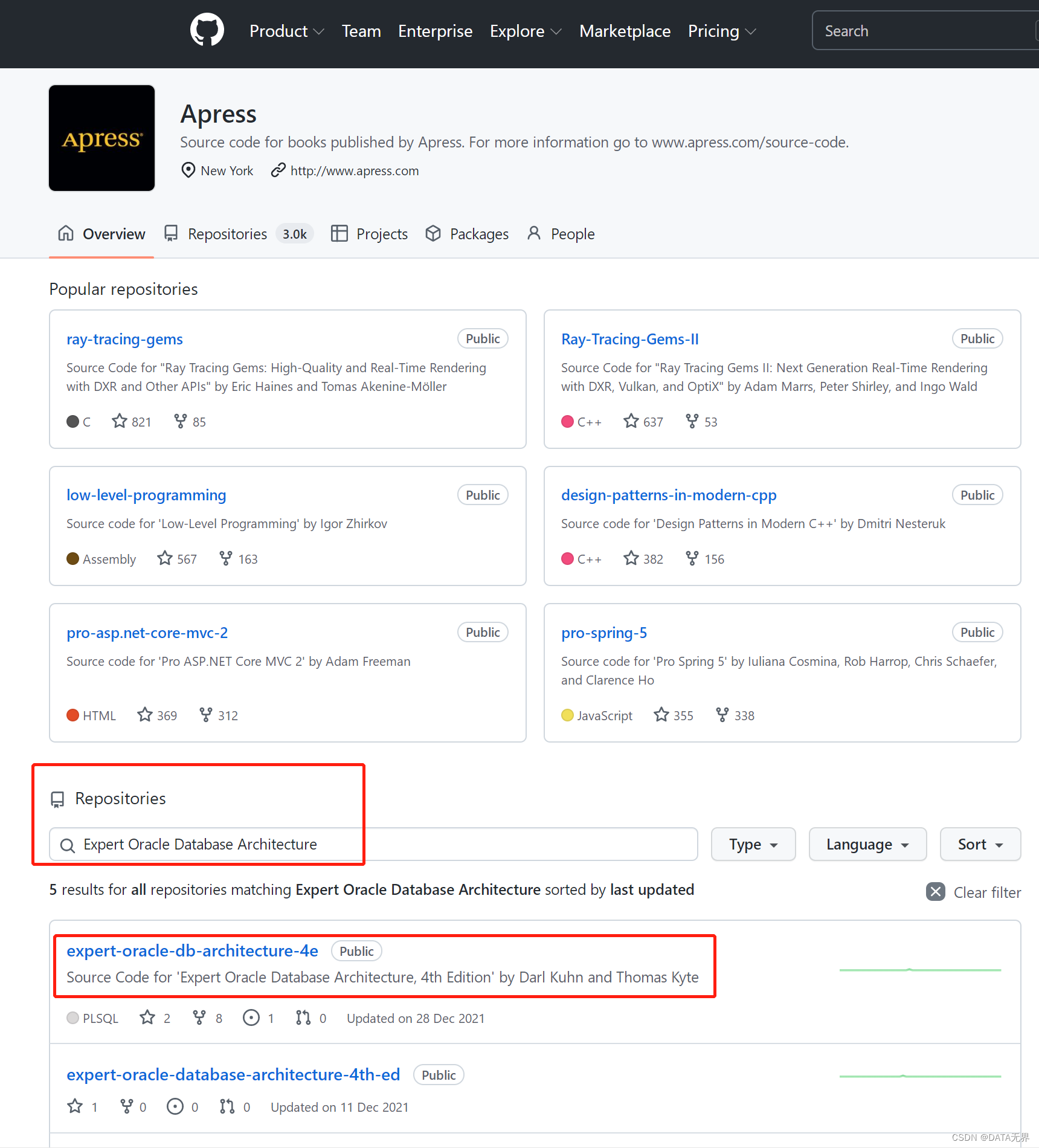

-- If you're using a container database, connect to your PDB and schema when running this.
-- If you're not using a container database, then just connect to your schema.
define numrows=10000000
drop table big_table purge;
create table big_table
as
select rownum id, OWNER, OBJECT_NAME, SUBOBJECT_NAME, OBJECT_ID,
DATA_OBJECT_ID, OBJECT_TYPE, CREATED, LAST_DDL_TIME, TIMESTAMP,
STATUS, TEMPORARY, GENERATED, SECONDARY, NAMESPACE, EDITION_NAME
from all_objects
where 1=0
/
alter table big_table nologging;
declare
l_cnt number;
l_rows number := &numrows;
begin
insert /*+ append */
into big_table
select rownum id, OWNER, OBJECT_NAME, SUBOBJECT_NAME, OBJECT_ID,
DATA_OBJECT_ID, OBJECT_TYPE, CREATED, LAST_DDL_TIME, TIMESTAMP,
STATUS, TEMPORARY, GENERATED, SECONDARY, NAMESPACE, EDITION_NAME
from all_objects
where rownum <= &numrows;
--
l_cnt := sql%rowcount;
commit;
while (l_cnt < l_rows)
loop
insert /*+ APPEND */ into big_table
select rownum+l_cnt,OWNER, OBJECT_NAME, SUBOBJECT_NAME, OBJECT_ID,
DATA_OBJECT_ID, OBJECT_TYPE, CREATED, LAST_DDL_TIME, TIMESTAMP,
STATUS, TEMPORARY, GENERATED, SECONDARY, NAMESPACE, EDITION_NAME
from big_table a
where rownum <= l_rows-l_cnt;
l_cnt := l_cnt + sql%rowcount;
commit;
end loop;
end;
/
alter table big_table add constraint
big_table_pk primary key(id);
exec dbms_stats.gather_table_stats( user, 'BIG_TABLE', estimate_percent=> 1);
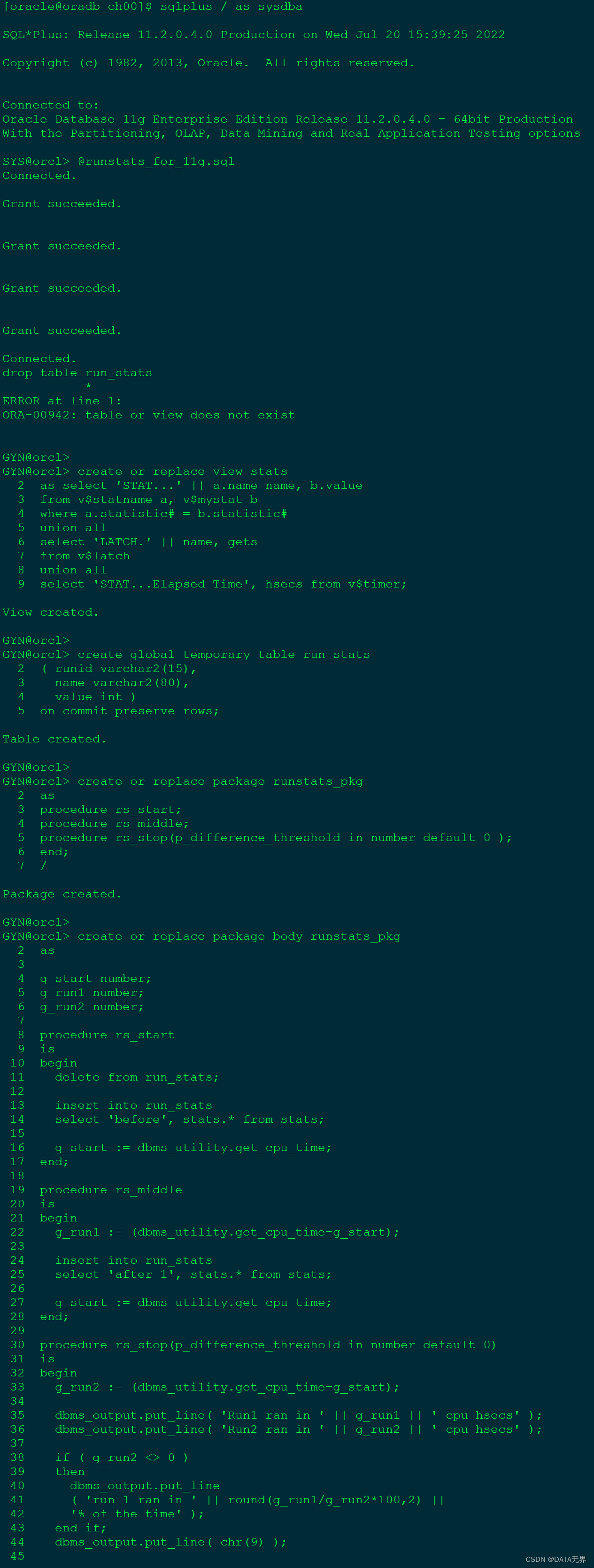
2、创建runstats
-
墙上时钟(wall clock) 或耗用时间(elapsed time)
-
系统统计结果,会并排地显示每个方法做某件事(如执行一个解析调用)的次数,并展示出二者之差
-
闩定(latch)这个是报告的关键输出
-- Script name: runstats.sql
-- Define the PDB you want to connect to in your database.
-- If you're using a non-container database, then leave the PDB variable blank.
-- But you really should be using a container database going forward.
-- define PDB=PDB1
connect / as sysdba
-- alter session set container=&&PDB;
grant select on v_$statname to gyn;
grant select on v_$mystat to gyn;
grant select on v_$latch to gyn;
grant select on v_$timer to gyn;
-- conn gyn/gyn@&&PDB
conn gyn/gyn
drop table run_stats;
set echo on;
create or replace view stats
as select 'STAT...' || a.name name, b.value
from v$statname a, v$mystat b
where a.statistic# = b.statistic#
union all
select 'LATCH.' || name, gets
from v$latch
union all
select 'STAT...Elapsed Time', hsecs from v$timer;
create global temporary table run_stats
( runid varchar2(15),
name varchar2(80),
value int )
on commit preserve rows;
create or replace package runstats_pkg
as
procedure rs_start;
procedure rs_middle;
procedure rs_stop(p_difference_threshold in number default 0 );
end;
/
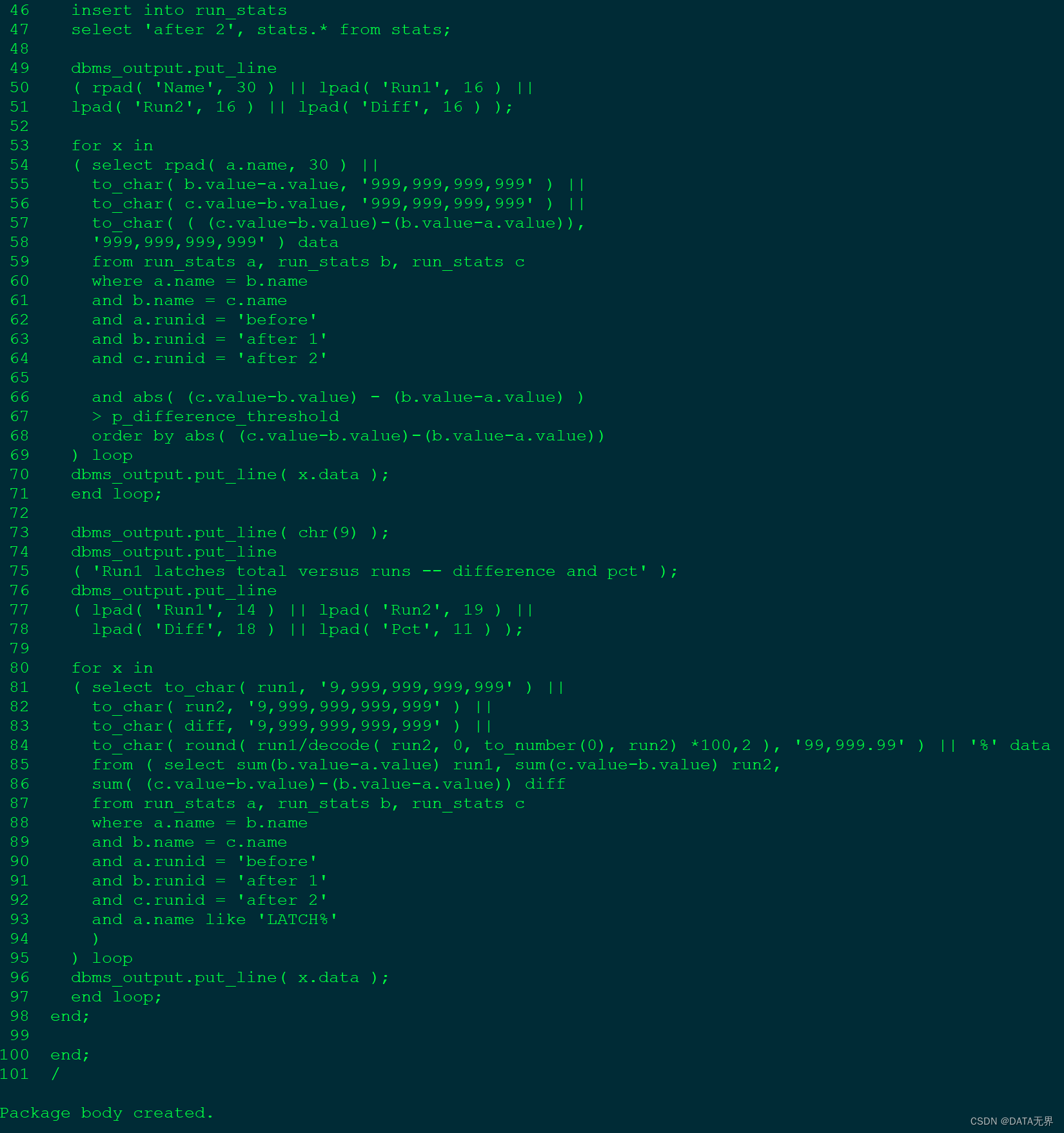
create or replace package body runstats_pkg
as
g_start number;
g_run1 number;
g_run2 number;
procedure rs_start
is
begin
delete from run_stats;
insert into run_stats
select 'before', stats.* from stats;
g_start := dbms_utility.get_cpu_time;
end;
procedure rs_middle
is
begin
g_run1 := (dbms_utility.get_cpu_time-g_start);
insert into run_stats
select 'after 1', stats.* from stats;
g_start := dbms_utility.get_cpu_time;
end;
procedure rs_stop(p_difference_threshold in number default 0)
is
begin
g_run2 := (dbms_utility.get_cpu_time-g_start);
dbms_output.put_line( 'Run1 ran in ' || g_run1 || ' cpu hsecs' );
dbms_output.put_line( 'Run2 ran in ' || g_run2 || ' cpu hsecs' );
if ( g_run2 <> 0 )
then
dbms_output.put_line
( 'run 1 ran in ' || round(g_run1/g_run2*100,2) ||
'% of the time' );
end if;
dbms_output.put_line( chr(9) );
insert into run_stats
select 'after 2', stats.* from stats;
dbms_output.put_line
( rpad( 'Name', 30 ) || lpad( 'Run1', 16 ) ||
lpad( 'Run2', 16 ) || lpad( 'Diff', 16 ) );
for x in
( select rpad( a.name, 30 ) ||
to_char( b.value-a.value, '999,999,999,999' ) ||
to_char( c.value-b.value, '999,999,999,999' ) ||
to_char( ( (c.value-b.value)-(b.value-a.value)),
'999,999,999,999' ) data
from run_stats a, run_stats b, run_stats c
where a.name = b.name
and b.name = c.name
and a.runid = 'before'
and b.runid = 'after 1'
and c.runid = 'after 2'
and abs( (c.value-b.value) - (b.value-a.value) )
> p_difference_threshold
order by abs( (c.value-b.value)-(b.value-a.value))
) loop
dbms_output.put_line( x.data );
end loop;
dbms_output.put_line( chr(9) );
dbms_output.put_line
( 'Run1 latches total versus runs -- difference and pct' );
dbms_output.put_line
( lpad( 'Run1', 14 ) || lpad( 'Run2', 19 ) ||
lpad( 'Diff', 18 ) || lpad( 'Pct', 11 ) );
for x in
( select to_char( run1, '9,999,999,999,999' ) ||
to_char( run2, '9,999,999,999,999' ) ||
to_char( diff, '9,999,999,999,999' ) ||
to_char( round( run1/decode( run2, 0, to_number(0), run2) *100,2 ), '99,999.99' ) || '%' data
from ( select sum(b.value-a.value) run1, sum(c.value-b.value) run2,
sum( (c.value-b.value)-(b.value-a.value)) diff
from run_stats a, run_stats b, run_stats c
where a.name = b.name
and b.name = c.name
and a.runid = 'before'
and b.runid = 'after 1'
and c.runid = 'after 2'
and a.name like 'LATCH%'
)
) loop
dbms_output.put_line( x.data );
end loop;
end;
end;
/
使用runstats.sql
-- Runstats example
define PDB=PDB1
conn eoda/foo@&&PDB
drop table t1 purge;
drop table t2 purge;
create table t1
as
select * from big_table
where 1=0;
create table t2
as
select * from big_table
where 1=0;
exec runstats_pkg.rs_start;
insert into t1
select *
from big_table
where rownum <= 1000000;
commit;
exec runstats_pkg.rs_middle;
begin
for x in ( select *
from big_table
where rownum <= 1000000 )
loop
insert into t2 values X;
end loop;
commit;
end;
/
set serverout on;
exec runstats_pkg.rs_stop(1000000)
最后得到的结果如下:
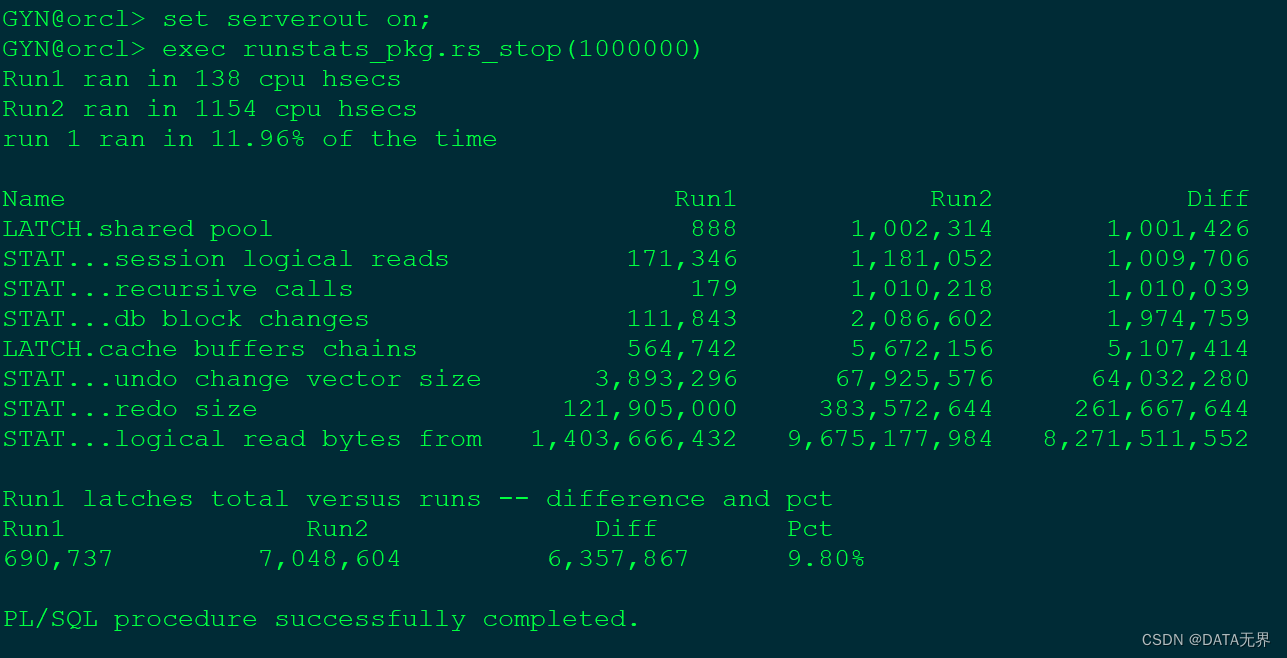
3、mystat
set echo off
set verify off
column value new_val V
define S="&1"
set autotrace off
select a.name, b.value
from v$statname a, v$mystat b
where a.statistic# = b.statistic#
and lower(a.name) = lower('&S')
/
set echo on
Mystat2.sql 用于报告差值(通过运行第一个脚本mystat.sql来填充&V,为此它使用了SQL*PLUS NEW_VAL特性,其中包含由上一个查询选择的最后一个value)
set echo off
set verify off
select a.name, b.value V, to_char(b.value-&V,'999,999,999,999') diff
from v$statname a, v$mystat b
where a.statistic# = b.statistic#
and lower(a.name) = lower('&S')
/
set echo on-- Mystat example
define PDB=PDB1
conn eoda/foo@&&PDB
column name form a30
@mystat "redo size"
update big_table set owner = lower(owner) where rownum <= 1000;
commit;
@mystat2运行结果

create or replace procedure show_space
( p_segname in varchar2,
p_owner in varchar2 default user,
p_type in varchar2 default 'TABLE',
p_partition in varchar2 default NULL )
-- this procedure uses authid current user so it can query DBA_*
-- views using privileges from a ROLE and so it can be installed
-- once per database, instead of once per user that wants to use it
authid current_user
as
l_free_blks number;
l_total_blocks number;
l_total_bytes number;
l_unused_blocks number;
l_unused_bytes number;
l_LastUsedExtFileId number;
l_LastUsedExtBlockId number;
l_LAST_USED_BLOCK number;
l_segment_space_mgmt varchar2(255);
l_unformatted_blocks number;
l_unformatted_bytes number;
l_fs1_blocks number; l_fs1_bytes number;
l_fs2_blocks number; l_fs2_bytes number;
l_fs3_blocks number; l_fs3_bytes number;
l_fs4_blocks number; l_fs4_bytes number;
l_full_blocks number; l_full_bytes number;
-- inline procedure to print out numbers nicely formatted
-- with a simple label
procedure p( p_label in varchar2, p_num in number )
is
begin
dbms_output.put_line( rpad(p_label,40,'.') ||
to_char(p_num,'999,999,999,999') );
end;
begin
-- this query is executed dynamically in order to allow this procedure
-- to be created by a user who has access to DBA_SEGMENTS/TABLESPACES
-- via a role as is customary.
-- NOTE: at runtime, the invoker MUST have access to these two
-- views!
-- this query determines if the object is an ASSM object or not
begin
execute immediate
'select ts.segment_space_management
from dba_segments seg, dba_tablespaces ts
where seg.segment_name = :p_segname
and (:p_partition is null or
seg.partition_name = :p_partition)
and seg.owner = :p_owner
and seg.tablespace_name = ts.tablespace_name'
into l_segment_space_mgmt
using p_segname, p_partition, p_partition, p_owner;
exception
when too_many_rows then
dbms_output.put_line
( 'This must be a partitioned table, use p_partition => ');
return;
end;
-- if the object is in an ASSM tablespace, we must use this API
-- call to get space information, else we use the FREE_BLOCKS
-- API for the user managed segments
if l_segment_space_mgmt = 'AUTO'
then
dbms_space.space_usage
( p_owner, p_segname, p_type, l_unformatted_blocks,
l_unformatted_bytes, l_fs1_blocks, l_fs1_bytes,
l_fs2_blocks, l_fs2_bytes, l_fs3_blocks, l_fs3_bytes,
l_fs4_blocks, l_fs4_bytes, l_full_blocks, l_full_bytes, p_partition);
p( 'Unformatted Blocks ', l_unformatted_blocks );
p( 'FS1 Blocks (0-25) ', l_fs1_blocks );
p( 'FS2 Blocks (25-50) ', l_fs2_blocks );
p( 'FS3 Blocks (50-75) ', l_fs3_blocks );
p( 'FS4 Blocks (75-100)', l_fs4_blocks );
p( 'Full Blocks ', l_full_blocks );
else
dbms_space.free_blocks(
segment_owner => p_owner,
segment_name => p_segname,
segment_type => p_type,
freelist_group_id => 0,
free_blks => l_free_blks);
p( 'Free Blocks', l_free_blks );
end if;
-- and then the unused space API call to get the rest of the
-- information
dbms_space.unused_space
( segment_owner => p_owner,
segment_name => p_segname,
segment_type => p_type,
partition_name => p_partition,
total_blocks => l_total_blocks,
total_bytes => l_total_bytes,
unused_blocks => l_unused_blocks,
unused_bytes => l_unused_bytes,
LAST_USED_EXTENT_FILE_ID => l_LastUsedExtFileId,
LAST_USED_EXTENT_BLOCK_ID => l_LastUsedExtBlockId,
LAST_USED_BLOCK => l_LAST_USED_BLOCK );
p( 'Total Blocks', l_total_blocks );
p( 'Total Bytes', l_total_bytes );
p( 'Total MBytes', trunc(l_total_bytes/1024/1024) );
p( 'Unused Blocks', l_unused_blocks );
p( 'Unused Bytes', l_unused_bytes );
p( 'Last Used Ext FileId', l_LastUsedExtFileId );
p( 'Last Used Ext BlockId', l_LastUsedExtBlockId );
p( 'Last Used Block', l_LAST_USED_BLOCK );
end;
/运行创建脚本;

存储过程接口如下:

P_SEGNAME 段名(例如,表或者索引名)
P_OWNER 默认为当前用户,不过也可以使用这个例程查看另外某个模式
P_TYPE 默认为TABLE,表示查看哪种类型的对象(段)
P_PARTITION 显示分区对象的空间时所用的分区名。
SHOW_SPACE 一次只显示一个分区的空间利用率。
使用方法:
exec show_space('BIG_TABLE');运行结果如下:
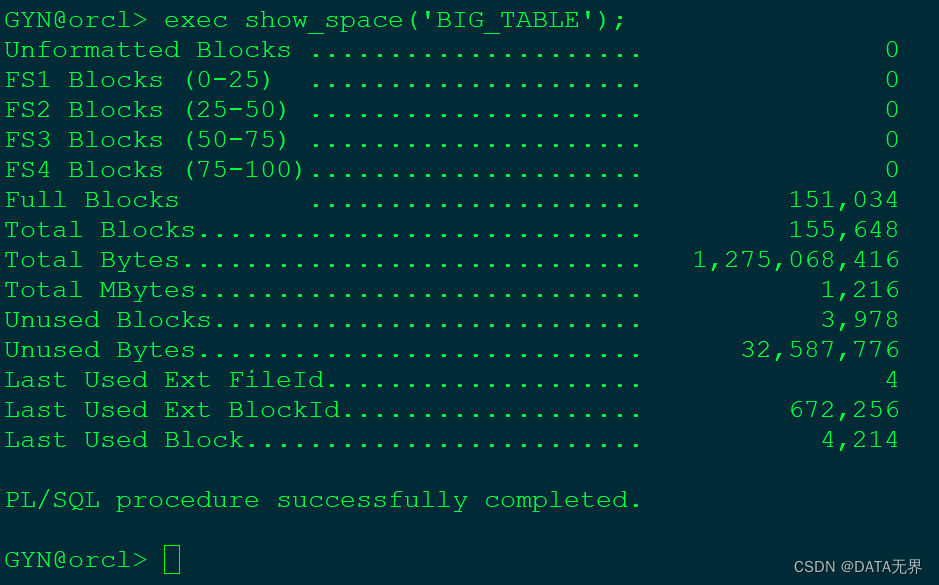
--报告中的各项结果解读如下:
Unformatted Blocks:为表分配的位于高水位线之下但是未用的块数。把未格式化和已格式化但是未使用的块加一起。就是已为表分配但从未用于保存的ASSM对象数据的总块。
FS1 Blocks~FS4 Blocks:包含数据的已格式化块。项名后的数字表示各块的“空闲度‘,例如(0~25)是指空闲度为0~25%的块数。
Full Blocks:已满的块数,不能再向这些块插入数据,新插入的数据将不会写到这些块上。
Total Blocks、Total Bytes、Total MBytes:为所查看的段分配的总空间量。单位分别是数据库块(Blocks),字节(Bytes),兆字节(MB)。
Unused Blocks、Unused Bytes:表示未用空间所占的比例。这些块已经分配给所查看的段。但目前位于高水位线之上。
Last Used Ext FileId:包含最后一个块(其中包含数据)的文件的文件ID。
Last Used Ext BlockId:最后一个区段开始处的块ID,这是最后使用的文件中的块的ID.也就是Last Used Ext FileId ID号中的块ID。
Last Used Block:最后区段中,最后一个块的偏移量。
END.