目录
一、决策树
决策树(Decision Tree)是一种常见的机器学习算法,它是在已知各种情况发生概率的基础上求取净现值的期望值大于等于零的概率,以进行决策分析的方法。由于这种决策分支画成图形很像一棵树的枝干,故称决策树。决策树是一种基于if-then-else规则的监督学习算法(即利用标记好的样本来训练,可以预测新的样本)。
决策树由一个根节点,以及若干个内部节点和叶结点组成,内部节点就是通过条件判断而进行分支选择的节点,而叶节点没有子节点,表示最终的决策结果。决策树的深度表示所有节点的最大层次数,即从根节点出发走到叶节点的最大步长。

以西瓜书中的经典样例为例,我们希望从标注好的训练样本中学习得到一个决策树模型,以对新的西瓜进行判断:good or bad,好瓜还是坏瓜。决策树模型具有极强的可解释性,因为它符合人的推理和决策过程。例如,给你一个西瓜样本,首先来看看它的色泽,如果是青绿色,再看看其根蒂形态,如果是蜷缩的,那么再来听听它敲起来的声音,如果是浊响的,那么我们可以得到结论:这是个好瓜。
西瓜的色泽、根蒂、敲声这些都是可以用于决策判断的特征(或属性)。在决策树进行预测时,在树的内部节点处选取某一特征进行判断,然后根据判断结果决定走到哪个子节点,就这样直到抵达叶节点,即得到分类结果。 决策树的这些规则通过训练得到的。
决策树学习的基本流程遵循“分而治之”的思想:

从算法中可以看出,决策树是一个递归算法,其关键是如何选择最优划分属性,即选择最具有区分性的属性,可以大大减少计算量,提升效率。递归算法结束的条件有3种:
①当前结点所有样本都属于同一类别(已经完成划分)
②当前属性集为空(没有可以用来继续划分的属性),或所有样本在所有属性上取值相同(属性不具有区分性)
③当前结点包含的样本集合为空(没有样本了,也就无法划分)
我们希望决策树的分支节点所包含的样本尽量属于同一类别,即节点的“纯度”尽可能高。例如,根据西瓜的某一属性可将众多西瓜分为A、B两类,如果这两类西瓜中的好瓜比例相等,这说明该属性不具备区分效果。而如果西瓜中的好瓜率相差较大,这说明该属性具有较好的区分效果。随着一系列属性的划分,叶子节点的坏瓜率或坏瓜率越高,则说明决策树的分类效果越好。
二、信息增益
通常,对于样本集合纯度的计算,可以通过计算信息熵的方式来度量。信息熵描述的是事件在结果出来之前对可能产生的信息量的期望,描述的是不确定性。信息熵越大,不确定性越大。
假设样本集合D共有N类,第k类样本所占比例为,则D的信息熵为:
H(D)的值越小,则表示样本集合D的纯度越高。
| 编号 | 色泽 | 根蒂 | 敲声 | 纹理 | 脐部 | 触感 | 好瓜 |
| 1 | 青绿 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 2 | 乌黑 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 3 | 乌黑 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 4 | 青绿 | 蜷缩 | 沉闷 | 清晰 | 凹陷 | 硬滑 | 是 |
| 5 | 浅白 | 蜷缩 | 浊响 | 清晰 | 凹陷 | 硬滑 | 是 |
| 6 | 青绿 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 是 |
| 7 | 乌黑 | 稍蜷 | 浊响 | 稍糊 | 稍凹 | 软粘 | 是 |
| 8 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 硬滑 | 是 |
| 9 | 乌黑 | 稍蜷 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
| 10 | 青绿 | 硬挺 | 清脆 | 清晰 | 平坦 | 软粘 | 否 |
| 11 | 浅白 | 硬挺 | 清脆 | 模糊 | 平坦 | 硬滑 | 否 |
| 12 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 软粘 | 否 |
| 13 | 青绿 | 稍蜷 | 浊响 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 14 | 浅白 | 稍蜷 | 沉闷 | 稍糊 | 凹陷 | 硬滑 | 否 |
| 15 | 乌黑 | 稍蜷 | 浊响 | 清晰 | 稍凹 | 软粘 | 否 |
| 16 | 浅白 | 蜷缩 | 浊响 | 模糊 | 平坦 | 硬滑 | 否 |
| 17 | 青绿 | 蜷缩 | 沉闷 | 稍糊 | 稍凹 | 硬滑 | 否 |
以上列西瓜数据集为例,首先我们来计算根节点的信息熵,该数据集包含17个样本,其中有8个正例,9个反例。则根节点的信息熵为:
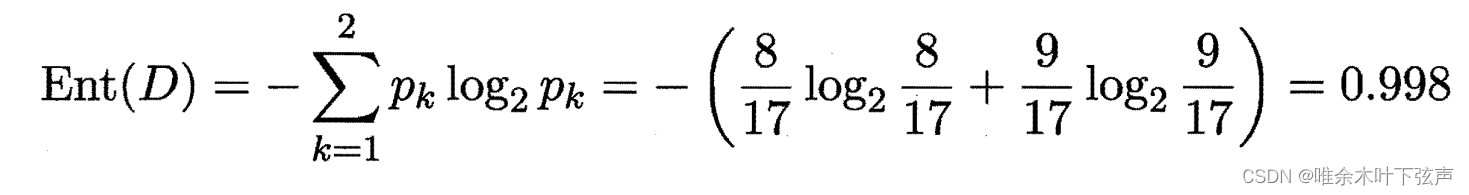
然后,我们要计算出色泽、根蒂、敲声、纹理、脐部、触感这些属性的信息增益。例如,色泽属性有3个可能的取值:青绿,乌黑,浅白。若使用该属性对样本集合D进行划分,则可得到3个子集,分别有6、6、5个样本,分别记为: (色泽=青绿),
(色泽=乌黑),
(色泽=浅白)。分别计算信息熵:
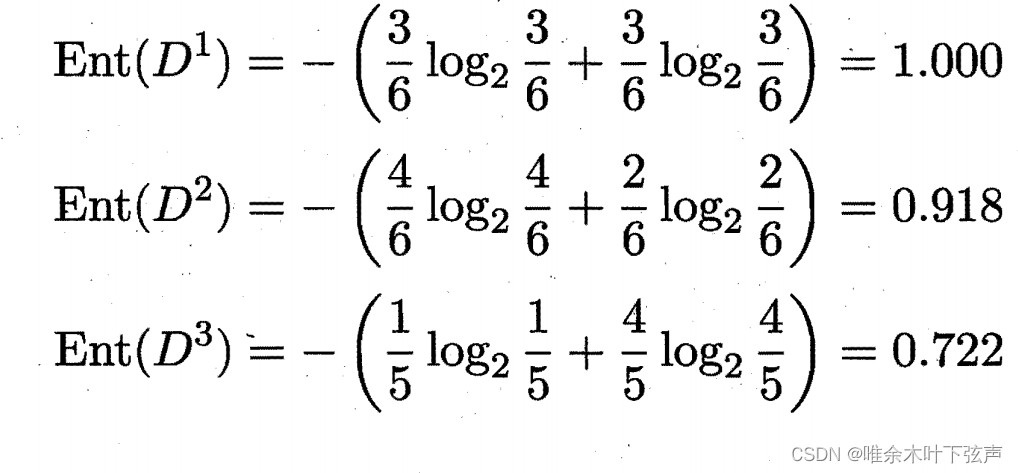
随后,可根据3个子集的信息熵来计算属性“色泽”的信息增益:
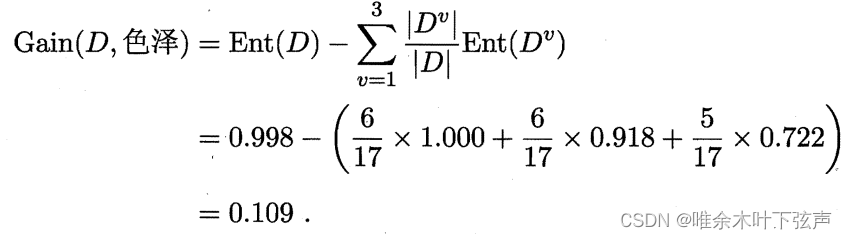
类似地,可以依次求出其他属性的信息增益:
Gain(D,根蒂)=0.143
Gain(D,敲声)=0.141
Gain(D,纹理)=0.381
Gain(D,脐部)=0.289
Gain(D,触感)=0.006
其中,属性“纹理”的信息增益最大,于是它被选为划分属性。根据属性“纹理”可将样本集合D划分为3个子集:清晰、稍糊、模糊,分别记为、
、
。

其中,样本集合包含有9个样例,可继续通过“色泽”,“根蒂”,“敲声”,“脐部”,“触感”这5个属性基于
计算出各属性的信息增益:
Gain(,色泽) = 0.043
Gain(,根蒂) = 0.458
Gain(,敲声)= 0.331
Gain(,脐部) =0.458
Gain(,触感)=0.458
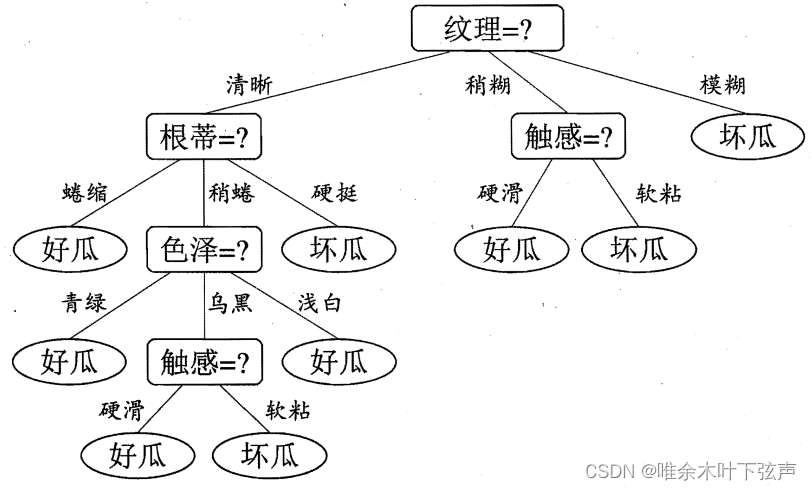
对于一个新瓜,我们就可以根据决策树模型来进行判断。
增益率:
除了可以通过信息增益来计算某个属性对样本集合的"纯度提升",还可以使用增益率、基尼指数来计算。由于信息增益准则对可取值数目较多的属性有所偏好,例如直接通过编号继续划分,可以划分为17个子样本集,每个子样本集中的正例占比为1或0,所有子样本集的信息熵之和为0,此时“编号属性”获得了最大的信息增益。但是,这样的决策树显然不具有泛化能力,无法对新样本进行有效预测。
为减少这种偏好可能带来的不利影响,著名的C4.5决策树算法不直接使用信息增益,而是使用增益率(gain ratio) 来选择最优划分属性:
其中:
称为属性
的固有值,属性
可能取值数目越多(即
越大),则
的值通常越大。不过这样一来,增益率准则会对取值数目少的属性有所偏好,因此C4.5算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式,分两步走:
①从候选划分属性选出信息增益高于平均水平的属性;
②再从中选择增益率最高的属性。
基尼指数:
在CART算法中,基于基尼指数来构建决策树,直接把纯度作为评价指标。数据集的基尼指数为:
直观来说:反映了从数据集
中随机抽取两个样本,其类别标记不一致的概率。因此,
越小,则数据集
的纯度越高。属性
的基尼指数定义为:
于是我们在候选属性集合中选择能够使划分后基尼指数最小的属性作为最优划分属性。大多数时候使用信息增益与基尼指数来选择属性进行划分的区别很小,不过信息增益对较混乱的数据集合有很好的表现力,而基尼指数容易区分纯度较高的数据集合。
三、剪枝处理
在决策树中,为了尽可能正确地分类训练样本,将不断重复划分过程,有时会造成决策树分支过多,导致决策树在测试集上的分类效果不尽如人意。剪枝是决策树学习算法避免“过拟合”的主要手段,在决策树中,过拟合表现为“决策分支过多”,因此可以主动剪去一些分支来降低过拟合的风险,主要有预剪枝和后剪枝两种方法。
预剪枝:
在决策树生成过程中,在对每个结点划分前,对该节点划分前后的性能进行估计,如果不能带来泛化性能的提升,则停止划分并标记为叶节点,也就是把该节点向下的枝条剪除了,避免过拟合。对树中节点的预剪枝的过程如下:
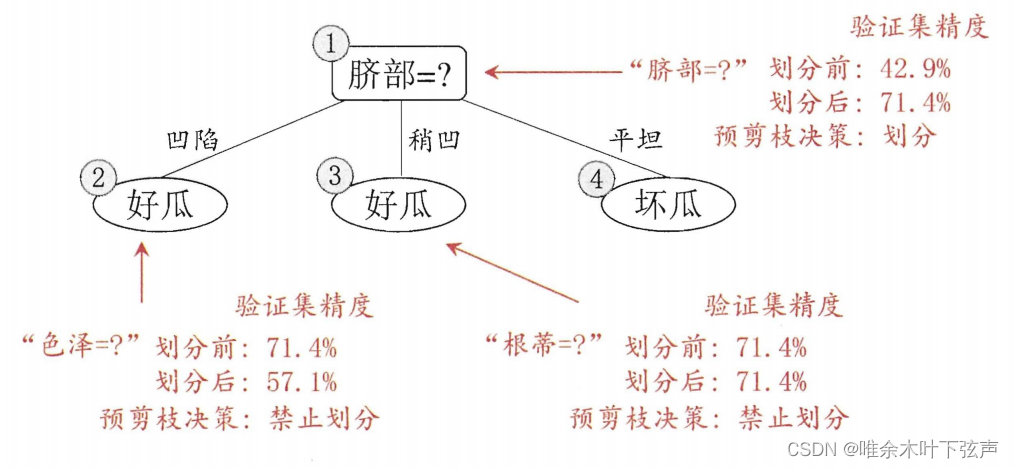
①先将该节点标记为叶节点,类别标记为样例中占比最多的类别;
②使用验证集进行验证,并计算验证集精度;
③将该节点进行划分,并计算验证集精度;
④若划分后精度没有提升,则禁止该节点进行划分。
预剪枝使得决策树的很多分支都没“展开”,不仅能降低过拟合的风险,还可以减少决策树的时间开销。不过另一方面,有些分支的当前划分虽不能提升泛化性能、甚至可能导致泛化性能暂时下降,但在其基础上进行的后续划分却有可能导致性能显著提高(也就是局部最优和全局最优的概念)。预剪枝基于"贪心"本质禁止这些分支展开会给预剪枝决策树带来了欠拟含的风险,也就是对训练样本的学习不够充分。
后剪枝:
与预剪枝不同的是,后剪枝先训练生成一棵完整的决策树,然后自底向上对非叶节点进行考察,若将该节点对应的子树替换成叶节点能够带来决策树泛化性能提升,则将该子树替换成叶节点(即先训练出来,再进行剪枝)。后剪枝过程如下:
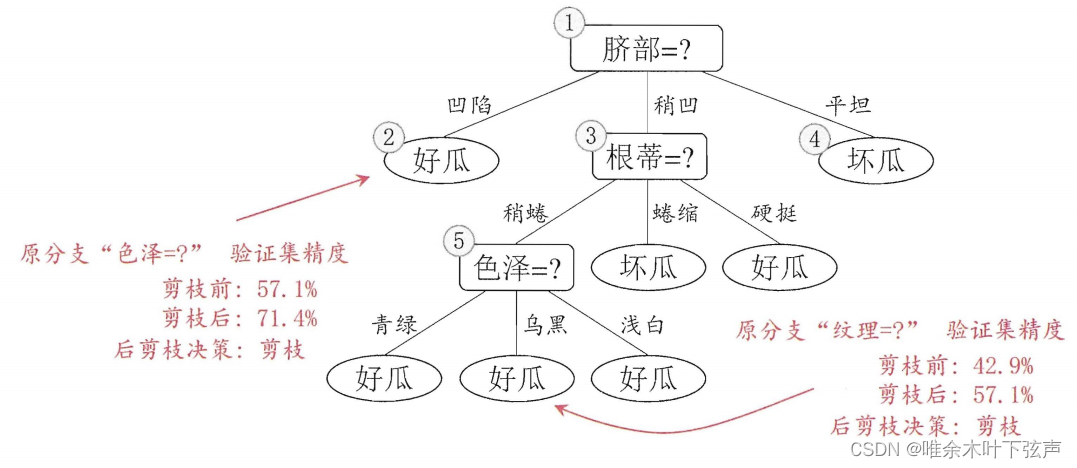
①先训练出一整棵决策树;
②自下而上,将一个节点的分枝剪掉后,训练集精度若有所提升,则决定剪枝
后剪枝决策树通常比预剪枝决策树保留了更多的分支,欠拟合风险更小,泛化性能往往优于剪枝决策树。但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上对树中的所有非叶结点进行逐一考察,因此其训练时间开销非常大。
四、Sklearn调用决策树分类器
实验所使用的数据集为Iris数据集,也称鸢尾花卉数据集,常用于分类任务。Iris数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn import tree
import graphviz
#数据集导入
iris = load_iris()
#划分训练集-测试集
train_X, test_X, train_y, test_y = train_test_split(iris.data, iris.target, test_size=0.3, random_state=1)#训练集,测试集分类
clf = tree.DecisionTreeClassifier(criterion='entropy', #使用信息熵计算纯度,也可用“gini”:基尼指数
max_depth=3 #决策树最大深度为3
)
#决策树训练
clf = clf.fit(train_X, train_y)
#测试
pred = clf.predict(test_X)
#计算准确率
print('ACC:',round(accuracy_score(test_y,pred),3))
#决策树可视化
feature_name = ['Sepal_Length','Sepal_Width','Petal_Length','Petal_Width']
class_name = ['Setosa','Versicolour','Virginica']
dot_data = tree.export_graphviz(clf
,out_file = None
,feature_names = feature_name
,class_names= class_name
,filled=True #颜色填充
,rounded=True #框框的圆角
)
graph = graphviz.Source(dot_data)
graph.view()可计算得到决策树算法在测试集上的准确率为0.956。决策树结构如下:

五、总结
决策树算法较为简单,且可解释性强,可以处理连续(通过选取划分点)和离散类型的数据。不过决策树容易出现过拟合,如果构建的决策树过于复杂,则无法很好地在数据上实现泛化。为了避免决策树的过拟合,可结合集成算法使用决策树,如bagging算法和boosting算法。
参考资料:
1、周志华《机器学习》(西瓜书)