一、背景:
系统日志可用于追踪用户操作轨迹,异常情况下,合理的日志有助于快速排查、定位问题,毫无疑问,打印日志对于系统是很重要的。
当业务规模较小时,大家都倾向于享受日志带来的便利,从而忽略日志带来的潜在的负面影响,缺乏对日志的管控。在JD当前用户量、业务规模下,绝大多数C端系统、甚至B端系统都是高吞吐的,毫无疑问,过大的日志量对系统的性能、磁盘IO有着显著负面影响,赶上大促时,问题尤为突出。日志在为我们提供便利的同时,也无时无刻成为一根刺,时不时刺我们一下。
作为一个共性问题,由于集团暂没推出统一的日志框架,不少团队都会尝试基于log4j、logback 进行轻度的封装,通过跟配置中心联动,增加一些诸如 '动态降级' 的功能、来缓解日志带来的负面影响。降级带来的效果是显著的,但同时也让系统丧失了记录 '操作轨迹' 的能力,从而又带来了新的问题。
此时,很容易想到,可以通过对 '请求' 采样,实现请求日志的采样输出,并通过控制采样比例平衡不同场景下日志对性能的影响,系统吞吐量较大时,降级采样比例,系统吞吐量较低时,提高采样比例。
二、正文:
Ⅰ
在请求入口处,通过一定的采样算法,计算当前请求是否采样,并借助 Java 的 ThreadLocal 机制,可以实现当前请求线程的日志采样。但是,大部分关注日志性能的系统,往往处理逻辑也是复杂的,会有各样的异步运算逻辑,因此,大量的日志不一定来自请求线程,更多的可能来自子线程、线程池线程,甚至嵌套在线程池线程下的线程。
如何将请求线程、子线程、线程池线程统一协调起来,实现 '采样标识' 的跨线程透传,从而确保请求维度采样的一致性,是本文关注的重点,希望可以给大家提供一些思路、并附上我们业务场景下的具体案例。
(1) 可以像 Transmittable Thread Local 一样,通过对线程池类、或者任务类(Runnable、Callable)进行包装,将透传逻辑封装起来,JD内部比较典型的用法有 pfinder、jade。
必须承认,使用这种方式实现是有一定优势的,但是奈何现在各团队都有自己独特功能的线程池包装类,并已经在业务系统中广泛使用,如果此时再增加一个处理 '日志采样' 的包装,会出现嵌套包装的情况,这样会让程序变得混乱,增加理解成本,由于各包装实现之间缺乏磨合,甚至面临不可控的风险,这样做甚至有 '添乱' 的嫌疑,我认为至少在当前的环境下是不可取的。
(2)直接粗暴一些,在业务系统中,涉及子线程、线程池的地方,通过代码 '显式的' 将 '采样标识' 不断透传。
这样做是能达到目的的,但是,会有大量的逻辑代码和业务耦合的情况(线程池越多,业务越复杂,耦合越严重),虽然单系统改造量不大(当然,这个也是因系统而异),但是辐射面太广,需要各业务系统都要配合改造,同时有影响业务逻辑的风险,也不可取。
(3)将请求线程的控制逻辑跟具体业务解耦开来,封装为一个组件,并在组件中提供合适的 api,将组件复用于各业务系统,并根据业务系统具体情况,来决策是否使用 api 来处理异步线程(子线程、线程池线程的统一简称)的情况。
在没有特别合适的、集团级统一api的情况下,这是一种较为务实的做法,通过接入抽象组件来控制请求线程的日志采样,并通过扩展 api 来协调请求线程和异步线程的采样一致性,并根据业务系统的实际情况,来决策是否需要 '修改代码' 来协调异步线程。
① 如果业务系统中使用异步线程的处理逻辑较少,只接入组件,进行请求线程的日志采样即可
② 如果业务系统中大量使用异步线程做逻辑,可接入组件再针对必要的地方通过扩展 api 来协调请求线程和异步线程的采样一致性
除上述外,应该还有其他的办法,比如 AOP 机制,但是 AOP 只能到最低方法粒度,对于存量系统来说,改造量还是偏大,如果是新系统开发,可以考虑。
Ⅱ
最后,上面的思考都是偏向全局的,在具体实现时,需要考虑、斟酌的细节还有很多、下面抛砖引玉列出一些,希望对大家拓展思路有所帮助!
① 采样的算法,是 '随机' 还是 '对 traceId 取模',然后通过配置中心控制取样比例
甚至跟入参关联起来,对特定场景(对哪个接口、方法,按什么规则进行入参筛选)进行采样,即所谓场景化采样
② 扩展 api 应该提供哪些功能,怎么封装能做到让业务应用改动量最少?
③ 怎么保证全局(包括异步线程日志)请求 traceId 的一致性,这方面其实 pfinder 也有方案可供参考
④ 采样比例的最小粒度,是 百分之一、千分之一、还是万分之一?
⑤ 整系统使用一个采样概率(即当前请求命中采样时,各级别都打),还是各级别分别设置(分别设置时还要考虑联动)
⑥ 通常,我们倾向于,如果需要对当前请求进行采样,可能 info、error 一块打,也可能只打 error,但是不太可能只打 info 不打 error,所以需要有一个策略去控制
⑦ 当大量 error 产生时,怎么收敛日志?控制打印速率?甚至可以晋级一步,将磁盘IO 和打印速率联动
三、实践:
促销交易这边目前恰好在做这方面相关的技术改造,通过在目前既存日志组件(通过 JD JSF 前置过滤器实现)基础上,实现请求线程的日志采样,并提供扩展 api 给业务系统,实现整体上请求维度的日志采样,从而尽可能的减少业务系统的改造,以下流程图描述了大致落地过程,供参考,有兴趣的可以评论区留言进一步探讨具体落地细节。
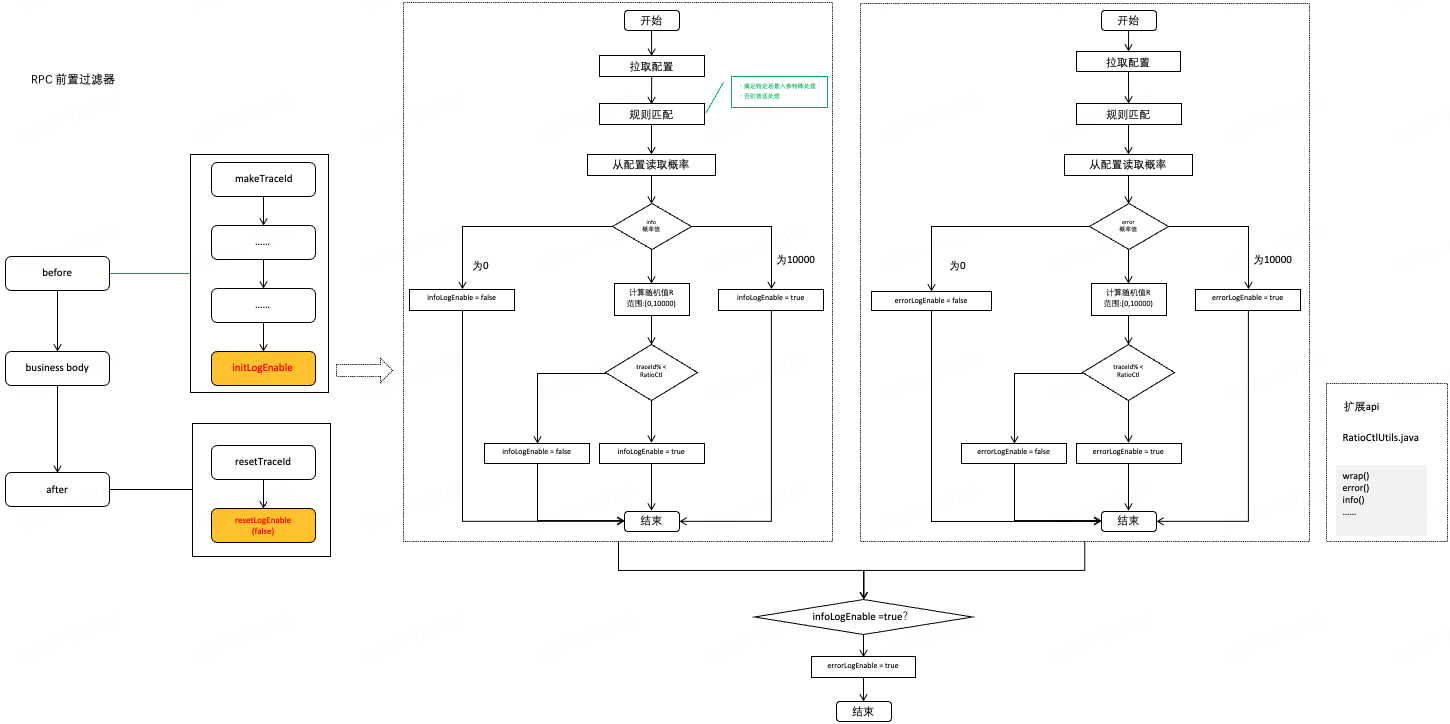
涉及异步线程时,使用扩展 api 改造也相对简洁:
// 改造前,线程池任务执行逻辑
threadPoolExecutor.execute(() -> "your business logic");
// 使用扩展 api 改造后,对 '线程池执行逻辑' 进行包装,实现 '采样标识' 的跨线程透传
threadPoolExecutor.execute(XxxUtils.wrap(() -> "your business logic"));
作者:京东零售 卢吉欣
来源:京东云开发者社区 转载请注明来源
Tauri v2 支持 Android 和 iOS,跨平台开发新选择 FastGateway:一个可以用于代替 Nginx 的网关 PostgreSQL 90% 的新代码仅由 50 人完成,拓数派荣占一席 联想 2024 年将发布全新 AI OS 操作系统 微软为 Windows 11 引入原生 Sudo 命令支持 Redox OS 计划移植更多 Linux 软件 10 年前的今天 —— Vue.js 正式问世 谷歌向 Rust 基金会捐赠 100 万美元,改进 Rust 与 C++ 的互操作性 曾被 Mozilla 放弃的 Web 引擎项目“Servo”在 2024 年迎来重生 Zig 编程语言 2024 年全新路线图发布