安装
sudo add-apt-repository ppa:graphics-drivers/ppa
查看可选驱动版本,输入以下命令:
ubuntu-drivers devices
安装nvidia驱动及其依赖的包
sudo apt update
sudo apt install nvidia-470 #(此处安装驱动以实际输出信息为准,一般安装后面提示recommended的,如图中nvidia-driver-470)
sudo apt-get install mesa-common-dev
sudo apt-get install freeglut3-dev
再次重启reboot
sudo reboot
打开终端输入nvidia-smi,若出现以下类似界面表示驱动安装完成。
nvidia-smi
安装cuda
官方匹配列表:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
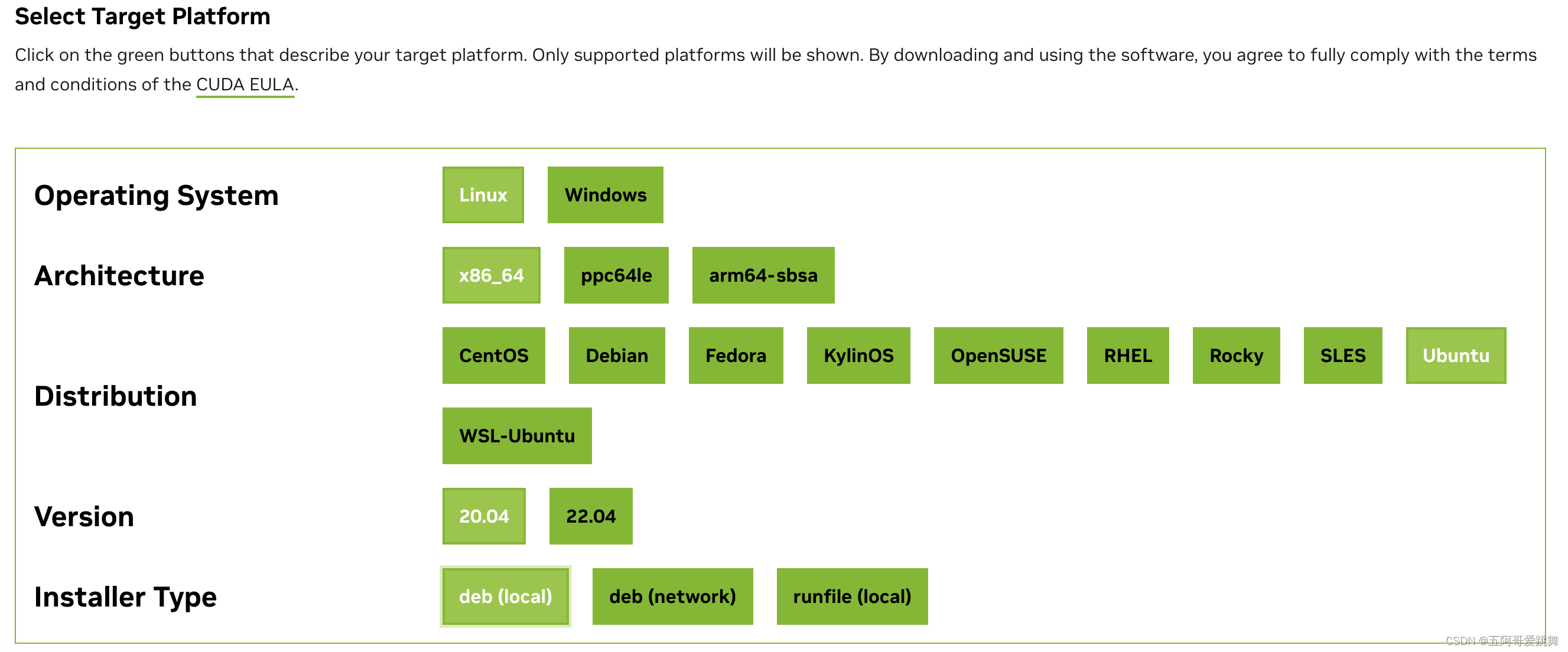
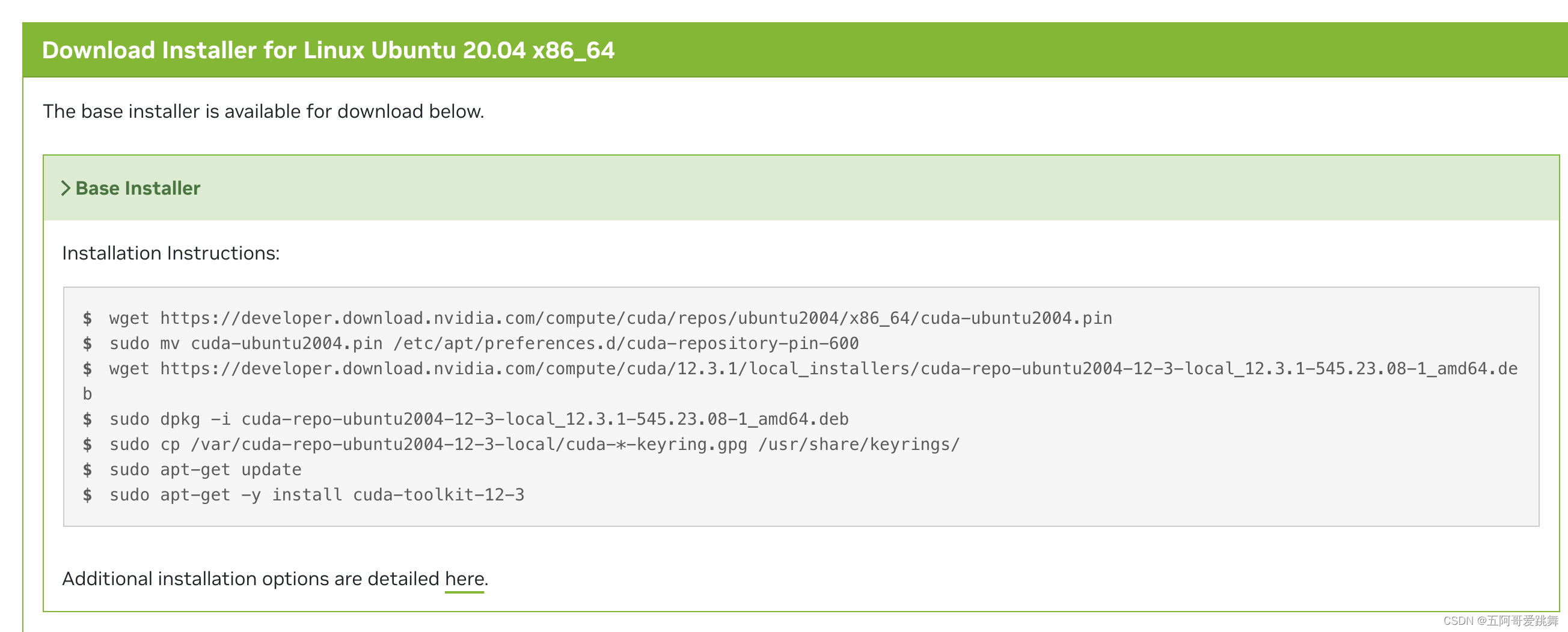
逐条输入安装即可。
配置环境变量如下,打开终端,输入以下命令
sudo vim ~/.bashrc
在打开文件的最下方依次输入以下内容,路径要根据自己的文件修改一下
export CUDA_HOME=/usr/local/cuda
export PATH=$PATH:$CUDA_HOME/bin
export LD_LIBRARY_PATH=/usr/local/cuda-12.3/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
保存并退出:wq,使环境变量生效
打开终端输入:source ~/.bashrc
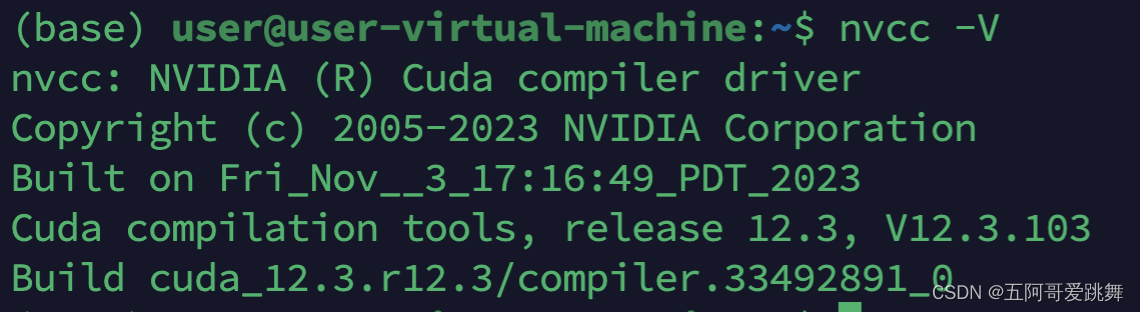
验证cuda是否安装完成,打开终端输入:
nvcc -V
若显示以下类似的界面,说明cuda驱动安装完成。
安装cudaa
先去nvidia官网下载所需的文件: https://developer.nvidia.com/rdp/cudnn-archive
可以根据nvidia-smi提示根据cuda版本选择cudnn
下载后放到linux中解压。
注意如果是tar.xz文件,需要两步解压。
cudnn-linux-x86_64-8.9.6.50_cuda11-archive.tar.xz
两步解压:
xz -d cudnn-linux-x86_64-8.9.6.50_cuda12-archive.tar.xz
tar zxvf cudnn-linux-x86_64-8.9.6.50_cuda12-archive.tar
// 可以看到这个压缩包也是打包后再压缩,外面是xz压缩方式,里层是tar打包方式。
$ xz -d ***.tar.xz
$ tar -xvf ***.tar
tar包压缩的时候用cvf参数,解压的时候用xvf参数(用此命令解决了)
或压缩的时候用czvf参数,解压的时候用xzvf参数(常用,这次报了这个错)
解压后把文件移入:
先给cudnn-linux-x86_64-8.9.6.50_cuda12-archive重命名为cuda12-archive
cd /usr/local/cuda
sudo cp -p /home/user/software/cuda12-archive/include/cudnn*.h include/
sudo cp -p /home/user/software/cuda12-archive/lib/libcudnn* lib64/
sudo chmod a+r /usr/local/cuda-12.3/include/cudnn.h #释放cudnn.h文件权限给所有用户
sudo chmod a+r /usr/local/cuda-12.3/lib64/libcudnn*
nvidia-smi
安装完cudnn和pytorch后,可以进一步测试cudnn是否可用
#检查cuda
import torch
torch.cuda.is_available() # 检查cuda是否可用
torch.version.cuda # 查看cuda版本
#检查cudnn
torch.backends.cudnn.is_available() # 检查cudnn是否可用
torch.backends.cudnn.version() # 查看cudnn版本
参考资料
1、https://blog.csdn.net/weixin_46674639/article/details/126429113
2、https://blog.csdn.net/linuxprobe18/article/details/123868432
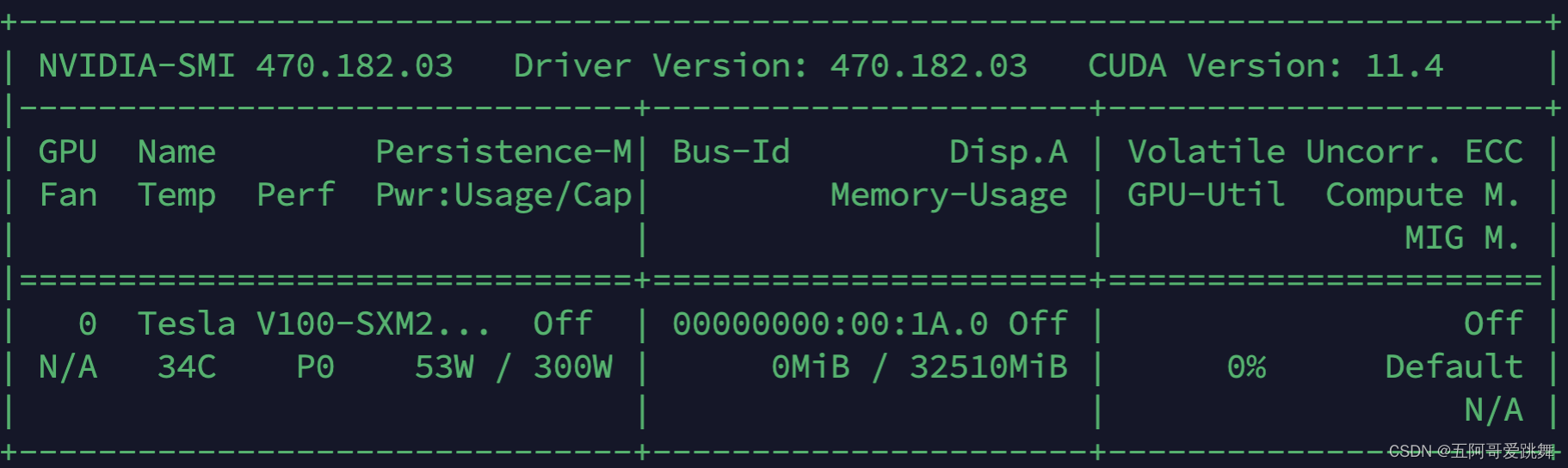
系统基本信息
`nvidia-smi’
nvidia-smi 470.182.03 driver version:470.182.03 cuda version: 11.4
查看系统体系结构
uname -a
- UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
下载miniconda
https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/?C=M&O=A
https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh
注意路径,用bash命令去安装。
认真看安装过程提示信息,需要按Enter (回车键)或者输入yes,(如果输入yes时,不小心输多了,就按control和退格键删除),
(1)看到more就是按空格键翻页查看协议,按q退出

(2)接受协议,输入yes
(3)默认安装路径,按enter
(4)会询问是否需要初始化,输入yes

(5)显示安装已完成的提示信息
激活刚安装完成的软件
一般安装软件完成后需要重启,在Linux叫激活,有两种方式,第一种是重新登录服务器,第二种是输入以下命令:
source ~/.bashrc
##比较常用
配置conda镜像地址
conda config --add channels r
conda config --add channels conda-forge
conda config --add channels bioconda
#(1)下面这四行配置清华大学的conda的channel地址,国内用户推荐
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
conda config --set show_channel_urls yes
##配置清华镜像,四句代码一起复制粘贴到服务器
# (2)下面四行配置北京外国语大学的conda的channel地址
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/conda-forge/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/bioconda/
conda config --set show_channel_urls yes
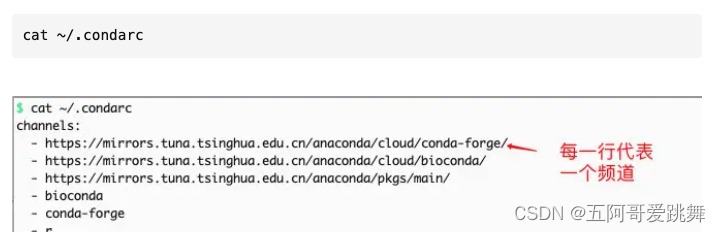
查看配置镜像结果
配置镜像完成后会出现一个.condarc 文件,会在 ~/.condarc 文件中 写入以下内容
安装pytorch
从官网找版本
https://pytorch.org/
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
安装huggingface&离线下载LLama2并在本地运行全流程
配置所需环境
尝试过 torch 1.12.1,发生报错,
module 'torch' has no attribute 'fx'
故从头开始,配置torch 2.1.0成功。
conda create -n hfllama2 python=3.10.13
conda activate hfllama2
# 从官网上找的,尽管和系统有些不匹配,但是work
pip install torch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 --index-url https://download.pytorch.org/whl/cu118
pip install transformers
最终用到的完整的包版本如下(很简洁):
Package Version
------------------ ------------
accelerate 0.24.1
certifi 2022.12.7
charset-normalizer 2.1.1
filelock 3.9.0
fsspec 2023.10.0
huggingface-hub 0.19.4
idna 3.4
Jinja2 3.1.2
MarkupSafe 2.1.3
mpmath 1.3.0
networkx 3.0
numpy 1.24.1
packaging 23.2
Pillow 9.3.0
pip 23.3.1
psutil 5.9.6
PyYAML 6.0.1
regex 2023.10.3
requests 2.28.1
safetensors 0.4.0
setuptools 68.2.2
sympy 1.12
tokenizers 0.15.0
torch 2.1.0+cu118
torchaudio 2.1.0+cu118
torchvision 0.16.0+cu118
tqdm 4.66.1
transformers 4.35.2
triton 2.1.0
typing_extensions 4.4.0
urllib3 1.26.13
wheel 0.41.3
llama2离线下载
对该镜像进行封装的工具包:https://github.com/LetheSec/HuggingFace-Download-Accelerator
可以下载数据和模型。
# 安装依赖
pip install -U huggingface_hub
# 环境变量
export HF_ENDPOINT=https://hf-mirror.com
注意下载llama2时的token要用write类型。
huggingface-cli download --token hf_XX你的tokenXX --resume-download --local-dir-use-symlinks False meta-llama/Llama-2-7b-hf --local-dir Llama-2-7b-hf
下载数据:
huggingface-cli download --resume-download --local-dir-use-symlinks False --repo-type dataset empathetic_dialogues --local-dir empathetic_dialogues
运行官方测试代码
代码地址:https://huggingface.co/blog/zh/llama2
from transformers import AutoTokenizer
import transformers
import torch
model = "Llama-2-7b-hf" #注意,这里改成下载好的离线模型的相对路径了
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?\n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {
seq['generated_text']}")
报错小问题1:
huggingface_hub.utils._validators.HFValidationError: Repo id must use alphanumeric chars or '-', '_', '.', '--' and '..' are forbidden, '-' and '.' cannot start or end the name, max length is 96:
原因是官方代码用的是在线模式,地址用的简称,不对改成离线地址后用的是./XXX的格式,报此错误,直接改成相对路径’XXX’work了。
报告小问题2:
ImportError: Using low_cpu_mem_usage=True or a device_map requires Accelerate: pip install accelerate
安装一下包用于GPU加速:
pip install accelerate
打印结果:

“简简单单”搞了一天…
明天醒了再把13B测一下,估计问题不大。
20231127: 相同的流程,13B测试成功,当前方法可行!