图表示学习和异质信息网络
选自
[1]李青,王一晨,杜承烈.图表示学习方法研究综述[J/OL].计算机应用研究:1-16[2023-05-11].DOI:10.19734/j.issn.1001-3695.2022.09.0504.
[2]石川,王睿嘉,王啸.异质信息网络分析与应用综述[J].软件学报,2022,33(02):598-621.DOI:10.13328/j.cnki.jos.006357.
图表示学习
图表示学习是指将一个图中的节点或者整(子)图映射到低维向量空间的过程,其主要目是使低维向量空间中的几何关系能够反映原始图中的结构信. 优化后的低维向量空间所学习到的嵌入向量能够作为特征输入来处理下游任务.在解决特定任务时,使用图表示学习技术进行学习的对象也有所不同,可以将图表示学习分为以下 3 种:
- 节点嵌入:图数据中的节点往往表示了各类重要实体,这些节点本身具有大量的属性作为其特征,通过捕捉节点的属性,对其进行表示学习以获得更低维度的节点嵌入,能够对现实中的实体进行更有效的分析.
- 边嵌入:实体间存在的或紧密或疏远的关系,可借助于图的边来表示.边所表示的不同依赖关系存在着重要性大小的差异,使得部分边自带有权重属性.因此,在对边进行表学习时,可获得边本身的属性特征及所关联节点的特征来进行补充表示.
- 子图嵌入:子图嵌入即将子图作为一个整体进行表示学习,获得低维嵌入向量.该方法首先需要根据一定的规则构造适当的子图,接着在子图中捕捉图中节点的属性和结构特征.在处理的数据量较大时,子图有时用于代替整图,能够大大减少计算成本.
基本概念
图: G = < V , E , T , X > G=<V,E,T,X> G=<V,E,T,X>, V V V是节点集合, E E E是边集, X X X表示属性矩阵。函数 φ : V → T v \varphi:V\rightarrow T_v φ:V→Tv 和 ϕ : E → T E \phi:E\rightarrow T_E ϕ:E→TE分别对节点和边进行映射,其中 T V T_V TV表示节点类型的集合, T E T_E TE表示边类型的集合。若 T V = T E = 1 T_V=T_E=1 TV=TE=1,则G是一个同构图,若 ∣ T V ∣ + ∣ T E ∣ > 2 |T_V|+|T_E|>2 ∣TV∣+∣TE∣>2,则G是一个异构图。
邻接矩阵 A A A, A [ i ] [ j ] = 1 A[i][j]=1 A[i][j]=1表示 v i v_i vi 和 v j v_j vj 之间有边,否则没有边
度矩阵 D D D是一个对角矩阵, D [ i ] [ i ] = ∑ j = 1 ∣ v ∣ A [ i ] [ j ] D[i][i]=\sum^{|v|}_{j=1}A[i][j] D[i][i]=∑j=1∣v∣A[i][j]表示 v i v_i vi的度
图拉普拉斯矩阵为 L = D − A L=D-A L=D−A
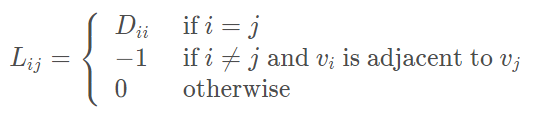
解释:拉普拉斯矩阵的对角线上取值为节点的度;如果节点 v i v_i vi 和 v j v_j vj相邻,那么取值为-1;拉普拉斯矩阵为对称的矩阵。谱图理论是图论与线性代数相结合的产物,它通过分析图的某些矩阵的特征值与特征向量而研究图的性质。拉普拉斯矩阵是谱图理论中的核心与基本概念,在机器学习与深度学习中有重要的应用。
图表示学习的目的是找到一个映射 f : v i → y i ∈ R d f:v_i \rightarrow y_i \in R^d f:vi→yi∈Rd,其中 y i y_i yi是 v i v_i vi的嵌入向量,嵌入维度 d ≪ ∣ V ∣ d\ll |V| d≪∣V∣
一阶相似度:如果 ( v i , v j ) ∈ E (v_i,v_j)\in E (vi,vj)∈E,那么 v i v_i vi 和 v j v_j vj之间的一阶相似性由两节点之间的边权重决定;否则 v i v_i vi 和 v j v_j vj之间的一阶相似性为 0. 一阶相似性捕捉了节点之间的直接邻居关系.

二阶相似度和高阶相似性:二阶相似度捕捉每对节点之间的两步关系.对于每个节点对 ( v i , v j ) (v_i,v_j) (vi,vj),二阶相似度是由两个顶点共有的相同的邻居节点数决定的,它同样可以用 v i v_i vi 到 v j v_j vj 的两步迁移概率来度量. 进一步,高阶相似度捕捉每对节点之间的 k 步关系(k≥3),能更好地保留图的全局结构.
相关技术
基于降维解析的方法
基于降维解析的图表示学习方法是将高维图结构数据降维成低维表示,同时保留原始数据的期望属性。其关键优势在于能通过深层降维架构学习更多层次性数据特征,无须针对特定的图数据形式设计具体的人工特征,显著地提升了图表示学习的效果。具体可分为线性降维和非线性降维两种方式,其中线性降维方法可分为主成分分析法、线性判别分析法和多维标度法等;非线性降维方法则主要包括:等度量映射法、局部线性嵌入法、核方法等。
基于矩阵分解的方法
基于矩阵分解的图表示学习方法,也称为图分解方法,其通常采用一个矩阵来表示图的特征,节点嵌入表示则通过分解此矩阵实现,是第一种达到 O(|E|) 时间复杂度的图表示学习方法。主要分为两种类型,一种是图拉普拉斯矩阵分解,另一种是基于节点邻近性的矩阵分解。
基于随机游走的方法
基于随机游动的图表示方法适用于包含大量路径关系的图,其中路径关系蕴涵图的拓扑信息。首先,基于随机游走的图表示方法的游走随机性促进模型高效学习图节点信息。其次,该方法通过遍历相邻节点来捕获图拓扑信息。最后在随机采样的路径上执行概率模型,以完善节点特征表示。
基于深度学习的方法
基于卷积神经网络的方法
图卷积网络模型(GCN)是研究者由图卷积理论受到启发而设计的一个层级网络传播模型,主要应用于半监督学习问题,是一种基于高效卷积神经网络的变体。GCN 采用谱图卷积的局部一阶近似直接对图进行操作,充分学习隐藏层表示,既可以捕获图的局部拓扑信息、也可以学习节点特征信息。
基于注意力神经网络的方法
图注意力网络模型(GAT)是注意力机制应用于图表示学习领域的一次大胆尝试,解决了已有基于卷积神经网络的图表示方法只能捕获图的局部拓扑信息问题。GAT 无须预构建图,因此也解决了一些基于谱的图神经网络中存在的问题。图注意力层是 GAT 的核心设计。首先,GAT 根据输入的节点向量在图注意力层进行自注意力计算,其次,GAT 使用了掩码(mask)机制避免图拓扑信息的损失。最后,为了降低计算复杂度,GAT 将注意力机制严格限制在节点的邻域节点集上。
基于生成对抗网络的方法
相较于其他图表示模型的训练,生成对抗网络思想避免了马尔可夫链的使用,大大降低了计算成本。其次,理论上所有可微分函数都可以用于构建生成对抗网络中的生成器和辨别器,确保了生成对抗网络框架极易应用于图表示学习领域,无须遵循任何种类的因式分解去设计模型,所有的生成器和鉴别器即能正常工作。最后,生成对抗网络的对抗学习的思想大大提升了模型的鲁棒性。
基于对比学习网络的方法
现有的图表示学习方法大多只适用于有监督学习,其所需的高质量标签获取难度高。基于对比学习的图表示学习方法较好的解决了此问题,其专注自监督学习,通过学习高层次抽象级别的特征来区别并分类不同的节点信息,进而编码节点的属性以及结构特征。
基于时空动态网络的方法
图表示神经网络模型已被广泛应用于图结构数据的建模和表征学习,但是已有的方法局限于静态网络数据,忽视了网络模型的动态可扩展性。而现实世界中的许多网络呈现动态行为,包括拓扑演化、特征演化和扩散等,基于时空动态网络的图表示学习方法学习的出现解决了这一问题。因此,在动态图表示学习中,合理描述节点和边的动态变化是研究的重点。
超图
社交网络中节点对关系远比简单图边的关系复杂,故简单图很难充分表示社交网络的信息,超图的出现解决了此问题。超图结构常被用来模拟数据之间的高阶相关性,可以更好地搭建网络数据中的社区结构。超图神经网络模型将图卷积思想应用于超图领域,高效捕获了节点的非线性高阶关联。
异构图
异构图表示旨在低维空间中学习图中不同类型节点表示,同时保留异质结构和语义用于下游任务。对比超图表示,异构图表示具有更强的数据样本间非线性高阶关联的刻画和挖掘能力,而超图表示更加注重建模节点间的多元关系。此外,对比同构图表示,异构图表示和超图表示均能学习到图中更全面的信息和更丰富的语义,并且在处理多模态数据时更加灵活,更方便多模态的融合与扩展,在知识图谱等领域应用广泛。
异质信息网络
大多数工作将信息网络建模成同质信息网络(homogeneous information network,同质网络),即网络中仅包含相同类型的对象和链接, 例如作者合作网和朋友圈等. 同质网络建模方法往往只抽取了实际交互系统中的部分信息,或者没有区分对象及其之间关系的异质性, 从而造成不可逆的信息损失。
近年来, 更多的研究者将多类型且互连的网络化数据建模为异质信息网络(heterogeneous information network, 异质网络),实现对现实世界更完整而自然的抽象,例如, 文献数据中包含作者、论文、会议等不同类型的对象, 这些对象间存在多种类型的关系: 作者和论文间的撰写/被撰写关系、会议和论文间的出版/被出版关系等. 利用异质网络建模这种类型丰富且交互复杂的数据, 可以保留更全面的语义及结构信息.
相较于同质网络, 异质网络建模带来了两方面的好处:
- 异质网络是融合信息的有效工具,不仅可以自然融合不同类型的对象及其交互,而且可以融合异构数据源的信息,特别地,随着“大数据”时代的到来,在“大数据”中许多类型不同的对象互联,将这些交互对象建模为同质网络很困难,但可以很自然地利用异质网络建模;同时,不同平台产生的异构多源“大数据”仅捕获了部分甚至是有偏差的特征,异质网络也可以自然融合这些异构数据源的信息,从而全面刻画用户特征。 因此,异质网络建模不仅成为解决大数据多样性的有力工具,而且成为宽度学习的主要方法;
- 异质网络中多类型对象和关系共存,包含丰富的结构和语义信息,从而为发现隐含模式提供了精准可解释的新途径,例如,推荐系统的异质网络中不再只有用户和商品这两种对象,而是包含店铺、品牌等更全面的内容;关系也不再只有购买,而是含有收藏、喜爱等更精细的交互。
基本概念
信息网络:为一个具有对象类型映射函数 φ : V → A \varphi:V\rightarrow A φ:V→A 和关系类型映射函数 ϕ : E → R \phi:E\rightarrow R ϕ:E→R的有向图 G = < V , E , φ , ϕ > G=<V,E,\varphi,\phi> G=<V,E,φ,ϕ>,其中,每个对象 v ∈ V v\in V v∈V属于对象类型的集合 A A A中的一个特定对象类型,每条链接 e ∈ E e\in E e∈E属于关系类型集合 R R R中的一个特定关系类型。
异质/同质网络:若信息网络的对象类型数|A|>1或者关系类型数|R|>1,则称其为异质网络;否则,称为同质网络。
网络模式:网络模式记为 T G = ( A , R ) T_G=(A,R) TG=(A,R), 是带有对象类型映射 φ \varphi φ和关系类型映射 ϕ \phi ϕ的信息网络 G = < V , E , φ , ϕ > G=<V,E,\varphi,\phi> G=<V,E,φ,ϕ>的元模式.
图1给出了文献数据所构建的信息网络,(b)说明了描述文献异质网络对象及其之间关系类型的网络模式,(a)是(b)的网络实例。在该实例中, 包含 3 种类型的对象: 论文(P)、作者(A)和会议(C). 链接连接不同类型的对象,而链接的类型由两种对象类型间的关系定义,例如,作者和论文间的链接表示撰写或被撰写的关系, 而会议和论文间的链接表示出版或被出版的关系

语义探索方法

元路径
元路径 P 是在网络模式 T G = ( A , R ) T_G=(A,R) TG=(A,R)上定义的路径, 记为 A 1 → R 1 A 2 → R 2 . . . → R l A l + 1 A_1\stackrel{R_1}{\rightarrow} A_2\stackrel{R_2}{\rightarrow}...\stackrel{R_l}{\rightarrow} A_{l+1} A1→R1A2→R2...→RlAl+1同时, 定义对象 A 1 , A 2 , . . . , A l + 1 A_1,A_2,...,A_{l+1} A1,A2,...,Al+1 间的复合关系 R = R 1 ∘ R 2 ∘ … R l R=R_1\circ R_2\circ…R_l R=R1∘R2∘…Rl, 其中, ∘ \circ ∘表示关系上的合成运算符.
以图 2 所示的电影推荐异质网络为例. 用户可以通过元路径相连, 如 U → r a t e M → r a t e − 1 U U\stackrel{rate}{\rightarrow} M\stackrel{rate^-1}{\rightarrow}U U→rateM→rate−1U ( U M U UMU UMU)路径和 U → r a t e M → d i r e c t − 1 D → d i r e c t M → r a t e − 1 U U\stackrel{rate}{\rightarrow} M\stackrel{direct^-1}{\rightarrow}D\stackrel{direct}{\rightarrow}M\stackrel{rate^-1}{\rightarrow}U U→rateM→direct−1D→directM→rate−1U ( U M D M U UMDMU UMDMU)等. 这些路径包含的语义不同, U M U UMU UMU路径是指用户对同一电影打分(即共同评分关系), 而 U M D M U UMDMU UMDMU 路径表示用户对同一导演的电影作品打分.
元路径本质上抽取了异质网络的子结构, 并且体现了路径所包含的丰富语义信息, 因而成为异质网络分析中的基本语义捕捉方法.但是由于其结构简单, 在捕捉更精确或复杂的语义时往往受到限制.
受限元路径
UMU 路径无法刻画精确到某些类型电影的共同评分关系. 因此, 受限元路径应运而生.
受限元路径是基于某种特定约束的元路径, 可以表示为CP=P|C. 其中, P=( A 1 , A 2 , . . . , A l A_1,A_2,...,A_l A1,A2,...,Al)表示元路径, C表示对元路径 P 中对象的约束. 受限元路径 UMU|M.T=“Comedy”利用“Comedy”标签约束电影, 使得该路径表示用户对喜剧电影的共同评分关系.
加权元路径
元路径并未考虑链接上的属性, 如用户对于电影的评分信息, 从而使得路径实例间链接的属性差异诱发较大的语义差异. 因而, 加权元路径的概念被提出, 以进一步约束链接属性信息.
加权元路径是对关系属性值有所约束的一种扩展元路径, 可以表示为 A 1 → δ ( R 1 ) A 2 → δ ( R 2 ) . . . → δ ( R l ) A l + 1 ∣ C A_1\stackrel{\delta(R_1)}{\rightarrow} A_2\stackrel{\delta(R_2)}{\rightarrow}...\stackrel{\delta(R_l)}{\rightarrow} A_{l+1}|C A1→δ(R1)A2→δ(R2)...→δ(Rl)Al+1∣C.用户 U 与电影 M 间评分关系的属性值可以取 1 至 5 分. 加权元路径 U → 1 M U\stackrel{1}{\rightarrow} M U→1M (即 U(1)M)表示用户对电影的评分为 1, 也就意味着用户并不喜欢这部电影; 加权元路径 U → 1 , 2 M → 1 , 2 U U\stackrel{1,2}{\rightarrow} M\stackrel{1,2}{\rightarrow}U U→1,2M→1,2U 则表示用户和目标用户不喜欢相同的电影.
元结构/元图
元路径是定义在元模式 T G = ( A , R ) T_G=(A,R) TG=(A,R)上的线性序列, 而元结构/元图 M可看作多条有公共节点的元路径组合而成的有向无环图.
对于元路径 UMDMU 和 UMAMU 而言, 只能分别描述两用户对同一导演的电影打分或已打分电影中出现相同演员, 无法同时表述两条元路径蕴含的公共关系: 两用户对于同一导演的电影作品进行了打分并且电影作品中出现了相同演员. 而利用元结构/元图可以描述该语义, 如图 2©所示. 可以看到, 元结构/元图M 是定义在网络模式上的有向无环图.
异质网络表示学习
类比图表示学习的方法
