一、问题
笔者最近使用PCL中的ICP时候遇到了一个问题,可以看下面这张图。

我先解释一下其中各幅图的含义,其中黑色的是目标点云,是对3D模型采样获得的(模型与实际物体一致);红色的是使用3D相机拍摄物体获得的源点云;绿色的是配准之后的结果。
ICP很容易陷入局部最优解,为获得良好的结果,需要设置比较好的初值。第一行三幅图从不同角度展示了源点云和目标点云的初始关系,重叠度较高,初值良好。第二行展示了相同形态但不同存储格式的目标点云和源点云在相同参数与初始位姿下的配准结果,从左到右依次是:1.PCD与PCD,2.PCD与PLY,3.PLY与PCD,4.PLY与PLY。
很怪,直接给我整不会了,重复了很多次实验都是这样,源点云就是会往一个什么都没有的区域去配准。我想着看看这两种存储格式到底有什么不同之处,为什么会有如此奇怪的现象。
二、PCD与PLY简介
支持点云的文件格式有很多:
- PCD:PCL库的特有格式,专为存储点云数据而设计。
- PLY:一种多边形文件格式,由 Turk 等人在斯坦福大学开发。
- STL :3D Systems 创建的立体光刻 CAD 软件原生的文件格式
- OBJ : 一种几何定义文件格式,最初由 Wavefront Technologies 开发
- X3D : 用于表示 3D 计算机图形数据的基于 XML 的 ISO 标准文件格式
- 等等
这些文件格式因为不同目的再不同时间被创建,因此都存在各自的问题,需要根据应用场景选择不同格式。
一般都有binary和ascii两种格式,前者读取速度更快,但是无法用文本编辑器查看其中内容,打开后会是乱码。
2.1 PCD格式
这部分参考官方
2.1.1 对于PCL为什么要采用新的格式:
The PCD file format is not meant to reinvent the wheel, but rather to complement existing file formats that for one reason or another did not/do not support some of the extensions that PCL brings to n-D point cloud processing.
这里的n-D说的是特征描述子,因为熟悉点云处理的人知道,一个点的特征描述子有很多维度。
2.1.2 格式
-
header (存储为ascii格式,顺序必须指定如下!!!)
VERSION:PCL中的官方版本应该是0.7FIELDS:指定点可以具有的字段(维度)SIZE:指定每个字段的大小(字节)TYPE:指定每个字段的类型(I/U/F)COUNT:指定每个字段可以有多少个元素,对于xyz就是有一个元素,但对于VFH的特征描述符有308个WIDTH:对于无序点云等于总点数HEIGHT:对于无序点云等于1VIEWPOINT:平移(tx ty tz)+四元数(qw qx qy qz),默认为0 0 0 1 0 0 0POINTS:总点数DATA:点云数据的类型(ASCII/BINARY/BINARY_COMPRESSED)
-
point list: 对于ascii格式,接下来就是存储每个点的数据,每个点占一个新行。
2.1.3 例子
# .PCD v.7 - Point Cloud Data file format
VERSION .7
FIELDS x y z rgb
SIZE 4 4 4 4
TYPE F F F F
COUNT 1 1 1 1
WIDTH 213
HEIGHT 1
VIEWPOINT 0 0 0 1 0 0 0
POINTS 213
DATA ascii
0.93773 0.33763 0 4.2108e+06
0.90805 0.35641 0 4.2108e+06
0.81915 0.32 0 4.2108e+06
0.97192 0.278 0 4.2108e+06
0.944 0.29474 0 4.2108e+06
0.98111 0.24247 0 4.2108e+06
0.93655 0.26143 0 4.2108e+06
0.91631 0.27442 0 4.2108e+06
0.81921 0.29315 0 4.2108e+06
0.90701 0.24109 0 4.2108e+06
...
可能你会问为什么RGB字段只有一个值?
R/G/B的范围是0~255,通常会用一个浮点数来存储,最低的八位存储蓝色分量,往前八位是绿色分量,再往前是红色分量,最高的八位用来存储透明度(alpha通道)。
2.2 PLY格式
- header:
因为PLY描述的东西更多,不像PCD一样专门描述点云,所以在头部还会对所描述的element进行说明(vertex/face/edge/camera),然后紧随其后的是一个列表,用来说明element中的属性类型和名称
ply
format ascii 1.0 { ascii/binary, format version number }
comment made by Greg Turk { comments keyword specified, like all lines }
comment this file is a cube
element vertex 8 { define "vertex" element, 8 of them in file }
property float x { vertex contains float "x" coordinate }
property float y { y coordinate is also a vertex property }
property float z { z coordinate, too }
element face 6 { there are 6 "face" elements in the file }
property list uchar int vertex_index { "vertex_indices" is a list of ints }
end_header { delimits the end of the header }
0 0 0 { start of vertex list }
0 0 1
0 1 1
0 1 0
1 0 0
1 0 1
1 1 1
1 1 0
4 0 1 2 3 { start of face list }
4 7 6 5 4
4 0 4 5 1
4 1 5 6 2
4 2 6 7 3
4 3 7 4 0
这个示例文件就描述了一个立方体,face list中第一个数字4代表这个面由多少个顶点组成,后面的序号代表vertex list中点的索引。
三、结论
掉了一周头发也没想明白为什么会配准到那个奇怪的位置。结果!!!!!!一次调试时突然发现,在pcl_visualizer中位于同一位置的点云(一个是PLY一个是PCD),他们点云数据居然是不一样的。。。。。。
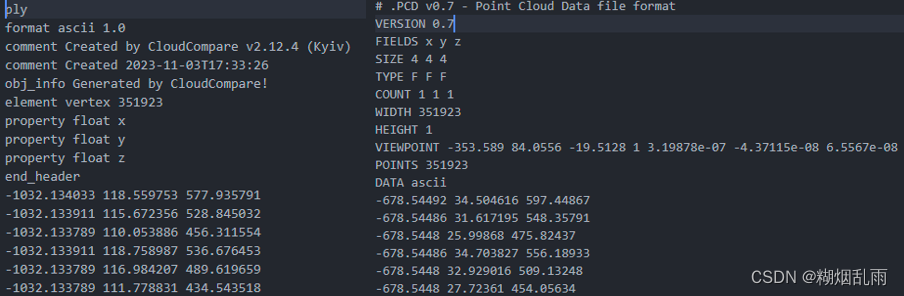
我使用了CloudCompare中的配准功能测试了相同的数据,是可以成功完成配准的,所以问题应该出在对于pcd文件的解析上面。
- 这样看来,如果一个PCD文件他的
VIEWPOINT字段不是默认值0001000,那么这份点云其实是相对于相机坐标系下的。 - PCL读取点云文件时不会直接将相机坐标系下的点转换到世界坐标系下,视点坐标是额外被存储的;而CloudCompare会进行这个转换。
- PCL可视化的时候,坐标系又被重新统一,因此两份点云看起来是一致的。
- 这份数据是怎么保存出来的?在我的记忆中这份数据是从CloudCompare中对一个STL模型采样获得,但我刚才重复了一下这个操作发现保存出来的PCD的视点字段是默认值,等我之后复现出来再补充。
结论: 所以问题并不是处在了PCD和PLY这两种格式上,而是我对于存储的内容不清楚,没有搞清坐标系。因此也给大家提个醒,保存出来的文件得大概瞄一下内容,看看是否符合自己的预期。