文章目录
翻译
Abstract
随着大规模、真实世界数据集的迅速增加,长尾数据分布问题的解决变得至关重要(即少数类占了大部分数据,而大多数类的代表性不足)。现有的解决方案通常采用类重新平衡策略,例如根据每个类的观察数量重新采样和重新加权。在这项工作中,我们认为,随着样本数量的增加,新添加的数据点的额外好处将减少。我们引入了一个新的理论框架来测量数据重叠,方法是将每个样本与一个小的邻近区域联系起来,而不是单个点。有效的样本被定义为样品的体积,可以通过一个简单的公式计算 ( 1 − β n ) / ( 1 − β ) (1−β^n) /(1−β) (1−βn)/(1−β),其中 n n n是样本的数量, β ∈ ( 0 , 1 ) β∈(0,1) β∈(0,1)是一个超参数。我们设计了一个权重调整方案,利用每个类的有效样本数来重新平衡损失,从而产生一个类平衡损失。对人工生成的长尾CIFAR数据集和包括ImageNet和iNaturalist在内的大规模数据集进行了综合实验。我们的结果显示,当使用提出的类平衡损失训练时,网络能够在长尾数据集上获得显著的性能增益。
1. Introduction
深度卷积神经网络(CNNs)最近在视觉识别方面的成功[25,36,37,16]在很大程度上归功于大规模的、现实世界的带注释数据集[7,27,48,40]的可用性。与常用的视觉识别的数据集(例,CIFAR[24,39],ImageNet ILSVRC 2012[7, 33]和CUB-200 Birds[42]),表现出大致均匀分布的类标签,现实世界的数据集[21]都有着倾斜的分布,有着一条长尾分布:意思是几个主导类占据大多数例子,而大多数其他的类只有着相对较少的例子。对这些数据进行训练的CNNs在弱表示类中表现较差[19,15,41,4]。
最近的一些研究旨在缓解长尾训练数据的挑战[3,31,17,41,43,12,47,44]。一般来说,有两种策略:重采样和成本敏感的重新加权。在重采样中,通过对次要类进行过采样(添加重复数据)或对主要类进行欠采样(删除数据),或两者同时进行,可以直接调整样本的数量。在成本敏感的权重调整中,我们通过将相对较高的成本分配给来自较小类的样本来影响损失函数。在使用CNNs进行深度特征表示学习的情况下,重采样可能会引入大量的重复样本,从而降低了训练速度;模型在过采样时容易出现过拟合,或者在欠采样时可能丢弃对特征学习很重要的有价值的样本。由于在CNN训练中使用重采样的这些缺点,本文的工作重点是重新加权的方法,即如何设计一个更好的类平衡损失。
典型地,一个类平衡损失分配的样本权值与类频率成反比。这种简单的启发式方法已被广泛采用[17,43]。然而,最近针对大规模、真实世界、长尾数据集的训练工作[30,28]表明,在使用这种策略时,性能很差。相反,他们使用一种“平滑”版本的权值,这种权值根据经验设置为与类频率的平方根成反比。这些观察提出了一个有趣的问题:我们如何设计一个适用于不同数据集数组的更好的类平衡损失?
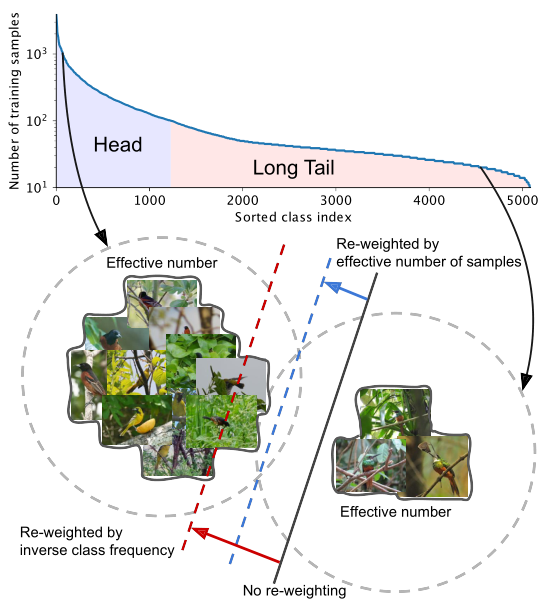
图1. 两个类,一个来自长尾数据集的头部,一个来自尾部(本例中为iNaturalist 2017[41]),其样本数量截然不同。在这些样本上训练的模型偏向于优势类(黑色实线)。在现实世界中具有高度类不平衡的数据上,通过反类频率重新权衡损失通常会产生糟糕的性能(红色虚线)。我们提出了一个理论框架,通过考虑数据重叠来量化样本的有效数量。我们设计了一个类平衡项,通过反有效样本数来重新权衡损失。我们在实验中表明,当用提议的类平衡损失进行训练时,模型的性能可以得到改善(蓝色虚线)。
我们打算从样本容量的角度来回答这个问题。如图1所示:我们考虑训练一个模型来区分来自长尾数据集的主类和次类。由于数据的高度不平衡,直接训练模型或通过反样本数来重新加权损失都不能得到令人满意的结果。直观地说,数据越多越好。然而,由于数据之间存在信息重叠,随着样本数量的增加,模型从数据中提取的边际效益也随之减少。基于此,我们提出了一种新的理论框架来描述数据重叠,并在模型和损失不可知的情况下计算样本的有效数量。在损失函数中加入一个与有效样本数成反比的类平衡权重项。大量的实验结果表明,这个类平衡项显著地提高了长尾数据集上训练CNNs的常用损失函数的性能。
我们的主要贡献如下:(1)我们提供了一个理论框架来研究样本的有效数量,并展示了如何设计一个类平衡项来处理长尾训练数据。(2)我们证明,在现有的常用损失函数(包括softmax cross-entropy, sigmoid cross-entropy和focal loss)中加入所提出的类平衡项可以显著地改善性能。此外,我们证明了我们的类平衡损失可以作为视觉识别的一个通用损失,在ILSVRC 2012上表现优于常用的softmax cross-entropy。我们相信,我们对样本有效数量和类平衡损失的量化研究可以为长尾类分布领域的研究人员提供有用的指导。
2. Related Work
以往对长尾不平衡数据的研究主要分为两种情况:重新采样([35,12,4,50]包括过采样和欠采样)和成本敏感学习[38,49,17,22,34]。
Re-Sampling。过采样增加了小类的重复采样,这可能导致模型过度拟合。为了解决这个问题,可以从相邻的样本[5]中插入新的样本,或者对较小的类进行合成[14,50]。然而,由于新样本中存在噪声,模型仍然容易出错。有人认为,即使欠抽样会带来删除重要样本的风险,欠抽样仍比过度抽样更可取。

Cost-Sensitive Learning。成本敏感学习可以追溯到统计学中的一个经典方法,称为重要性抽样[20],在这个方法中,为了匹配给定的数据分布,为样本分配权重。Elkan等人研究了在二分类的情况下,如何分配权重来调整决策边界以匹配给定的目标。对于不平衡的数据集,通常采用类频率的倒数[17,43]加权或类频率平方根的倒数平滑版本[30,28]。作为基于理论框架的平滑加权的推广,我们关注(a)如何量化样本的有效数量和(b)使用它来重新加权损失。另一项重要的工作是研究样本在损失方面的难度,并将更高的权重分配给困难样本[11,29,8,26]。小类的样本比大类的样本损失更大,因为小类学习的特征通常更差。然而,样本难度与样本数量之间并没有直接的联系。给困难样本分配更高的权重的一个副作用是会关注有害的样本(例如,有噪声的数据或错误标记的数据)[23,32]。在我们的工作中,我们没有对样本的难度和数据分布做任何假设。在实验中利用类平衡项对focal loss[26]进行了改进,证明了该方法与基于样本难度的重加权方法是互补的。
值得一提的是,之前的工作也探索了处理数据不平衡的其他方法,包括将大类学到的知识转移到小类[3,31,43,6,44],并通过度量学习设计更好的训练目标[17,47,45]。
Covering and Effective Sample Size。我们的理论框架是受到随机覆盖问题[18]的启发,其中的目标是覆盖一个由一系列的随机小集合组成的大的集合。我们通过作出合理的假设来简化第3节中的问题。注意,本文提出的有效样本量与统计中有效样本量的概念不同。有效样本容量用于计算样本相关时的方差。
3. Effective Number of Samples
我们将数据抽样过程表示为随机覆盖的简化版本。关键的思想是将每个样本与一个小的邻近区域联系起来,而不是单个点。给出了计算有效样本数的理论框架和公式。
3.1 Data Sampling as Random Covering
给定一个类别,定义这个类特征空间的所有可能的数据集合为 S S S。假设 S S S的体积为 N N N并且 N ≥ 1 N\ge1 N≥1。定义每一个数据都是 S S S的子集并且体积都是单位体积 1 1 1,每个数据都有可能和其他数据重叠。考虑随机覆盖数据采样的过程,每个数据(也就是子集)都有可能被采样,最终目的是能够覆盖集合 S S S的全部可能。采样的数据越多,对集合 S S S的覆盖越好。采样数据的期望体积会随机数据量的增加而增加,最终的边界是 N N N。
定义 1(有效数字)。有效样本数 N N N是样本的期望体积。
样本期望体积的计算是一个非常困难的问题,它取决于样本的形状和特征空间[18]的维数。为了使问题易于处理,我们通过不考虑部分重叠的情况来简化问题。也就是说,我们假设一个新采样的数据只能以两种方式与之前采样的数据交互:要么完全在之前采样的数据集合内部,概率为 p p p,要么完全在外部,概率为 1 − p 1-p 1−p,如图2所示。随着采样数据点数量的增加,概率 p p p也会增大。
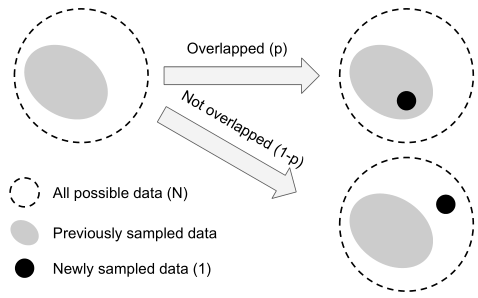
图2. 给出所有可能的体积为N的数据集和以前采样的数据集(对于一个类的数据有一批有效样本N,有效样本即数据完全不同的,如经过数据增强得到的k张数据只能算一个有效样本),取一个新样本,与已经采样的数据(灰色)部分重叠的概率为p,不重叠的概率为1-p
在深入研究数学公式之前,我们将讨论有效样本数量的定义与实际可视数据之间的关系。我们的想法是通过使用更多的类数据点来获取边际收益递减。由于真实世界数据之间的内在相似性,随着样本数量的增加,新添加的样本极有可能是现有样本的近似副本。此外,CNNs通过大量数据增强进行训练,对输入数据进行简单的转换,如随机剪切、重新缩放和水平翻转。在这种情况下,所有的增强样本也被认为与原始示例相同(即增强样本判断为与之前采样的数据重叠的样本,所以完全不同的样本才能算一个有效样本)。据推测,数据增强越强, N N N(即有效样本数)就越小。样本的小邻域是一种通过数据增强来捕获所有近重复项和实例的方法。对于一个类, N N N可以看作是唯一原型(即完全不一样的样本)的数量。
3.2 Mathematical Formulation
定义有效样本数为 E n E_n En,其中 n ∈ Z > 0 n \in \mathbb Z_{>0} n∈Z>0表示样本的总数。
提议1(有效数字) E n = ( 1 − β n ) / ( 1 − β ) E_n=({1-\beta^n})/({1-\beta}) En=(1−βn)/(1−β),其中 β = N − 1 / N \beta = {N-1}/{N} β=N−1/N
证明:我们用归纳法来证明这个命题。显然,当没有重叠时 E 1 = 1 E_1 = 1 E1=1。所以 E 1 = ( 1 − β 1 ) / ( 1 − β ) = 1 E_1 =(1−β^1)/(1−β)= 1 E1=(1−β1)/(1−β)=1成立。现在,让我们考虑一个一般的情况,我们已经采样 n − 1 n - 1 n−1个样本,并即将抽样第 n n n个样本。现在,先前采样的数据的期望体积为 E n − 1 E_{n−1} En−1,而新采样的数据点与先前采样的数据点重叠的概率为 p = E n − 1 / N p = E_{n−1}/N p=En−1/N。因此,第 n n n个样本采样后的期望体积为:
E n = p E n − 1 + ( 1 − p ) ( E n − 1 + 1 ) = 1 + N − 1 N E n − 1 (1) E_n = pE_{n-1}+(1-p)(E_{n-1}+1)=1+\frac{N-1}NE_{n-1}\tag1 En=pEn−1+(1−p)(En−1+1)=1+NN−1En−1(1)
现在假设 E n − 1 = 1 − β n − 1 1 − β E_{n-1} = \frac{1-\beta^{n-1}}{1-\beta} En−1=1−β1−βn−1成立,那么: E n = 1 + β 1 − β n − 1 1 − β = 1 − β n 1 − β (2) E_n=1+\beta\frac{1-\beta^{n-1}}{1-\beta}=\frac{1-\beta^n}{1-\beta}\tag2 En=1+β1−β1−βn−1=1−β1−βn(2)
上式表明样本的有效数据量是总数 n n n的指数函数,超参数 β ∈ [ 0 , 1 ) \beta \in[0,1) β∈[0,1)控制随着的增长速
度。(即采样的 n n n数量增长,对应能有的有效样本 N N N的数量也跟着增长, β β β是一个设置的参数,一般设置为[0.9, 1))
有效数字 E n E_n En的另一种解释是: E n = ( 1 − β n ) / ( 1 − β ) = ∑ j = 1 n β j − 1 (3) E_n=({1-\beta^n})/({1-\beta})=\sum_{j=1}^n\beta^{j-1}\tag3 En=(1−βn)/(1−β)=j=1∑nβj−1(3)
这意味着第 j j j个样本贡献值 β j − 1 β^{j−1} βj−1到有效数字中。类中所有可能数据的总期望体积 N N N可以计算为: N = lim n → ∞ ∑ j = 1 n β j − 1 = 1 / ( 1 − β ) (4) N=\lim_{n\to \infty}\sum_{j=1}^n\beta^{j-1}=1/(1-\beta)\tag4 N=n→∞limj=1∑nβj−1=1/(1−β)(4)
这是符合我们一开始定义的 β β β命题(即 β = ( N − 1 ) / N β= (N−1) / N β=(N−1)/N。
推论 1(渐近性质)。如果 β = 0 β= 0 β=0 (即 N = 1 N = 1 N=1),则 E n = 1 E_n = 1 En=1。如果 β → 1 β→1 β→1(即 N → ∞ N→∞ N→∞),则 E n → n E_n→n En→n。
证明:如果 β = 0 β= 0 β=0,那么 E n = ( 1 − 0 n ) / ( 1 − 0 ) = 1 E_n = (1−0^n) /(1−0) = 1 En=(1−0n)/(1−0)=1
如果 β → 1 β→1 β→1,设 f ( β ) = 1 − β n f(β)= 1−β^n f(β)=1−βn 和 g ( β ) = 1 − β g(β)= 1−β g(β)=1−β。因为 lim β → 1 f ( β ) = lim β → 1 g ( β ) = 0 \lim_{β \to1} f(β) = \lim_{β→1} g(β)= 0 limβ→1f(β)=limβ→1g(β)=0,且 g ′ ( β ) = − 1 ≠ 0 g'(β)=−1\neq0 g′(β)=−1=0,那么 lim β → 1 f ′ ( β ) / g ′ ( β ) = lim β → 1 ( − n β n − 1 ) / ( − 1 ) = n \lim_{β→1} f'(β)/ g'(β) = \lim_{β→1} (−nβ^{n−1}) / (−1) = n limβ→1f′(β)/g′(β)=limβ→1(−nβn−1)/(−1)=n 存在, 那么使用洛必达法则得:
lim β → 1 E n = lim β → 1 f ( β ) g ( β ) = lim β → 1 f ′ ( β ) g ′ ( β ) = n (5) \lim_{\beta \to 1}E_n=\lim_{\beta \to 1}\frac{f(\beta)}{g(\beta)}=\lim_{\beta \to 1}\frac{f'(\beta)}{g'(\beta)}=n\tag5 β→1limEn=β→1limg(β)f(β)=β→1limg′(β)f′(β)=n(5)
E n E_n En的渐近性质表明,当 N N N较大时,样本的有效数量与样本的数量 n n n相同。在这种情况下,我们认为唯一原型的数量 N N N较大,因此没有数据重叠,每个样本都是唯一的。(当我们有这足够多的训练数据 n n n时,我们就能够认为其的样本有效数量值 N = n N=n N=n)在另一个极端,如果 N = 1 N = 1 N=1,这意味着我们相信存在一个单一的原型,所以这个类中的所有数据都可以通过数据增强、转换等由原型来表示。
4. Class-Balanced Loss
通过引入一个与样本有效数量 N N N成反比的权重因子,设计了类平衡损失来解决从不平衡数据进行训练的问题。类平衡损失项可应用于大范围的深度网络和损失函数。
输入样例 x x x 的标签为 y ∈ { 1 , 2 … , C } y\in \{1,2…,C\} y∈{
1,2…,C},这里 C C C 表示类别总数。假设模型得到的概率分布为 p = [ p 1 , p 2 … p C ] T \mathbf p=[p_1,p_2…p_C]^\mathbf T p=[p1,p2…pC]T,其中 p i ∈ [ 0 , 1 ) ∀ i p_i \in[0,1)\forall i pi∈[0,1)∀i。我们定义损失函数为 L ( p , y ) \mathcal L(\mathbf p,y) L(p,y),假设类别 i i i的样例数为 n i n_i ni,根据上一节的公式 2 可知对于类别 i i i有 E n i = 1 − β i n i 1 − β i E_{n_i} = \frac{1-\beta^{n_i}_i}{1-\beta_i} Eni=1−βi1−βini,这里 β i = N i − 1 N i \beta_i=\frac{N_i-1}{N_i} βi=NiNi−1。
通常来说,如果没有更多关于数据的信息,那么对每个类别来说很难找到合适的超参 N i N_i Ni。所以,通常假设 N i N_i Ni是独立的,并且对于每个类别都有 N i = N ; β i = β = N − 1 N N_i = N ; \beta_i=\beta = \frac{N-1}{N} Ni=N;βi=β=NN−1。
为了平衡损失,引入权重因子 α i \alpha_i αi,它和每个类 i i i的有效样本数成反比 α i ∝ 1 / E n \alpha_i\propto1/E_n αi∝1/En;为了保证总损失和之前大致一致,需要对权重因子归一化,得到 ∑ i = 1 C α i = C \sum^C_{i=1}\alpha_i=C ∑i=1Cαi=C。为了简化,接下来使用 1 E n i \frac1{E_{n_i}} Eni1表示归一化的权重因子。
正式地说,对于从类 i i i 中采样得到的 n i n_i ni个样本,我们建议增加一个加权因子 ( 1 − β ) / ( 1 − β n i ) (1−β)/(1−β^{n_i}) (1−β)/(1−βni)到损失函数中,其中超参数 β ∈ ( 0 , 1 ) β∈(0,1) β∈(0,1)(加权因子即为 1 / E n i 1/E_{n_i} 1/Eni)。所以类平衡 (CB)损失可以写成: C B ( p , y ) = 1 E n y L ( p , y ) = 1 − β 1 − β n y L ( p , y ) (6) CB(\mathbf p,y)=\frac1{E_{n_y}}\mathcal L(\mathbf p,y)=\frac{1-\beta}{1-\beta^{n_y}}\mathcal L(\mathbf p,y)\tag6 CB(p,y)=Eny1L(p,y)=1−βny1−βL(p,y)(6)
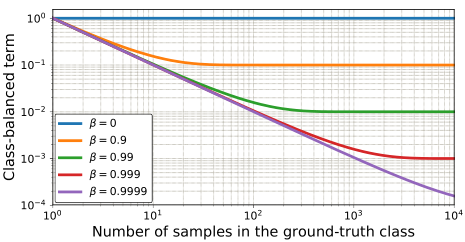
图3. 可视化的类平衡因子(1-β)/(1-βny)其中, ny 是真实类的样本数。两条轴都是对数尺度。对于一个长尾数据集,多数类的样本数明显多于少数类,设置 β 可以适当地重新平衡各类的相对损失,并减少按类别频率重新加权的急剧不平衡。
其中 n y n_y ny表示在真实类 y y y中的样本数量。从图 3 可见,我们把类平衡损失看作不同 β β β的 n y n_y ny函数。注意, β = 0 β= 0 β=0对应无重新加权 和 β → 1 β→1 β→1对应使用类频率的倒数 进行重新加权。
提出的有效样本数的新概念使我们能够使用一个超参数 β β β ,在 不重新加权 和 按类频率的倒数 重新加权之间平稳地调整类平衡项。
提出的类平衡项 ( 1 − β ) / ( 1 − β n y ) (1−β)/(1−β^{n_y}) (1−β)/(1−βny)与模型和损失无关的, 在某种意义上,与损失函数 L \mathcal L L和预测得到的类概率 p \mathbf p p是相对独立的。为了证明该类平衡损失项是通用的,我们将展示如何应用该类平衡损失项到三个常用的损失函数:softmax cross-entropy loss, sigmoid cross-entropy loss和focal loss中。
4.1 Class-Balanced Softmax Cross-Entropy Loss
假设模型的输出为 z = [ z 1 , z 2 … , z C ] \mathbf z=[z_1,z_2…,z_C] z=[z1,z2…,zC],这里 C C C表示类别数;softmax函数认为每个类相互排斥,并在所有类上计算概率分布为 p i = e x p ( z i ) ∑ j = 1 C e x p ( z j ) p_i=\frac{exp(z_i)}{\sum_{j=1}^Cexp(z_j)} pi=∑j=1Cexp(zj)exp(zi),其中 ∀ i ∈ 1 , 2 , . . . , C ∀i∈{1,2,...,C} ∀i∈1,2,...,C。假设一个样本的标签为 y y y,样本的softmax cross-entropy(CE)损失为:
C E s o f t m a x ( z , y ) = − l o g ( e x p ( z y ) ∑ j = 1 C e x p ( z j ) ) (7) CE_{softmax}(\mathbf z,y)=-log(\frac {exp(z_y)}{\sum_{j=1}^Cexp(z_j)})\tag7 CEsoftmax(z,y)=−log(∑j=1Cexp(zj)exp(zy))(7)
假设类 y y y有 n y n_y ny个训练样本,则类平衡(CB)softmax cross-entropy损失为:
C B s o f t m a x ( z , y ) = − 1 − β 1 − β n y l o g ( e x p ( z y ) ∑ j = 1 C e x p ( z j ) ) CB_{softmax}(\mathbf z,y)=-\frac{1-\beta}{1-\beta^{n_y}}log(\frac {exp(z_y)}{\sum_{j=1}^Cexp(z_j)}) CBsoftmax(z,y)=−1−βny1−βlog(∑j=1Cexp(zj)exp(zy))
4.2 Class-Balanced Sigmoid Cross-Entropy Loss
与softmax不同的是,sigmoid函数计算的类概率是假设每个类独立的,而不是互斥的。在使用sigmoid函数时,我们将多类视觉识别看作是多个二进制分类任务,其中网络的每个输出节点执行一个vs所有的分类来预测目标类相对于其他类的概率。与softmax相比,sigmoid对于真实世界的数据集可能有两个优点:(1)sigmoid不假定类之间的互斥性,这与真实世界的数据很好地一致,其中一些类可能彼此非常相似,特别是在大量细粒度类的情况下。(2)由于每个类都被认为是独立的,并且有自己的预测器,所以sigmoid将单标签分类与多标签预测相结合。这是一个很好的属性,因为真实世界的数据通常有多个语义标签。
为简单起见,我们使用与softmax cross-entropy相同的符号,将 z i t z^t_i zit定义为:
z i t = { z i if i=y − z i otherwise (9) z^t_i=\begin{cases} z_i& \text{if i=y}\\-z_i& \text{otherwise} \end{cases}\tag9 zit={
zi−ziif i=yotherwise(9)
则sigmoid cross-entropy (CE)损失被写成:
C E s i g m o i d ( z , y ) = − ∑ i = 1 C l o g ( s i g m o i d ( z i t ) ) = − ∑ i = 1 C l o g ( 1 1 + e x p ( − z i t ) ) (10) CE_{sigmoid}(\mathbf z,y)=-\sum^C_{i=1}log(sigmoid(z^t_i))=-\sum^C_{i=1}log(\frac 1{1+exp(-z^t_i)})\tag{10} CEsigmoid(z,y)=−i=1∑Clog(sigmoid(zit))=−i=1∑Clog(1+exp(−zit)1)(10)
那么类平衡(CB)的sigmoid cross-entropy 损失为:
C B s i g m o i d ( z , y ) = − 1 − β 1 − β n y ∑ i = 1 C l o g ( 1 1 + e x p ( − z i t ) ) (11) CB_{sigmoid}(\mathbf z,y)=-\frac{1-\beta}{1-\beta^{n_y}}\sum^C_{i=1}log(\frac 1{1+exp(-z^t_i)})\tag{11} CBsigmoid(z,y)=−1−βny1−βi=1∑Clog(1+exp(−zit)1)(11)
4.3 Class-Balanced Focal Loss
最近提出的focal loss(FL)[26]在sigmoid cross-entropy损失的基础上增加了一个调制因子,以减少分类良好的样本的相对损失,并将重点放在困难样本上。 p i t = s i g m o i d ( z i t ) = 1 1 + e x p ( − z i t ) p^t_i=sigmoid(z^t_i)=\frac1{1+exp(-z_i^t)} pit=sigmoid(zit)=1+exp(−zit)1,对应focal loss可以写为:
F L ( z , y ) = − ∑ i = 1 C ( 1 − p i t ) γ l o g ( p i t ) (12) FL(\mathbf z,y)=-\sum^C_{i=1}(1-p_i^t)^\gamma log(p^t_i)\tag{12} FL(z,y)=−i=1∑C(1−pit)γlog(pit)(12)
类平衡(CB)的focal loss为:
C B F L ( z , y ) = − 1 − β 1 − β n y ∑ i = 1 C ( 1 − p i t ) γ l o g ( p i t ) (13) CB_{FL}(\mathbf z,y)=-\frac{1-\beta}{1-\beta^{n_y}}\sum^C_{i=1}(1-p_i^t)^\gamma log(p^t_i)\tag{13} CBFL(z,y)=−1−βny1−βi=1∑C(1−pit)γlog(pit)(13)
最初的focal loss是α-balanced变体。类平衡的focal loss是一样是α-balanced损失,其中 α t = ( 1 − β ) / ( 1 − β n y ) α_t =(1−β)/(1−β^{n_y}) αt=(1−β)/(1−βny)。因此,类平衡项可以被看作一种明确的方式,根据有效样本数量的来设置focal loss中的 α t α_t αt。
(其实上面三个损失的CB版本就是在原来的式子中增加了一个特定的权重weight)
5. Experiment
所提出的类平衡损失在人工创建的长尾CIFAR[25]数据集上进行了评估,该数据集具有可滚动的数据不平衡程度,以及真实世界的长尾数据集iNaturalist 2017[41]和2018[1]。为了证明我们的损失对于视觉识别是通用的,我们还提出了ImageNet数据(ILSVRC 2012[34])上的实验。我们使用不同深度的深度残差网络(ResNet)[16],并从头开始训练所有网络。
5.1 Datasets
Long-Tailed CIFAR为了分析所提出的类平衡损失,CIFAR[25]的长尾版本是通过根据指数函数 n = n i μ i n = n_i μ^i n=niμi减少每个类的训练样本数量来创建的,其中i为类索引(0-index), n i n_i ni为原始训练图像数, µ ∈ ( 0 , 1 ) µ∈(0,1) µ∈(0,1)。测试集不变。我们将数据集的不平衡因子定义为最大类中的训练样本数除以最小类。图4显示了长尾CIFAR-100上每类训练图像的数量,不平衡因子范围为10到200。我们对长尾CIFAR-10和CIFAR-100进行了实验.
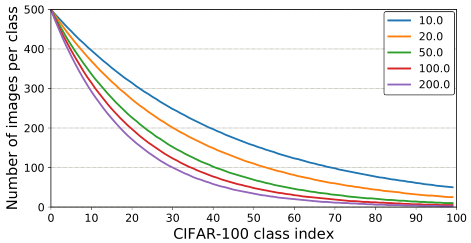
图4. 人为制造的长尾CIFAR-100数据集,不同的不平衡因子下每个类训练样本数。
iNaturalist。最近推出的iNaturalist物种分类和检测数据集[41]是一个真实世界的长尾数据集,在其2017年版本中包含来自5089个类别的579184张训练图像,在其2018年版本中包含来自8142个类别的437513张训练图像[1]。我们在实验中使用官方的训练和验证分割。
ImageNet我们使用ILSVRC 2012[34]版本,包含1,281,167张训练图像和50,000张验证图像。
表1 总结了我们实验中使用的所有数据集以及它们的不平衡系数。
表1. 我们创建了5个长尾版本的CIFAR-10和CIFAR-100的数据集,不平衡系数分别为10、20、50、100和200。

5.2 Implementation
基于sigmoid损失的训练。传统的深度网络训练方案将最后一个线性分类层初始化为偏差 b = 0 b=0 b=0。正如Lin等人[27]所指出的,当使用sigmoid函数获得类概率时,这可能导致训练的不稳定。这是因为在最后一层使用 b = 0 b=0 b=0的sigmoid函数会在训练开始时引起巨大的损失,因为每个类别的输出概率接近于0.5。因此,对于使用sigmoid交叉熵损失和焦点损失的训练,我们假设每个类的先验是 π = 1 / C π = 1/C π=1/C,其中 C C C是类的数量,并初始化最后一层的偏差为 b = − l o g ( ( 1 − π ) / π ) b =−log((1−π) /π) b=−log((1−π)/π)。此外,我们去除最后一层偏差 b b b的ℓ2正则化(权值衰减)。
我们使用Tensorflow[2]来实现和训练所有的模型,采用随机梯度下降的动量。我们训练了32层残差网络(ResNet-32)来进行CIFAR的所有实验。与Zagoruyko[47]类似,我们在CIFAR上训练ResNets时注意到一个干扰效应,即在学习率下降后,损失和验证误差都逐渐上升,特别是在数据高度不平衡的情况下。我们发现,将学习率衰减设置为0.01而不是0.1可以解决这个问题。CIFAR上的模型在单个NVIDIA Titan X GPU上以批次大小为128的方式训练200个epoch。初始学习率设置为0.1,然后在160个周期衰减0.01,在180个周期再次衰减0.01。我们还在前5个epoch中使用了学习率[13]的线性预热。在iNaturalist和ILSVRC 2012数据上,我们遵循Goyal等[13]使用的相同训练策略,在单个Cloud TPU上训练批量大小为1024的残差网络。由于焦点损失的尺度小于softmax和sigmoid交叉熵损失,在用焦点损失进行训练时,我们在ILSVRC 2012和iNaturalist上分别使用了2倍和4倍的学习率。
5.3 Visual Recognition on Long-Tailed CIFAR
我们对具有各种不平衡因素的CIFAR长尾数据集进行了广泛的研究。表2 显示了ResNet-32在测试集上的分类错误率表现。我们给出了使用Softmax交叉熵损失,Sigmoid交叉熵损失,不同 γ γ γ的焦点损失,以及通过交叉验证选择的最佳超参数的类平衡损失的结果。
表2. 在长尾CIFAR-10和CIFAR-100上用不同损失函数训练的ResNet-32的分类错误率。我们显示了通过交叉验证选择的最佳超参数(SM代表Softmax,SGM代表Sigmoid)的类平衡损失的最佳结果。类平衡损失能够实现显著的性能提升。∗表示当每个类有相同数量的样本时,类平衡项总是1,因此它还原为原始损失函数。
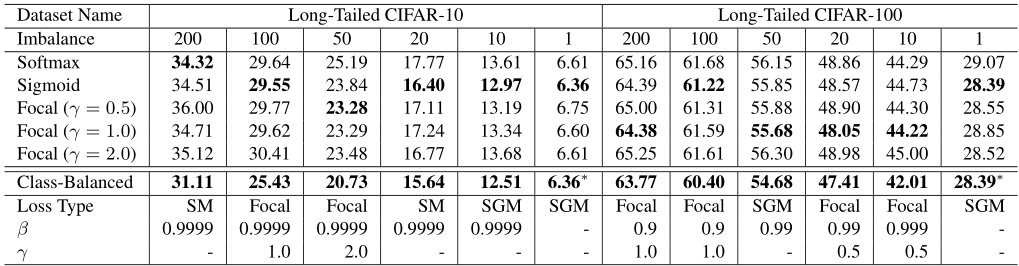
损失类型的超参数搜索空间为{softmax, sigmoid, focal}, β ∈ { 0.9 , 0.99 , 0.999 , 0.9999 } β∈\{0.9,0.99,0.999,0.9999\} β∈{ 0.9,0.99,0.999,0.9999}(第4节),焦点损失[27]的超参数搜索空间为 γ ∈ { 0.5 , 1.0 , 2.0 } γ∈\{0.5,1.0,2.0\} γ∈{ 0.5,1.0,2.0}。
从表2的结果中,我们观察到以下结果:(1)通过适当选择超参数,类平衡损失能够显著提高常用损失函数在长尾数据集上的性能。(2)在视觉识别任务中,大量使用Softmax交叉熵作为损失函数。无论如何,按照5.2节的训练策略,sigmoid交叉熵和焦点损失在大多数情况下都能优于softmax交叉熵。(3) CIFAR-10的最佳 β β β值一致为0.9999。但在CIFAR-100上,不同不平衡因子的数据集往往具有不同且较小的最优 β β β。
为了更好地理解 β β β和类平衡损失的作用,我们以不平衡因子为50的长尾数据集为例,在图5中展示了在使用和不使用类平衡项训练时模型的错误率。有趣的是,对于CIFAR-10,类平衡项总是能改善原始损失的性能, β β β越大,性能增益越大。
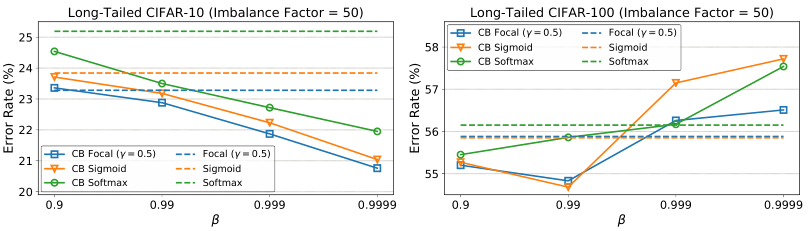
图5. 训练时,有和没有类平衡项的分类错误率。在CIFAR-10上,类别平衡损失在不同的β上产生一致的改善,β越大,改善越大。在CIFAR-100上,β = 0.99或β = 0.999改善了原有的损失,而较大的β则会损害性能。
然而,在CIFAR-100上,只有较小的 β β β值可以提高性能,而较大的值会降低性能。图6给出了不同 β β β条件下的有效样本数。在CIFAR-10上,以 β = 0.9999 β = 0.9999 β=0.9999重新加权时,有效样本数接近样本数。这意味着CIFAR-10的最佳重加权策略与按类别频率重加权相似。在CIFAR-100上,使用较大 β β β的性能较差,表明类频倒数重加权不是明智的选择。相反,我们需要使用一个更小的 β β β,它在类之间具有更平滑的权重。
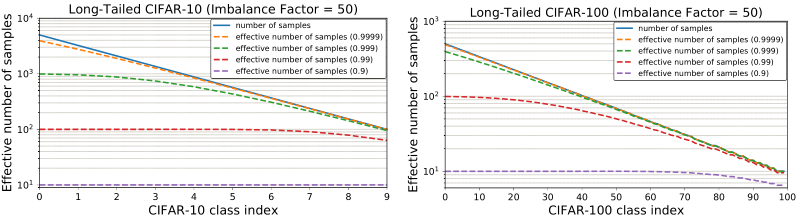
图6. 长尾CIFAR-10和CIFAR-100上具有不同β的有效样本数,不平衡为50。这是一个以对数尺度为纵轴的半对数图。当β→1时,有效样本数与样本数相等。当β值较小时,各类别的有效样本数基本相同。
这是合理的,因为 β = ( N − 1 ) / N β = (N−1)/N β=(N−1)/N,所以越大的 β β β意味着越大的 N N N。如第3节所述, N N N可以解释为唯一原型的数量。细粒度数据集的 N N N应该小于粗粒度数据集。例如,一个特定鸟类物种的独特原型的数量应该小于一个通用鸟类类的独特原型的数量。由于CIFAR-100中的类比CIFAR-10更细粒度,因此CIFAR100的N应该比CIFAR-10更小。这解释了我们对 β β β效应的观察。
5.4 Visual Recognition on Large-Scale Datasets
为了证明所提出的类平衡损失可以用于大规模的真实世界数据集,我们展示了在iNaturalist 2017, iNaturalist 2018和ILSVRC 2012上训练不同深度的ResNets的结果。
表3总结了所有数据集验证集的top-1和top-5错误率。我们使用类平衡焦点损失,因为它具有更大的灵活性,并且发现 β = 0.999 β = 0.999 β=0.999和 γ = 0.5 γ = 0.5 γ=0.5在所有数据集上都能产生相当好的性能。
表3. 用不同损失函数训练的大规模数据集分类错误率。所提出的类平衡项结合焦点损失(CB focal)能够在很大程度上优于softmax交叉熵。
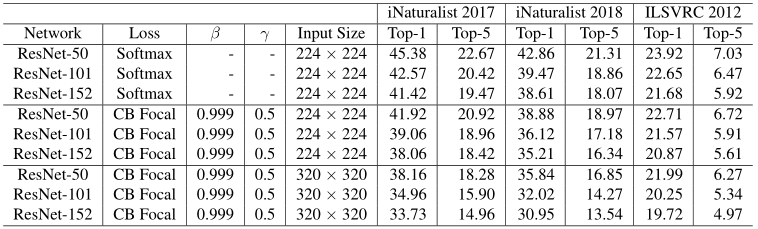
从结果中我们可以看到,我们能够在ILSVRC 2012上胜过常用的软最大交叉熵损失,并且在iNaturalist上有很大的优势。值得注意的是,当使用类平衡焦点损失取代softmax交叉熵损失时,ResNet-50能够获得与iNaturalist上的ResNet152和ILSVRC 2012上的ResNet-101相当的性能。ILSVRC 2012和iNaturalist 2018的训练曲线如图7所示。类平衡平衡焦点损失在训练60次后开始显现优势。
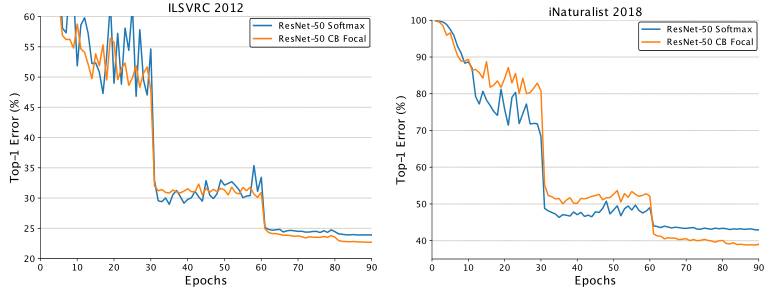
图7. 在ILSVRC 2012(左)和iNaturalist 2018(右)上的ResNet-50训练曲线。60 epoch后β = 0.999, γ = 0.5的类平衡焦点损失优于softmax交叉熵损失。
6. Conclusion and discussion
在这项工作中,我们提出了一个理论上合理的框架来解决训练数据的长尾分布问题。其关键思想是考虑到数据的过度,以帮助量化有效样本的数量。在这个框架下,我们进一步提出了一个类平衡损失,将损失与个类的有效样本数的倒数重新加权。我们对人工诱导的长尾CIFAR数据集进行了广泛的研究,以了解和分析提出的损失。在CIFAR和包括iNaturalist和ImageNet在内的大规模数据集上的实验已经验证了类平衡损失的好处。
我们提出的框架提供了一个量化数据重叠的非参数手段,因为我们不对数据分布做任何假设。这使得我们的损失普遍适用于广泛的现有模型和损失函数。直观地说,如果我们知道数据的分布,就可以获得对有效样本数的更好估计。在未来,我们计划通过加入对数据分布的合理假设或设计基于学习的自适应方法来扩展我们的框架工作。
总结
1. 概述
现实中经常存在训练样本长尾分布的现象,目前常用的方法包括重采样(re-sampling)以及基于样本数量的加权(re-weighting)。但是,我们发现当样本数达到一定量的时候,通过增加新样本带来的收益会消失。
-
本文提出了一种新的理论框架,通过将每一个样例和一个小的邻域而不是单独的样本点关联,来衡量数据是否存在重叠。将样本的有效数据量定义为样本的体积,可以通过一个简单的公式进行计算。
-
本文设计了一种基于每种类别有效样本数的加权策略,来重新平衡损失,得到类别平衡的损失函数。
2. 计算有效样本数
-
随机覆盖的数据采样方法
给定一个类别,定义这个类特征空间的所有可能的数据集合为 S S S。假设 S S S的体积为 N N N并且 N ≥ 1 N\ge1 N≥1。定义每一个数据都是 S S S的子集并且体积都是单位体积 1 1 1,每个数据都有可能和其他数据重叠。考虑随机覆盖数据采样的过程,每个数据(也就是子集)都有可能被采样,最终目的是能够覆盖集合的全部可能。采样的数据越多,对集合 S S S的覆盖越好。采样数据的期望体积会随机数据量的增加而增加,最终的边界是 N N N。 -
定义1:样本的
有效数据量是样本的期望体积(expected volume)。
为了保证这个问题是可解的,我们假设一个新的采样数据只能通过两种方式和之前采样的数据进行交互:
(1)新样本存在于之前采样数据中的可能性为 p p p;
(2)新样本在之前采样数据之外的可能性为 1 − p 1-p 1−p。
随着采样数据点的增多, p p p值会越来越大。对于一个类别来说,期望体积 N N N可以看做不同原型的数量。 -
定义有效样本数为 E n E_n En,其中 n n n表示样本的总数。
显然,当样本总数只有 1 1 1个时, E 1 = 1 E_1= 1 E1=1;现在假设之前采样了个 n − 1 n-1 n−1样例,接着采样第个 n n n样例,已采样数据的期望体积设为 E n − 1 E_{n-1} En−1,那么新采样数据有 p = E n − 1 N p=\frac{E_{n-1}}N p=NEn−1的概率和之前的样例重叠,所以经过第 n n n次采样之后,期望体积 E n E_n En为: E n = p E n − 1 + ( 1 − p ) ( E n − 1 + 1 ) = 1 + N − 1 N E n − 1 E_n = pE_{n-1}+(1-p)(E_{n-1}+1)=1+\frac{N-1}NE_{n-1} En=pEn−1+(1−p)(En−1+1)=1+NN−1En−1
现在假设 E n − 1 = 1 − β n − 1 1 − β E_{n-1} = \frac{1-\beta^{n-1}}{1-\beta} En−1=1−β1−βn−1,那么: E n = 1 + β 1 − β n − 1 1 − β = 1 − β n 1 − β E_n=1+\beta\frac{1-\beta^{n-1}}{1-\beta}=\frac{1-\beta^n}{1-\beta} En=1+β1−β1−βn−1=1−β1−βn
上式表明样例的有效数据量是总数 n n n的指数函数,超参数 β ∈ [ 0 , 1 ) \beta \in[0,1) β∈[0,1)控制随着的增长速度。 -
通过 E n E_n En的渐近性质可以发现:
当 N N N很大时,有效数据量的大小等于样本数,这表明没有数据时重叠的,所以的样例都是唯一的。
当 N = 1 N=1 N=1时,则表明所有的数据都只有一个原型,其他数据都是从该原型经过数据增强得到的。
3. 类别平衡损失函数
-
类别平衡损失用来处理不平衡数据集的问题,方法主要是通过
引入一个加权因子,这个因子则和有效样本数成反比。 -
假设输入样例 x x x的标签为 y ∈ { 1 , 2 … , C } y\in \{1,2…,C\} y∈{ 1,2…,C},这里 C C C表示类别总数。假设模型得到的概率分布为 p = { p 1 , p 2 … p C } \mathbf p=\{p_1,p_2…p_C\} p={ p1,p2…pC},其中 p i ∈ [ 0 , 1 ) p_i \in[0,1) pi∈[0,1)。定义损失函数为 L ( p , y ) \mathcal L(\mathbf p,y) L(p,y),假设类别的样例数为 n i n_i ni,根据上一节的公式可知对于类别 i i i有 E n i = 1 − β i n i 1 − β i E_{n_i} = \frac{1-\beta^{n_i}_i}{1-\beta_i} Eni=1−βi1−βini,这里 β i = N i − 1 N i \beta_i=\frac{N_i-1}{N_i} βi=NiNi−1。
通常来说,如果没有更多关于数据的信息,那么对每个类别来说很难找到合适的超参 N i N_i Ni。所以,通常假设 N i N_i Ni是独立的,并且对于每个类别都有 N i = N ; β = N − 1 N N_i = N ; \beta = \frac{N-1}{N} Ni=N;β=NN−1。 -
为了平衡损失,引入权重因子 α i \alpha_i αi,它和每个类的有效样本数成反比;为了保证总损失和之前大致一致,需要对权重因子归一化,得到 ∑ i = 1 C α i = C \sum^C_{i=1}\alpha_i=C ∑i=1Cαi=C。为了简化,接下来使用 1 E n i \frac1{E_{n_i}} Eni1表示归一化的权重因子。
-
对于一个类别为 i i i的样例(对应的数量为 n i n_i ni),在损失函数前加上权重因子 1 − β i 1 − β i n i \frac{1-\beta_i}{1-\beta^{n_i}_i} 1−βini1−βi,其中 β ∈ [ 0 , 1 ) \beta \in[0,1) β∈[0,1),那么类别平衡损失可以表示为: C B ( p , y ) = 1 E n i L ( p , y ) = 1 − β i 1 − β i n i L ( p , y ) CB(\mathbf p,y)=\frac1{E_{n_i}}\mathcal L(\mathbf p,y)=\frac{1-\beta_i}{1-\beta^{n_i}_i}\mathcal L(\mathbf p,y) CB(p,y)=Eni1L(p,y)=1−βini1−βiL(p,y)其中, n y n_y ny表示训练集中类别为 y y y的数量。
4. 如何将平衡项用于3种常见的损失函数
4.1 Softmax Cross-Entropy
假设模型的输出为 z = [ z 1 , z 2 … , z C ] \mathbf z=[z_1,z_2…,z_C] z=[z1,z2…,zC],这里 C C C表示类别数;显然,模型输出要经过softmax得到属于每个类别的概率,即 p i = e x p ( z i ) ∑ j = 1 C e x p ( z j ) p_i=\frac{exp(z_i)}{\sum_{j=1}^Cexp(z_j)} pi=∑j=1Cexp(zj)exp(zi)。假设一个样本的标签为 y y y,样本的softmax cross-entropy(CE)损失为:
C E s o f t m a x ( z , y ) = − l o g ( e x p ( z y ) ∑ j = 1 C e x p ( z j ) ) (7) CE_{softmax}(\mathbf z,y)=-log(\frac {exp(z_y)}{\sum_{j=1}^Cexp(z_j)})\tag7 CEsoftmax(z,y)=−log(∑j=1Cexp(zj)exp(zy))(7)
设类 y y y有 n y n_y ny个训练样本,经过类别平衡后的损失为:
C B s o f t m a x ( z , y ) = − 1 − β 1 − β n y l o g ( e x p ( z y ) ∑ j = 1 C e x p ( z j ) ) CB_{softmax}(\mathbf z,y)=-\frac{1-\beta}{1-\beta^{n_y}}log(\frac {exp(z_y)}{\sum_{j=1}^Cexp(z_j)}) CBsoftmax(z,y)=−1−βny1−βlog(∑j=1Cexp(zj)exp(zy))
4.2 Sigmoid Cross-Entropy
使用sigmoid函数的多分类假设不同类别之间是互相独立的,其实就是一种OvA的分类思想,转化为多个二分类问题;对于每一个类别,都是预测属于这个类和不属于这个类的概率。这种损失函数的两个优势:
(1)Sigmoid函数不具有排他性,而在现实世界中,一些类可能和另外的类非常相似,尤其在一些类别数比较多的细粒度分类场景下。
(2)由于每个类别被认为是独立的,都有自己的概率值,非常适用于多标签预测的场景。
使用和上面相同的标记,定义 z i t z^t_i zit为: z i t = { z i if i=y − z i otherwise z^t_i=\begin{cases} z_i& \text{if i=y}\\-z_i& \text{otherwise} \end{cases} zit={
zi−ziif i=yotherwise
则sigmoid cross-entropy (CE)损失被写成:
C E s i g m o i d ( z , y ) = − ∑ i = 1 C l o g ( s i g m o i d ( z i t ) ) = − ∑ i = 1 C l o g ( 1 1 + e x p ( − z i t ) ) (10) CE_{sigmoid}(\mathbf z,y)=-\sum^C_{i=1}log(sigmoid(z^t_i))=-\sum^C_{i=1}log(\frac 1{1+exp(-z^t_i)})\tag{10} CEsigmoid(z,y)=−i=1∑Clog(sigmoid(zit))=−i=1∑Clog(1+exp(−zit)1)(10)
类别平衡的sigmoid cross-entropy: C B s i g m o i d ( z , y ) = − 1 − β 1 − β n y ∑ i = 1 C l o g ( 1 1 + e x p ( − z j ) ) CB_{sigmoid}(\mathbf z,y)=-\frac{1-\beta}{1-\beta^{n_y}}\sum^C_{i=1}log(\frac 1{1+exp(-z_j)}) CBsigmoid(z,y)=−1−βny1−βi=1∑Clog(1+exp(−zj)1)
4.3 Class-Balanced Focal Loss
FL通过添加一个修正因子来降低已经比较好进行分类的样例的损失,关注比较难分类的样例。假设, p i t = s i g m o i d ( z i t ) = 1 1 + e x p ( − z i t ) p^t_i=sigmoid(z^t_i)=\frac1{1+exp(-z_i^t)} pit=sigmoid(zit)=1+exp(−zit)1对应的损失可以写为: F L ( z , y ) = − ∑ i = 1 C ( 1 − p i t ) γ l o g ( p i t ) FL(\mathbf z,y)=-\sum^C_{i=1}(1-p_i^t)^\gamma log(p^t_i) FL(z,y)=−i=1∑C(1−pit)γlog(pit)
类别平衡后的损失为: C B F L ( z , y ) = − 1 − β 1 − β n y ∑ i = 1 C ( 1 − p i t ) γ l o g ( p i t ) CB_{FL}(\mathbf z,y)=-\frac{1-\beta}{1-\beta^{n_y}}\sum^C_{i=1}(1-p_i^t)^\gamma log(p^t_i) CBFL(z,y)=−1−βny1−βi=1∑C(1−pit)γlog(pit)
其实原始的Focal Loss存在 α \alpha α平衡系数,而这里的类别平衡系数则取代了 α \alpha α的功能。
- 参数的选择
(1)Focal Loss中的 γ \gamma γ一般可以在[0.5, 1.0, 2.0]之间进行选择,具体视情况而定;类别平衡系数的超参 β \beta β可用的参数通常为[0.999, 0.99, 0.9]等,值越大,表示有效样本数越接近样本总数。
5. 总结
利用有效样本数的概念,可以解决数据重合的问题。由于我们没有对数据集本身做任何假设,因此重新加权项通常适用于多个数据集和多个损失函数。因此,类不平衡的问题可以用一个更合适的结构来解决,这一点很重要,因为现实世界中的大多数数据集都存在大量的数据不平衡。
论文
总结
启发
- 提出了有效样本数=样本体积的概念
- 通过有效样本数提出了为对应的损失函数类平衡权重因子(有效样本的倒数)。
问题
- 见5.2 Implementation-基于sigmoid损失的训练。线性分类层初始化为偏差 b = 0 b=0 b=0。为什么使用sigmoid函数获得类概率时,可能导致训练的不稳定。
在最后一层使用 b = 0 b=0 b=0的sigmoid函数会在训练开始时引起巨大的损失,因为每个类别的输出概率接近于0.5。
??是因为使用sigmoid会导致梯度下降吗??