01 概述
在前面的文章介绍了环境感知中不同雷达的作用,一个标准的自动驾驶解决方案需要雷达与视觉技术的配合使用。视觉技术其实是仿生理学的解决方案,因为现实世界中司机驾驶车辆就是依靠视觉去做行车过程中的决策。
在本文会介绍下车载摄像头的基础知识以及视觉算法的基本原理,另外还会对自动驾驶视觉技术的几大经典场景做一个介绍。
02 车载摄像头介绍
从硬件成本分析,车载摄像头是技术相对成熟而成本最低的的一种方案。使用车载摄像头的缺点主要是后续数据的分析,需要依赖大量的标注数据和模型训练资源去训练成熟的用于自动驾驶的各种机器学习相关模型。
常见的车载摄像头功能如下表所示:
| 辅助驾驶功能 | 使用的摄像头类型 | 功能简介 |
| 车道偏离预警(LDW) | 前视 | 车道线检测,当车行驶偏离的时候报警 |
| 前向碰撞预警(FCW) | 前视 | 当车与前车过近时,会预警 |
| 交通标识识别(TSR) | 前视、侧视 | 识别当前道路两侧的标识 |
| 车道保持辅助(LKA) | 前视 | 车偏离轨道,会自动纠正方向 |
| 行人碰撞预警(PCW) | 前视 | 当摄像头识别出行人的时候,需要预警 |
| 盲点监视(BSD) | 侧视 | 利用侧视摄像头找到盲区影像,显示在驾驶舱屏幕 |
| 全景泊车(SVP) | 前视、后视、侧视 | 利用车辆前后摄像头获取的影像和图像拼接技术,输出车辆周边的全景图 |
| 泊车辅助(PA) | 后视 | 泊车时。显示倒车轨迹,方便驾驶员泊车 |
| 驾驶员注意力监测 | 内置 | 检测驾驶员闭眼等行为 |
(1)单目摄像头VS双目摄像头
常见的摄像头分为单目和双目两种摄像头,未来的自动驾驶技术将大概率以单目摄像头为主。
单目摄像头工作流程同样遵循图像输入、预处理、特征提取、特征分类、匹配、完成识别几个步骤,其测距原理是先匹配识别后估算距离:通过图像匹配识别出目标类别,随后根据图像大小估算距离。

单目摄像头的内容分析可以通过经典的深度学习算法实现。
双目摄像头测距原理与人眼类似,通过对图像视差进行计算,直接对前方景物进行距离测量;从视差的大小倒推出物体的距离,视差越大,距离越近;
双目测距步骤:相机标定 —— 双目校正 —— 双目匹配 —— 计算深度信息(测距)。
(2)摄像头的标定
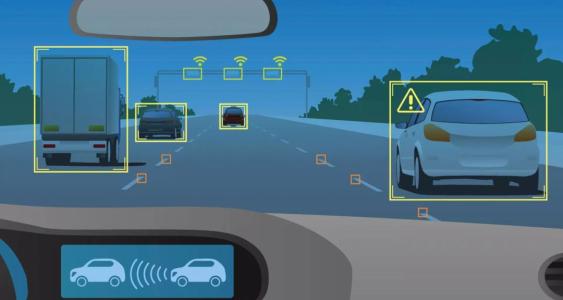
与雷达相似,摄像头也需要做标定,需要把世界坐标系、摄像头坐标系、摄像头内的图像坐标和像素坐标做统一标定,这样识别出来的内容才可以正确的应用到自动驾驶流程中。
因为摄像头拍摄的图像是二维的,而真实世界是三维的,需要通过算法将二维空间的信息转换为三维。类似于下图这种方案:
03 视觉算法基本原理
既然摄像头识别对象是依赖深度学习算法,那么视觉相关算法的基本原理也需要大致介绍下。目前各种车载自动驾驶摄像头里面用的图像识别类算法基本上都是CNN的结构,就是卷积神经网络。
卷积神经网络在认知图像的过程其实跟人大脑认知图像的原理类似。大脑识别图像的过程其实是将图片在人脑的各级神经元抽象成各种小的元素,比如棱角、直线等等,然后将这些元素所在的神经突触激活,最终信息传导下去形成认知。卷积神经网络模仿了这种图像识别的流程,通过卷积的各层将图像全部细节元素识别出来,形成最终的认知。

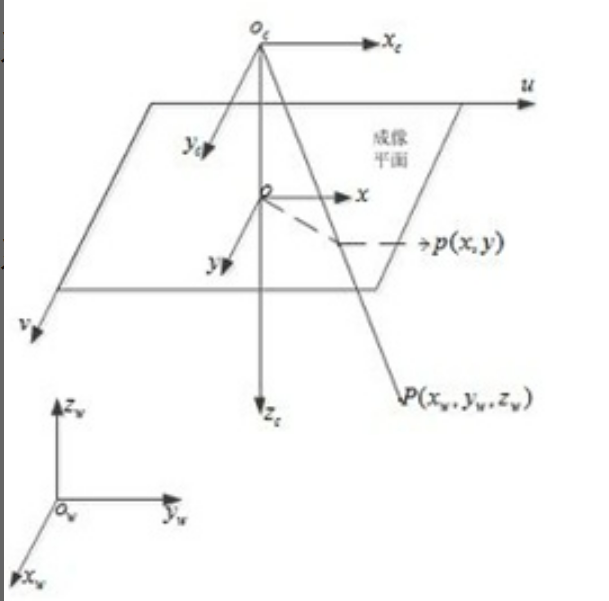
一个标准的CNN的网络结构如图所示:
是由很多的层组成的,有卷积层、池化层、全连接层组成。每一层对应很多小的feature maps,feature maps有宽度和高度,可以对应到图像的宽和高。
在卷积神经网络中各个层都有不同的功能。
(1)卷积层
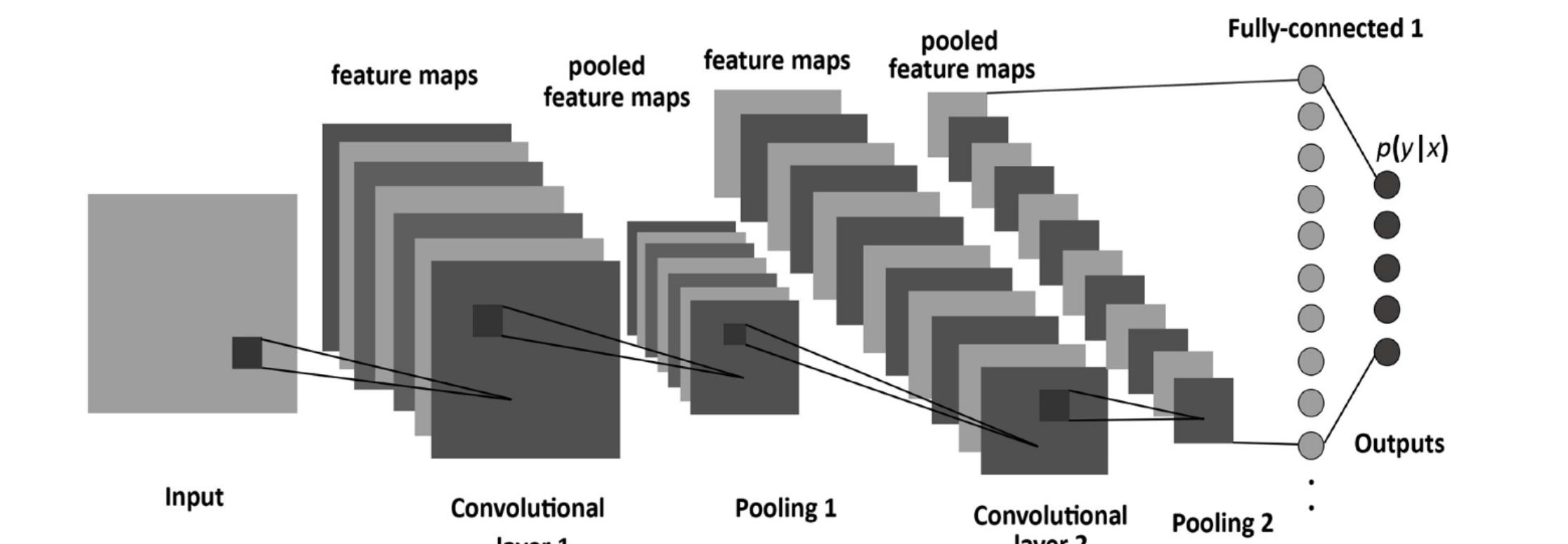
卷积层是CNN中的核心层,卷积层核心是一个滤波器。比如原始图像的像素是32*32,那么卷积层可以做一个5*5的滤波器,去扫描整个图像,抽取出各个原子部分的信息。
假设5*5的卷积滤波的深度是3,那么一个卷积核就包含了5*5*3=75个权重值,这些个卷积的权重值就是模型训练过程中要学习的。
(2)池化层
接下来介绍下池化层,如果没有池化层,一个5*5深度是3的卷积核,就要有75个参数,整个卷积神经网络由无数个卷积核组成,那么总的模型参数会爆炸。
在卷积层之间补充池化层的作用是减少参数的个数,另外也是减少整体训练过程中的计算量。池化的方案有很多,比如在max-pooling中可以只挑选每个2*2的小方格中最大的cell值。

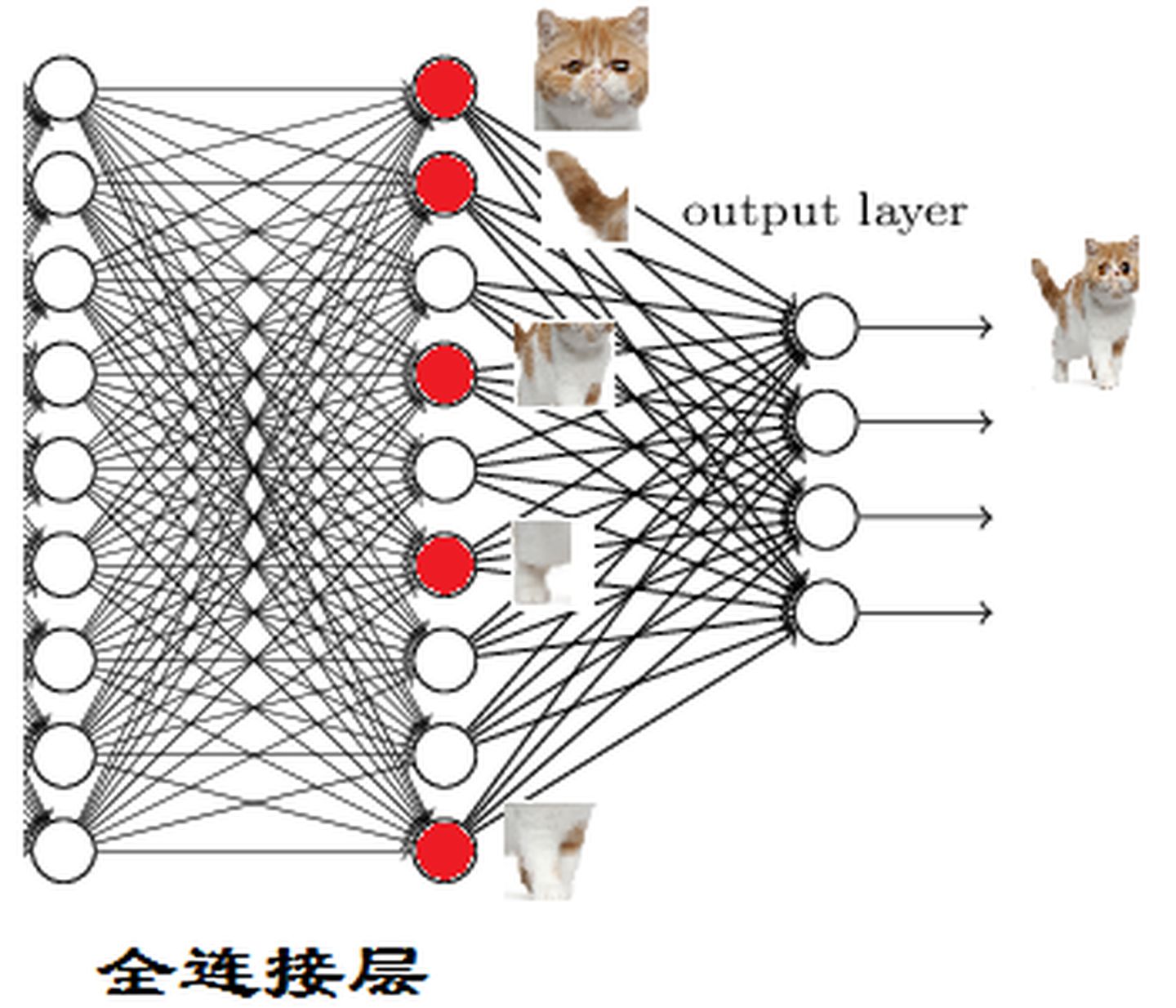
(3)全连接层
全连接层的主要作用就是分类,假设知道具备猫的眼睛、尾巴这些元素就能识别出猫。
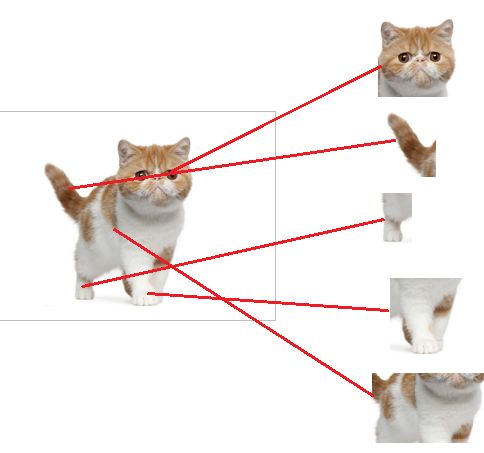
全连接层一般作为整个神经网络的最后一层,将关键要素激活,最终帮助网络判断出最终的结果。
04 视觉技术的基本场景
目前视觉技术在自动驾驶领域的识别主要分以下几个核心场景,分别是雷达云图的识别、行驶途中障碍物的识别、行驶区域的识别、交通标识的识别以及光流识别。
(1)雷达云图识别
上一篇文章介绍过,激光雷达会通过雷达波将行驶过程中道路信息的云图绘制出来。

图像识别技术可以基于这种云图找出道路轨迹、车辆等信息,从而做驾驶决策。
(2)障碍物识别
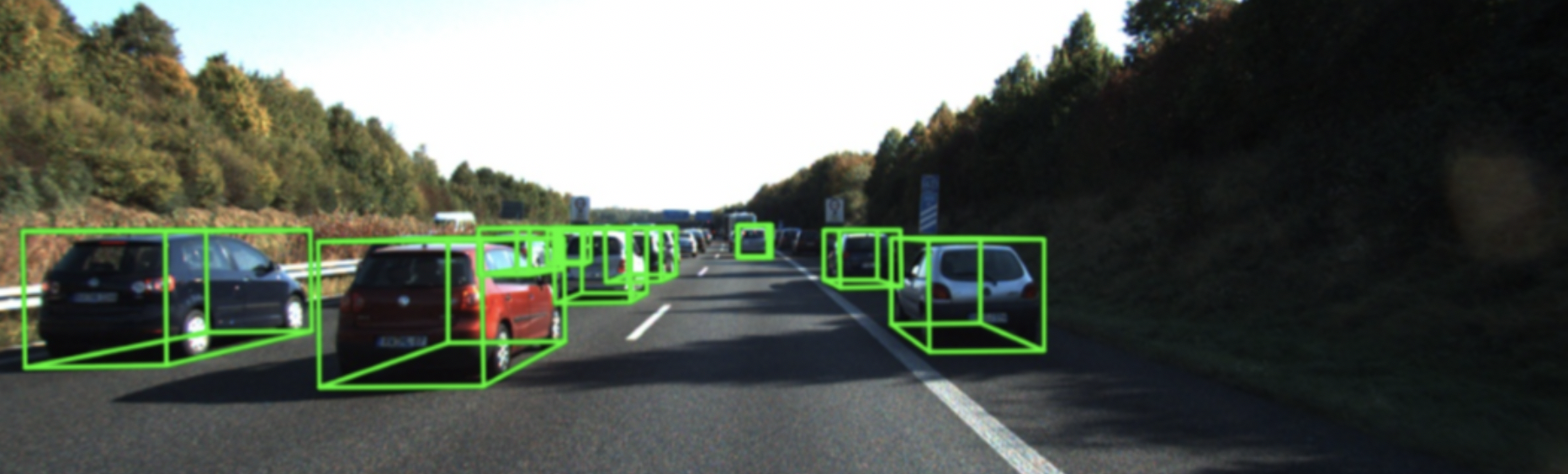
通过摄像头捕获实时视频流,然后通过CNN模型可以实时对视频流图像进行识别,然后指导驾驶决策。
(3)行驶区域识别
形势区域识别主要解决的问题是对车道线进行识别,并且标记出继续前行的方向。

(4)交通牌识别
如果说车道线识别和障碍物识别还可以通过雷达做补强,那么交通牌识别是只有视觉技术配合摄像头可以解决的问题。自动驾驶过程中需要配合摄像头找到每个标识牌的内容,比如限速、红绿灯识别、禁行标识等。

交通牌识别的技术问题是交通标识物通常并不出现在视频的主要方位,一般只在视频的边缘位置占据很小的一块区域,所以要通过特殊的图像分割技术解决。
(5)光流识别
光流指的是图像中每个像素点的二维瞬时速度,通常来讲就是图像中每个像素点在图中的移动速度。通过光流识别可以清楚的判断道路中的人、车辆的行驶速度。
光流是可以通过图像可视化的,如下图:

左边是输入的移动的图像,右边是转化为光流的表视图,可以通过不同的颜色标识不同的运动方向,通过深浅标识局部的速度。
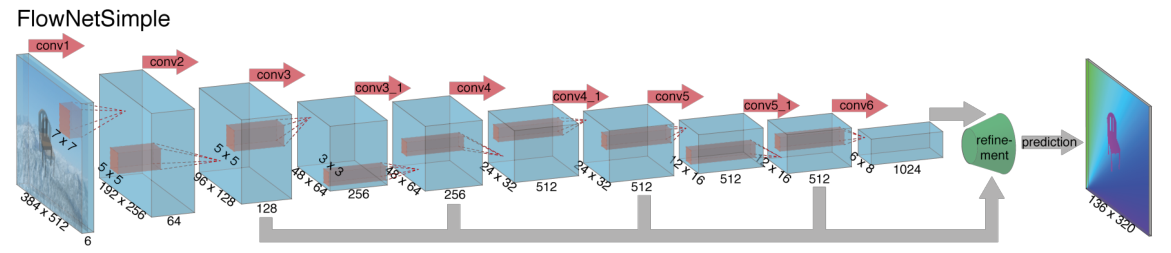
基于光流场景有专业的FlowNet网络,也是一种基于卷积神经网络的变种。