GAN入门实践
一、题目介绍
题目链接:Use GANs to create art - will you be the next Monet?
我们通常通过艺术家的独特风格来识别他们的作品,例如颜色选择或笔触。生成对抗网络(GAN)现在可以用算法模仿像莫奈这样的艺术家的作品。在这个题目中,将尝试把这种风格带到照片中,或者从零开始创造这种风格!
GAN 现在能够以非常令人信服的方式模仿物体,但创造博物馆级的杰作被认为是艺术而非科学。那么科学能否以 GAN 的形式欺骗分类器,让他们相信你创造了一个真正的莫奈?
二、GAN介绍
GAN 至少由两个神经网络组成:一个生成器模型和一个判别器模型。生成器是创建图像的神经网络,生成器使用鉴别器进行训练。
这两个模型将相互对抗,生成器试图欺骗鉴别器,而鉴别器试图准确地对真实图像和生成的图像进行分类。

生成器G和判别器D的相同点是:
- 这两个模型都可以看成是一个黑匣子,接受输入然后有一个输出,类似一个函数,一个输入输出映射。
其不同点是:
- 生成模型功能:比作是一个样本生成器,输入一个样本,然后通过他生成另一个样本。
- 判别模型:用以判断生成的样本和真实目标之间的差距。
三、CycleGAN
3.1 模型介绍
Cycle GAN是Jun-Yan Zhu等人提出的图像-图像转换对抗网络。图像-图像转换问题的目标是学习一种从源域到目标域的转换 G : X → Y G:\ X\rightarrow Y G: X→Y,使得在判别器上X和Y的分布不可区分。
但是,这种映射往往会是欠约束的,所以作者使用了另一个新的映射 F : G ( X ) → X F:\ G(X) \rightarrow X F: G(X)→X与映射G耦合,来实现模型训练的一致性。这种方法来自语言翻译中的“循环一致”原则:从中文翻译成英文的句子,反义会中文,应当回到原始的句子。
3.2 算法架构
其结构示意图如下所示:
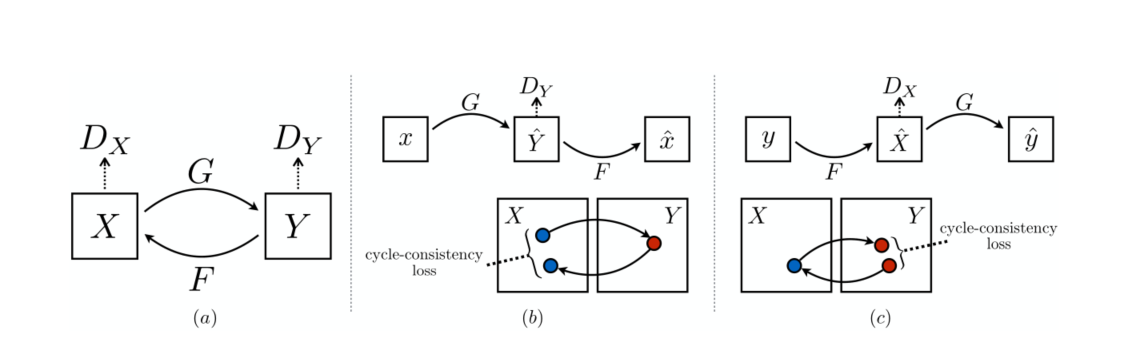
模型包括两个生成器 G G G和 F F F,和与其相关的判别器 D Y D_Y DY和 D X D_X DX
- G : X → Y G:\ X\rightarrow Y G: X→Y
- F : Y → X F:\ Y\rightarrow X F: Y→X
- Y ^ = G ( X ) , X ^ = F ( Y ) \hat{Y} = G(X),\ \ \ \hat{X}=F(Y) Y^=G(X), X^=F(Y)
- D Y : L o s s ( Y ^ , Y ) D_Y:\ Loss(\hat{Y}, Y) DY: Loss(Y^,Y)
- D X : L o s s ( X ^ , X ) D_X:\ Loss(\hat{X}, X) DX: Loss(X^,X)
- 正向一致性损失: L o s s ( X , F ( Y ^ ) ) = L o s s ( X , F ( G ( X ) ) ) Loss(X, F(\hat{Y}))=Loss(X,F(G(X))) Loss(X,F(Y^))=Loss(X,F(G(X)))
- 反向一致性损失: L o s s ( Y , F ( X ^ ) ) = L o s s ( Y , G ( F ( Y ) ) ) Loss(Y, F(\hat{X}))=Loss(Y,G(F(Y))) Loss(Y,F(X^))=Loss(Y,G(F(Y)))
3.3 优化目标
经典的GAN采用负对数似然(NLL)来作为优化目标:
- 对于生成器G: L g = − E x ∼ p d a t a ( x ) ∣ log ( 1 − D ( G ( x ) ) ∣ L_g=-\mathbb{E}_{x\sim p_{data}(x)}|\log{(1-D(G(x))}| Lg=−Ex∼pdata(x)∣log(1−D(G(x))∣
用以最小化生成样本的“判别结果为真的样本”(判别器对真实目标输出为1,假目标为0)间的差距。 - 对于判别器D: L d = − E x ∼ p d a t a ( x ) ∣ log D ( G ( x ) ) ∣ + − E y ∼ p d a t a ( y ) ∣ log ( 1 − D ( y ) ) ∣ L_d=-\mathbb{E}_{x\sim p_{data}(x)}|\log{D(G(x))}|+-\mathbb{E}_{y\sim p_{data}(y)}|\log{(1-D(y))}| Ld=−Ex∼pdata(x)∣logD(G(x))∣+−Ey∼pdata(y)∣log(1−D(y))∣
其中前半部分最小化生成样本和“判别为假的样本”(即判别器输出0的样本)的距离,后半部分最小化对目标样本和“判别结果为真的样本”的距离。前半部分用于对抗生成器G,后半部分用于提示判别能力。
在CycleGAN中,我们将负对数似然改为最小二乘损失,这种损失在训练期间更稳定,并产生更高质量的结果。在优化生成器G的时候引入循环一致性损失 L c y c L_{cyc} Lcyc和同一性损失 L i d e n t i t y L_{identity} Lidentity作为正则化项。
- L G = E x ∼ p d a t a ( x ) [ ( 1 − D Y ( G ( x ) ) ) 2 ] L_{G}=\mathbb{E}_{x\sim p_{data}(x)}[(1-D_Y(G(x)))^2] LG=Ex∼pdata(x)[(1−DY(G(x)))2]
- L F = E y ∼ p d a t a ( y ) [ ( 1 − D X ( F ( y ) ) ) 2 ] L_{F}=\mathbb{E}_{y\sim p_{data}(y)}[(1-D_X(F(y)))^2] LF=Ey∼pdata(y)[(1−DX(F(y)))2]
- L D Y = E x ∼ p d a t a ( x ) [ D ( G ( x ) ) 2 ] + E y ∼ p d a t a ( y ) [ ( 1 − D ( y ) ) ) 2 ] L_{D_Y}=\mathbb{E}_{x\sim p_{data}(x)}[D(G(x))^2]+\mathbb{E}_{y\sim p_{data}(y)}[(1-D(y)))^2] LDY=Ex∼pdata(x)[D(G(x))2]+Ey∼pdata(y)[(1−D(y)))2]
- L D X = E y ∼ p d a t a ( y ) [ D ( F ( y ) ) 2 ] + E x ∼ p d a t a ( x ) [ ( 1 − D ( x ) ) ) 2 ] L_{D_X}=\mathbb{E}_{y\sim p_{data}(y)}[D(F(y))^2]+\mathbb{E}_{x\sim p_{data}(x)}[(1-D(x)))^2] LDX=Ey∼pdata(y)[D(F(y))2]+Ex∼pdata(x)[(1−D(x)))2]
- L f o r w a r d − c y c = E x ∼ p d a t a ( x ) [ ∥ F ( G ( x ) ) − x ∥ 1 ] L_{forward-cyc}=\mathbb{E}_{x\sim p_{data}(x)}[\Vert F(G(x))-x\Vert_1] Lforward−cyc=Ex∼pdata(x)[∥F(G(x))−x∥1]
- L b a c k w a r d − c y c = E y ∼ p d a t a ( y ) [ ∥ G ( F ( y ) ) − y ∥ 1 ] L_{backward-cyc}=\mathbb{E}_{y\sim p_{data}(y)}[\Vert G(F(y))-y\Vert_1] Lbackward−cyc=Ey∼pdata(y)[∥G(F(y))−y∥1]
- L i d t Y = E x ∼ p d a t a ( x ) [ ∥ G ( x ) − x ∥ 1 ] L_{idt_Y}=\mathbb{E}_{x\sim p_{data}(x)}[\Vert G(x)-x\Vert_1] LidtY=Ex∼pdata(x)[∥G(x)−x∥1]
- L i d t X = E y ∼ p d a t a ( y ) [ ∥ F ( y ) − y ∥ 1 ] L_{idt_X}=\mathbb{E}_{y\sim p_{data}(y)}[\Vert F(y)-y\Vert_1] LidtX=Ey∼pdata(y)[∥F(y)−y∥1]
- L g e n = ( L G + L F ) + λ 1 ( L f o r w a r d − c y c + L b a c k w a r d − c y c ) + λ 2 ( L i d t Y + L i d t X ) L_{gen}=(L_G+L_F)+\lambda_1(L_{forward-cyc}+L_{backward-cyc})+\lambda_2(L_{idt_Y}+L_{idt_X}) Lgen=(LG+LF)+λ1(Lforward−cyc+Lbackward−cyc)+λ2(LidtY+LidtX)
同一性损失的意义在与,使得某目标图像X经过对应的生成器后能与其本身差异最小。这可以防止如由于莫奈的画作大多在黄昏,所以生成器对所有输入样本天空生产的生产样本天空均为黄昏——无论在照片上是不是。
3.4 模型结构
生成器G/F
包含三个卷积层、几个残差块、两个反卷积层和一个将特征映射到RGB通道的卷积层,具体结构如下:
DataParallel(
(module): ResnetGenerator(
(model): Sequential(
(0): ReflectionPad2d((3, 3, 3, 3))
(1): Conv2d(3, 64, kernel_size=(7, 7), stride=(1, 1))
(2): InstanceNorm2d(64, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(5): InstanceNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(6): ReLU(inplace=True)
(7): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(8): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(9): ReLU(inplace=True)
(10): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(11): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(12): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(13): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(14): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(15): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(16): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(17): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(18): ResnetBlock(
(conv_block): Sequential(
(0): ReflectionPad2d((1, 1, 1, 1))
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(2): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(3): ReLU(inplace=True)
(4): ReflectionPad2d((1, 1, 1, 1))
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
)
)
(19): ConvTranspose2d(256, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(20): InstanceNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(21): ReLU(inplace=True)
(22): ConvTranspose2d(128, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), output_padding=(1, 1))
(23): InstanceNorm2d(64, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(24): ReLU(inplace=True)
(25): ReflectionPad2d((3, 3, 3, 3))
(26): Conv2d(64, 3, kernel_size=(7, 7), stride=(1, 1))
(27): Tanh()
)
)
)
判别器 D Y D_Y DY和 D X D_X DX
使用70×70 patchGAN的鉴别器网络,其目的是分类70×70重叠图像块。这种pacth级鉴别器架构比全图像鉴别器具有更少的参数,并且可以以完全卷积的方式处理任意化的图像。
具体结构如下:
DataParallel(
(module): NLayerDiscriminator(
(model): Sequential(
(0): Conv2d(3, 64, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(1): LeakyReLU(negative_slope=0.2, inplace=True)
(2): Conv2d(64, 128, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(3): InstanceNorm2d(128, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(4): LeakyReLU(negative_slope=0.2, inplace=True)
(5): Conv2d(128, 256, kernel_size=(4, 4), stride=(2, 2), padding=(1, 1))
(6): InstanceNorm2d(256, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(7): LeakyReLU(negative_slope=0.2, inplace=True)
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1))
(9): InstanceNorm2d(512, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1))
(8): Conv2d(256, 512, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1))
(9): InstanceNorm2d(512, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
(10): LeakyReLU(negative_slope=0.2, inplace=True)
(11): Conv2d(512, 1, kernel_size=(4, 4), stride=(1, 1), padding=(1, 1))
)
)
)
四、PyTorch实现
4.1 数据集
由于莫奈的画作和照片的数量并不一样,这里数据集进行非对齐实现
import os
import random
from torch.utils.data import Dataset
from PIL import Image
class ImageDataset(Dataset):
def __init__(self, data_dir, transform=None, serial_batches=False):
self.serial_batches = serial_batches
self.A_path = os.path.join(data_dir, 'monet')
self.B_path = os.path.join(data_dir, 'photo')
self.A_paths = os.listdir(self.A_path)
self.B_paths = os.listdir(self.B_path)
self.A_size = len(self.A_paths) # get the size of dataset A
self.B_size = len(self.B_paths) # get the size of dataset B
self.transform = transform
def __getitem__(self, index):
"""Return a data point and its metadata information.
Parameters:
index (int) -- a random integer for data indexing
Returns a dictionary that contains A, B, A_paths and B_paths
A (tensor) -- an image in the input domain
B (tensor) -- its corresponding image in the target domain
A_paths (str) -- image paths
B_paths (str) -- image paths
"""
A_path = self.A_paths[index % self.A_size] # make sure index is within then range
if self.serial_batches: # make sure index is within then range
index_B = index % self.B_size
else: # randomize the index for domain B to avoid fixed pairs.
index_B = random.randint(0, self.B_size - 1)
B_path = self.B_paths[index_B]
A_img = Image.open(os.path.join(self.A_path, A_path)).convert('RGB')
B_img = Image.open(os.path.join(self.B_path, B_path)).convert('RGB')
# apply image transformation
A = self.transform(A_img)
B = self.transform(B_img)
return A, B
def __len__(self):
"""Return the total number of images in the dataset.
As we have two datasets with potentially different number of images,
we take a maximum of
"""
return max(self.A_size, self.B_size)
4.2 模型
from torch import nn
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super(ResidualBlock, self).__init__()
self.block = nn.Sequential(
nn.ReflectionPad2d(1), # padding, keep the image size constant after next conv2d
nn.Conv2d(in_channels, in_channels, 3),
nn.InstanceNorm2d(in_channels),
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_channels, in_channels, 3),
nn.InstanceNorm2d(in_channels)
)
def forward(self, x):
return x + self.block(x)
class GeneratorResNet(nn.Module):
def __init__(self, in_channels, num_residual_blocks=9):
super(GeneratorResNet, self).__init__()
# Inital Convolution 3*256*256 -> 64*256*256
out_channels = 64
self.conv = nn.Sequential(
nn.ReflectionPad2d(in_channels), # padding, keep the image size constant after next conv2d
nn.Conv2d(in_channels, out_channels, 2 * in_channels + 1),
nn.InstanceNorm2d(out_channels),
nn.ReLU(inplace=True),
)
channels = out_channels
# Downsampling 64*256*256 -> 128*128*128 -> 256*64*64
self.down = []
for _ in range(2):
out_channels = channels * 2
self.down += [
nn.Conv2d(channels, out_channels, 3, stride=2, padding=1),
nn.InstanceNorm2d(out_channels),
nn.ReLU(inplace=True),
]
channels = out_channels
self.down = nn.Sequential(*self.down)
# Transformation (ResNet) 256*64*64
self.trans = [ResidualBlock(channels) for _ in range(num_residual_blocks)]
self.trans = nn.Sequential(*self.trans)
# Upsampling 256*64*64 -> 128*128*128 -> 64*256*256
self.up = []
for _ in range(2):
out_channels = channels // 2
self.up += [
# nn.Upsample(scale_factor=2), # bilinear interpolation
nn.ConvTranspose2d(channels, out_channels, 3, stride=2, padding=1, output_padding=1),
nn.InstanceNorm2d(out_channels),
nn.ReLU(inplace=True),
]
channels = out_channels
self.up = nn.Sequential(*self.up)
# Out layer 64*256*256 -> 3*256*256
self.out = nn.Sequential(
nn.ReflectionPad2d(in_channels),
nn.Conv2d(channels, in_channels, 2 * in_channels + 1),
nn.Tanh()
)
def forward(self, x):
x = self.conv(x)
x = self.down(x)
x = self.trans(x)
x = self.up(x)
x = self.out(x)
return x
class Discriminator(nn.Module):
def __init__(self, in_channels):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
*self.block(in_channels, 64, normalize=False), # 3*256*256 -> 64*128*128
*self.block(64, 128), # 64*128*128 -> 128*64*64
*self.block(128, 256), # 128*64*64 -> 256*32*32
*self.block(256, 512), # 256*32*32 -> 512*16*16
# padding first then convolution
nn.ZeroPad2d((1, 0, 1, 0)), # padding left and top 512*16*16 -> 512*17*17
nn.Conv2d(512, 1, 4, padding=1) # 512*17*17 -> 1*16*16
)
self.scale_factor = 16
@staticmethod
def block(in_channels, out_channels, normalize=True):
layers = [nn.Conv2d(in_channels, out_channels, 4, stride=2, padding=1)]
if normalize:
layers.append(nn.InstanceNorm2d(out_channels))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
def forward(self, x):
# print(self.model(x).shape)
return self.model(x)
4.3 训练和优化过程
注意在用损失进行前馈运算求导的时候,不能使用loss = loss1+loss2的格式,否则会造成在同一个计算图上两次反向求导。
import itertools
import os.path
import numpy as np
import torch
import argparse
from visdom import Visdom
import torch.nn as nn
from torchvision import transforms
from torch.utils.data import DataLoader
from dataset import ImageDataset
from model import Discriminator, GeneratorResNet
parser = argparse.ArgumentParser(description='PyTorch AutoEncoder Training')
parser.add_argument('--n_epochs', type=int, default=100, help="Epochs to train")
parser.add_argument('--decay_epoch', type=int, default=20)
parser.add_argument('--seed', type=int, default=2022)
parser.add_argument('--batch_size', type=int, default=2)
parser.add_argument('--serial_batches', type=bool, default=False)
parser.add_argument('--dir_path', type=str, default="F:\gan-getting-started")
parser.add_argument('--lr', type=float, default=2e-4)
parser.add_argument('--momentum', type=float, default=0.9)
parser.add_argument('--nesterov', default=True, type=bool, help='nesterov momentum')
parser.add_argument('--weight_decay', default=1e-5, type=float)
parser.add_argument('--lambda_1', type=float, default=10)
parser.add_argument('--lambda_2', type=float, default=5)
parser.add_argument('--checkpoint', default="default", type=str)
parser.add_argument('--mode', type=str, default="train", choices=['train', 'test'])
parser.add_argument('--version', default="default", type=str)
parser.add_argument('--prefetch', type=int, default=0)
parser.set_defaults(augment=True)
args = parser.parse_args()
use_cuda = True
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
print()
print(args)
def get_transform(grayscale=False, method=transforms.InterpolationMode.BICUBIC, convert=True):
transform_list = [transforms.Resize([286, 286], method),
transforms.RandomCrop(256)]
if convert:
transform_list += [transforms.ToTensor()]
if grayscale:
transform_list += [transforms.Normalize((0.5,), (0.5,))]
else:
transform_list += [transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
return transforms.Compose(transform_list)
def build_dataset():
train_set = ImageDataset(data_dir=args.dir_path, transform=get_transform(), serial_batches=args.serial_batches)
train_loader = DataLoader(train_set, batch_size=args.batch_size, num_workers=args.prefetch, pin_memory=True)
return train_loader
def train(G_AB, G_BA, D_B, D_A,
optimizer_G, optimizer_D_A, optimizer_D_B,
criterion_g,
criterion_cycle,
criterion_idt,
train_loader, epoch):
G_AB.train()
G_BA.train()
D_B.train()
D_A.train()
print("Epoch: %d" % (epoch + 1))
for batch_idx, (A, B) in enumerate(train_loader):
out_shape = [A.size(0), 1, A.size(2) // D_A.scale_factor, A.size(3) // D_A.scale_factor]
valid = torch.ones(out_shape).to(device)
fake = torch.zeros(out_shape).to(device)
A, B = A.to(device), B.to(device)
fake_B = G_AB(A)
fake_A = G_BA(B)
cyc_A = G_BA(fake_B)
cyc_B = G_AB(fake_A)
loss_G_AB = criterion_g(D_B(fake_B), valid)
loss_G_BA = criterion_g(D_A(fake_A), valid)
loss_G = loss_G_AB + loss_G_BA
loss_cyc_A = criterion_cycle(cyc_A, A)
loss_cyc_B = criterion_cycle(cyc_B, B)
loss_cyc = loss_cyc_A + loss_cyc_B
loss_idt_A = criterion_idt(G_AB(B), B)
loss_idt_B = criterion_idt(G_BA(A), A)
loss_identity = loss_idt_A + loss_idt_B
loss_GAN = loss_G + args.lambda_1 * loss_cyc + args.lambda_2 * loss_identity
optimizer_G.zero_grad()
loss_GAN.backward()
optimizer_G.step()
optimizer_D_A.zero_grad()
loss_D_A_1 = criterion_g(D_A(A), valid)
loss_D_A_2 = criterion_g(D_A(fake_A.detach()), fake)
loss_D_A = loss_D_A_1 + loss_D_A_2
loss_D_A.backward()
optimizer_D_A.step()
optimizer_D_B.zero_grad()
loss_D_B_1 = criterion_g(D_B(B), valid)
loss_D_B_2 = criterion_g(D_B(fake_B.detach()), fake)
loss_D_B = loss_D_B_1 + loss_D_B_2
loss_D_B.backward()
optimizer_D_B.step()
if (batch_idx + 1) % 10 == 0:
print('Iters: [%d/%d]' % (batch_idx + 1, len(train_loader.dataset) / args.batch_size))
print(f'[G loss: {
loss_GAN.item()} | identity: {
loss_identity.item()} GAN: {
loss_G.item()} cycle: {
loss_cyc.item()}]')
print(f'[D_A: {
loss_D_A.item()} D_B: {
loss_D_B.item()}]\n')
return loss_GAN, loss_G, loss_cyc, loss_identity, loss_D_A, loss_D_B
def to_img(x, imtype=np.uint8):
image_numpy = x.data[0].cpu().float().numpy()
image_numpy = (np.transpose(image_numpy, (1, 2, 0)) + 1) / 2.0 * 255.0
return image_numpy.astype(imtype)
# G_AB(G: A -> B), G_BA(F: B -> A), D_A (D_Y), D_B (D_X)
G_AB = GeneratorResNet(in_channels=3, num_residual_blocks=9).to(device)
G_BA = GeneratorResNet(in_channels=3, num_residual_blocks=9).to(device)
# print(G_BA)
D_B = Discriminator(in_channels=3).to(device)
D_A = Discriminator(in_channels=3).to(device)
optimizer_G = torch.optim.Adam(itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=args.lr)
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=args.lr)
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=args.lr)
lambda_func = lambda epoch: 1 - max(0, epoch - args.decay_epoch) / (args.n_epochs - args.decay_epoch)
lr_scheduler_G = torch.optim.lr_scheduler.LambdaLR(optimizer_G, lr_lambda=lambda_func)
lr_scheduler_D_A = torch.optim.lr_scheduler.LambdaLR(optimizer_D_A, lr_lambda=lambda_func)
lr_scheduler_D_B = torch.optim.lr_scheduler.LambdaLR(optimizer_D_B, lr_lambda=lambda_func)
criterion_GAN = nn.MSELoss()
criterion_cycle = nn.L1Loss()
criterion_identity = nn.L1Loss()
if __name__ == "__main__":
train_loader = build_dataset()
for epoch in range(args.n_epochs):
train(G_AB=G_AB, G_BA=G_BA, D_A=D_A, D_B=D_B,
optimizer_G=optimizer_G, optimizer_D_A=optimizer_D_A, optimizer_D_B=optimizer_D_B,
criterion_g=criterion_GAN, criterion_cycle=criterion_cycle, criterion_idt=criterion_identity,
epoch=epoch, train_loader=train_loader)
if (epoch + 1) % 20 == 0:
if not os.path.exists("./checkpoint"):
os.makedirs("./checkpoint")
torch.save(G_BA.state_dict(), args.version + "_checkpoint.pkl")
lr_scheduler_G.step()
lr_scheduler_D_A.step()
lr_scheduler_D_B.step()
4.4 测试生成图像
import argparse
import os
import numpy as np
import torch
from PIL import Image
from torch import Tensor
from torchvision import transforms
from model import GeneratorResNet
parser = argparse.ArgumentParser(description='PyTorch AutoEncoder Training')
parser.add_argument('--seed', type=int, default=2022)
parser.add_argument('--batch_size', type=int, default=2)
parser.add_argument('--checkpoint', default="default", type=str)
parser.add_argument('--data_dir', type=str, default="F:/gan-getting-started")
parser.set_defaults(augment=True)
args = parser.parse_args()
use_cuda = True
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
G_BA = GeneratorResNet(in_channels=3, num_residual_blocks=9).to(device)
G_BA.load_state_dict(torch.load("checkpoint/" + args.checkpoint + "_checkpoint.pkl"), strict=True)
photo_dir = os.path.join(args.data_dir, 'photo')
files = [os.path.join(photo_dir, name) for name in os.listdir(photo_dir)]
len(files)
save_dir = './images'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
generate_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
to_image = transforms.ToPILImage()
G_BA.eval()
for i in range(0, len(files), args.batch_size):
# read images
imgs = []
for j in range(i, min(len(files), i + args.batch_size)):
img = Image.open(files[j])
img = generate_transforms(img)
imgs.append(img)
imgs = torch.stack(imgs, 0).type(Tensor).to(device)
# generate
fake_imgs = G_BA(imgs).detach().cpu()
# save
for j in range(fake_imgs.size(0)):
img = fake_imgs[j].squeeze()
img_arr = img.numpy()
img_arr = (np.transpose(img_arr, (1, 2, 0)) + 1) / 2.0 * 255.0
img_arr = img_arr.astype(np.uint8)
img = to_image(img_arr)
_, name = os.path.split(files[i + j])
img.save(os.path.join(save_dir, name))
请注意,CycleGAN对您的机器硬件要求较高,因为您必须同时训练四个网络模型。
五、效果展示

