认识决策树
决策树算法是一种逼近离散函数值的方法。它是一种典型的分类方法,首先对数据进行处理,利用归纳算法生成可读的规则和决策树,然后使用决策对新数据进行分析。本质上决策树是通过一系列规则对数据进行分类的过程。
决策树算法构造决策树来发现数据中蕴涵的分类规则.如何构造精度高、规模小的决策树是决策树算法的核心内容。决策树构造可以分两步进行。第一步,决策树的生成:由训练样本集生成决策树的过程。一般情况下,训练样本数据集是根据实际需要有历史的、有一定综合程度的,用于数据分析处理的数据集。第二步,决策树的剪枝:决策树的剪枝是对上一阶段生成的决策树进行检验、校正和修下的过程,主要是用新的样本数据集(称为测试数据集)中的数据校验决策树生成过程中产生的初步规则,将那些影响预衡准确性的分枝剪除。
决策树(decision tree)是一种基本的分类与回归方法。决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。
其主要优点是模型具有可读性,分类速度快。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型。预测时,对新的数据,利用决策树模型进行分类。
决策树学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。
通过一个对话例子
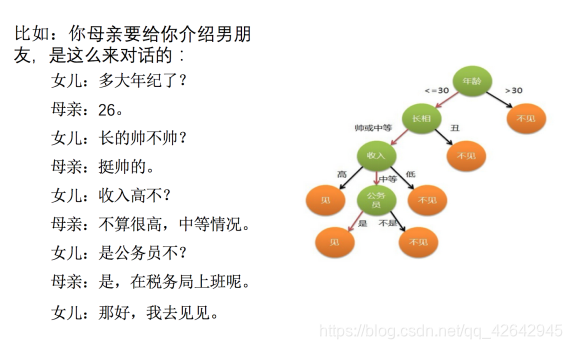
想一想这个女生为什么把年龄放在最上面判断!!!!!!!!!
决策树分类原理详解
为了更好理解决策树具体怎么分类的,我们通过一个问题例子?
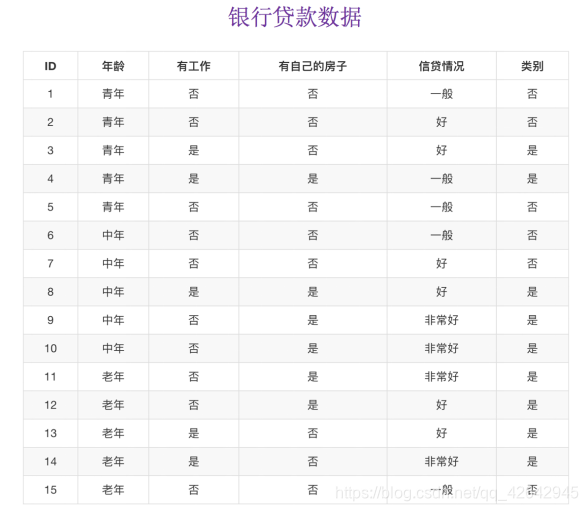
问题:如何对这些客户进行分类预测?你是如何去划分?
有可能你的划分是这样的
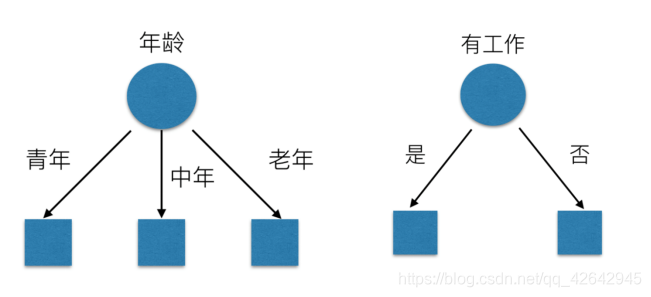
那么我们怎么知道这些特征哪个更好放在最上面,那么决策树的真是划分是这样的
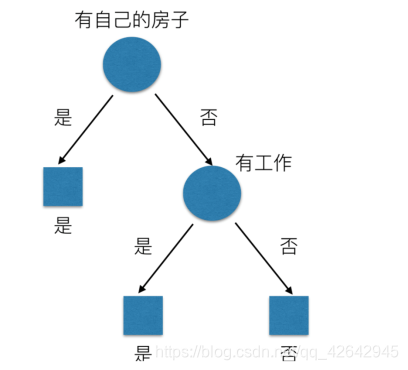
原理
信息熵、信息增益等
需要用到信息论的知识!!!问题:通过例子引入信息熵
信息熵的定义
H的专业术语称之为信息熵,单位为比特。
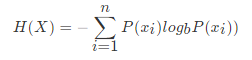
例如:16个数bool中,9个是,6个否
是的概率:p(x是)= 9/15
否的概率:p(x否)= 6/15
信息熵:H(x) = -(9/15log(9/15)+6/15log(6/15))
决策树的划分依据之一------信息增益
- 定义与公式
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:
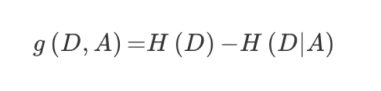
公式的详细解释:

注:信息增益表示得知特征X的信息而息的不确定性减少的程度使得类Y的信息熵减少的程度 - 贷款特征重要计算
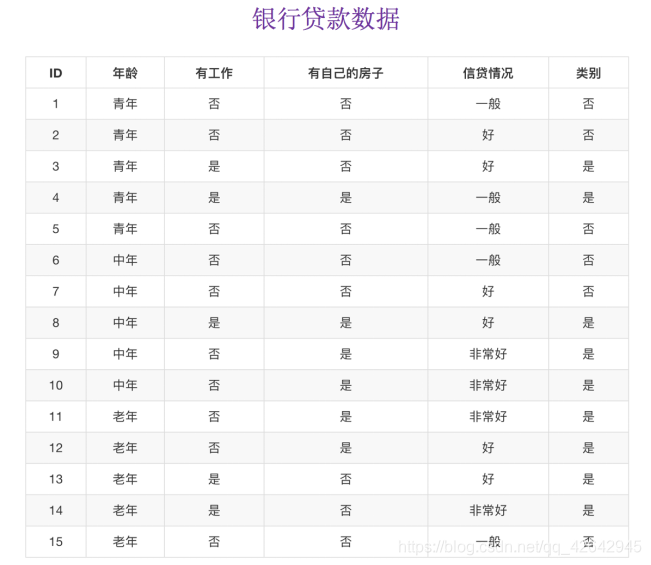
- 我们以年龄特征来计算:
- g(D, 年龄) = H(D) -H(D|年龄) = 0.971-[5/15H(青年)+5/15H(中年)+5/15H(老年]
- H(D) = -(6/15log(6/15)+9/15log(9/15))=0.971
- H(青年) = -(3/5log(3/5) +2/5log(2/5))
H(中年)=-(3/5log(3/5) +2/5log(2/5))
H(老年)=-(4/5og(4/5)+1/5log(1/5))
我们以A1、A2、A3、A4代表年龄、有工作、有自己的房子和贷款情况。最终计算的结果g(D, A1) = 0.313, g(D, A2) = 0.324, g(D, A3) = 0.420,g(D, A4) = 0.363。所以我们选择A3 作为划分的第一个特征。这样我们就可以一棵树慢慢建立
决策树的划分依据之一------信息增益
当然决策树的原理不止信息增益这一种,还有其他方法。但是原理都类似,我们就不去举例计算。
- ID3
- 信息增益 最大的准则
- C4.5
- 信息增益比 最大的准则
- CART
- 分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的默认原则
- 优势:划分更加细致(从后面例子的树显示来理解)
决策树API
- class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
- 决策树分类器
- criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’
- max_depth:树的深度大小
- random_state:随机数种子
案例:泰坦尼克号乘客生存预测
- 泰坦尼克号数据
在泰坦尼克号和titanic2数据帧描述泰坦尼克号上的个别乘客的生存状态。这里使用的数据集是由各种研究人员开始的。其中包括许多研究人员创建的旅客名单,由Michael A. Findlay编辑。我们提取的数据集中的特征是票的类别,存活,乘坐班,年龄,登陆,home.dest,房间,票,船和性别。
1 乘坐班是指乘客班(1,2,3),是社会经济阶层的代表。
2 其中age数据存在缺失。
数据:http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt

分析步骤 - 选择重要的若干个特征,例如 [‘pclass’, ‘age’, ‘sex’]
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import export_graphviz
# 1、获取数据
titan = pd.read_csv("http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic.txt")
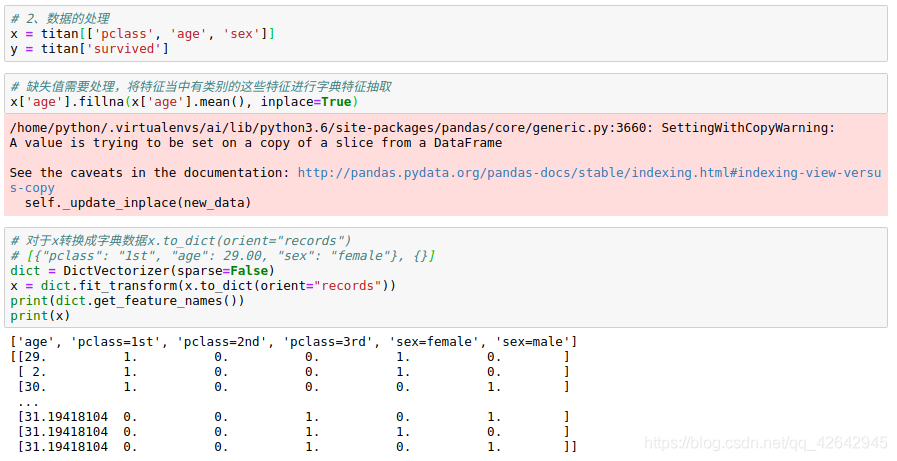
# 2、数据的处理
x = titan[['pclass', 'age', 'sex']]
y = titan['survived']
- 使用fillna填充缺失值
# 缺失值需要处理,将特征当中有类别的这些特征进行字典特征抽取
x['age'].fillna(x['age'].mean(), inplace=True)
- 特征中出现类别符号,需要进行one-hot编码处理(DictVectorizer)
- x.to_dict(orient=“records”) 需要将数组特征转换成字典数据
# 对于x转换成字典数据x.to_dict(orient="records")
# [{"pclass": "1st", "age": 29.00, "sex": "female"}, {}]
dict = DictVectorizer(sparse=False)
x = dict.fit_transform(x.to_dict(orient="records"))
print(dict.get_feature_names())
print(x)
- 数据集划分
# 分割训练集合测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
- 决策树分类预测
决策树API当中,如果没有指定max_depth那么会根据信息熵的条件直到最终结束。这里我们可以指定树的深度来进行限制树的大小
# 进行决策树的建立和预测
# 指定树的深度大小为5
dc = DecisionTreeClassifier(criterion='entropy', max_depth=5)
dc.fit(x_train, y_train)
print("预测的准确率为:", dc.score(x_test, y_test))

决策树的结构是可以直接显示的,所以
决策树可视化
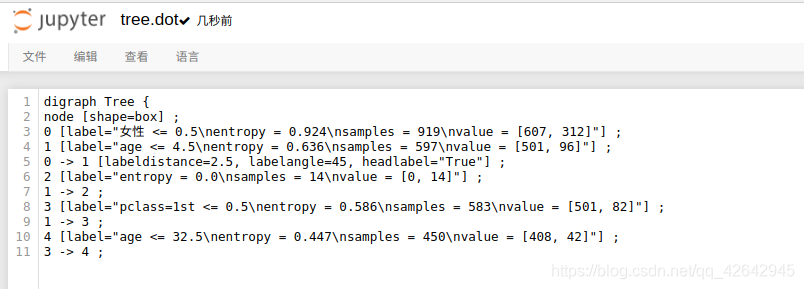
保存树的结构到dot文件
- sklearn.tree.export_graphviz() 该函数能够导出DOT格式
- tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
export_graphviz(dc, out_file="./tree.dot", feature_names=['age', 'pclass=1st', 'pclass=2nd', 'pclass=3rd', '女性', '男性'])

dot文件当中的内容如下
那么这个结构不能看清结构,所以可以在一个网站上显示
网站显示结构
http://webgraphviz.com/
将dot文件内容复制到该网站当中显示
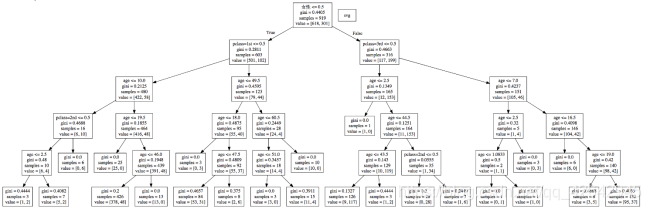
本地显示结构
也可以使用模块打开:
首先安装graphviz
sudo apt-get install graphviz
然后生成运行如下命令,生成流程图:
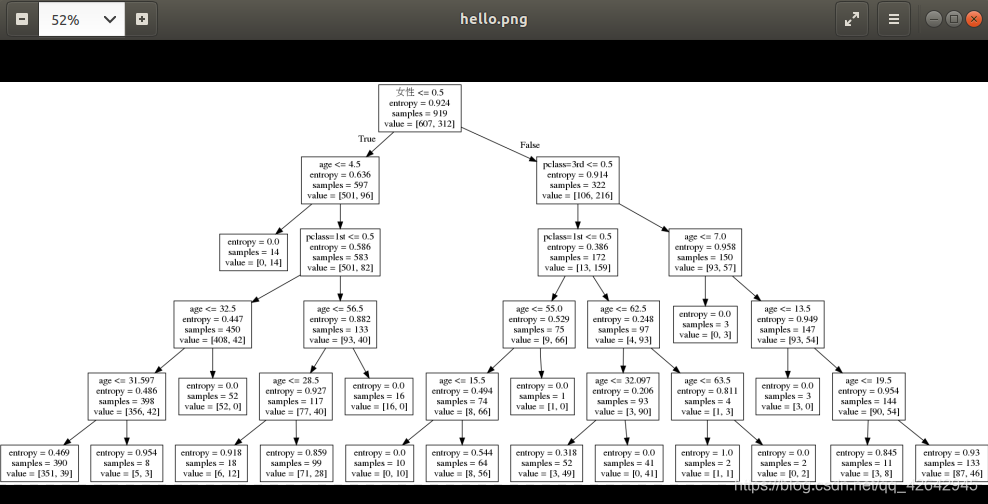
dot -Tpng -o hello.png tmp.dot
打开图片:
xdg-open hello.png

结果如下:
决策树总结
- 优点:
- 简单的理解和解释,树木可视化。
- 缺点:
- 决策树学习者可以创建不能很好地推广数据的过于复杂的树,这被称为过拟合。
- 改进:
- 减枝cart算法(决策树API当中已经实现,随机森林参数调优有相关介绍)
- 随机森林
注:企业重要决策,由于决策树很好的分析能力,在决策过程应用较多, 可以选择特征