首先,深的网路是不会比浅的网络差,如果可以充分训练的话。
链接:https://www.zhihu.com/question/38499534/answer/147150281
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
用一句话解释就是,深度网络容易造成梯度在back propagation的过程中消失,导致训练效果很差,而深度残差网络在神经网络的结构层面解决了这一问题,使得就算网络很深,梯度也不会消失。
关于梯度消失的问题,详见这篇文章
http://blog.csdn.net/superCally/article/details/55671064
我们知道,对于神经网络来讲,我们需要通过反向传播来对网络的权重进行调整
就像这样
但是这个时候,如果网络很深很深,就会出现这样的情况

这个时候再做back propagation求偏导的话,就是
这个偏导就是我们求的gradient,这个值本来就很小,而且再计算的时候还要再乘stepsize,就更小了所以通过这里可以看到,梯度在反向传播过程中的计算,如果N很大,那么梯度值传播到前几层的时候就会越来越小,也就是梯度消失的问题
那DRN是怎样解决这个问题的呢?
它在神经网络结构的层面解决了这个问题它将基本的单元改成了这个样子
 其实也很明显,通过求偏导我们就能看到
其实也很明显,通过求偏导我们就能看到
这样就算深度很深,梯度也不会消失了
当然深度残差这篇文章最后的效果好,是因为还结合了调参数以及神经网络的其他的细节,这些也很重要,不过就不是这里我们关心的内容了可以看到,对于相同的数据集来讲,残差网络比同等深度的其他网络表现出了更好的性能
<img src="https://pic4.zhimg.com/50/v2-543d8c86899ec03d623e054b9d100cdb_hd.jpg" data-rawwidth="600" data-rawheight="370" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic4.zhimg.com/v2-543d8c86899ec03d623e054b9d100cdb_r.jpg">
 <img src="https://pic1.zhimg.com/50/v2-d0293f59397ee7158dfc57eae6f4f477_hd.jpg" data-rawwidth="600" data-rawheight="452" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic1.zhimg.com/v2-d0293f59397ee7158dfc57eae6f4f477_r.jpg">
<img src="https://pic1.zhimg.com/50/v2-d0293f59397ee7158dfc57eae6f4f477_hd.jpg" data-rawwidth="600" data-rawheight="452" class="origin_image zh-lightbox-thumb" width="600" data-original="https://pic1.zhimg.com/v2-d0293f59397ee7158dfc57eae6f4f477_r.jpg">
resnet在2015名声大噪,而且影响了2016年DL在学术界和工业界的发展方向。下面是这个resnet的网络结构,大家先睹为快。

它对每层的输入做一个reference, 学习形成残差函数, 而不是学习一些没有reference的函数。这种残差函数更容易优化,能使网络层数大大加深。
我们知道,在计算机视觉里,特征的“等级”随增网络深度的加深而变高,研究表明,网络的深度是实现好的效果的重要因素。然而梯度弥散/爆炸成为训练深层次的网络的障碍,导致无法收敛。
有一些方法可以弥补,如归一初始化,各层输入归一化,使得可以收敛的网络的深度提升为原来的十倍。然而,虽然收敛了,但网络却开始退化了,即增加网络层数却导致更大的误差, 如下图。 这种deep plain net收敛率十分低下。
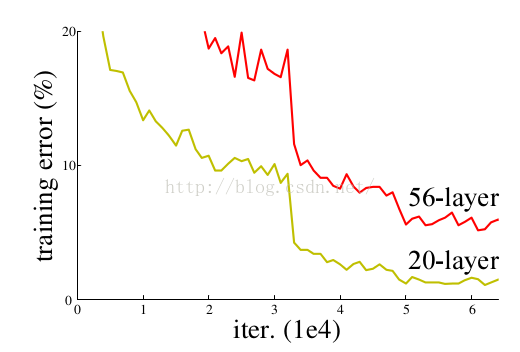
的确,通过在一个浅层网络基础上叠加y=x的层(称identity mappings,恒等映射),可以让网络随深度增加而不退化。这反映了多层非线性网络无法逼近恒等映射网络。
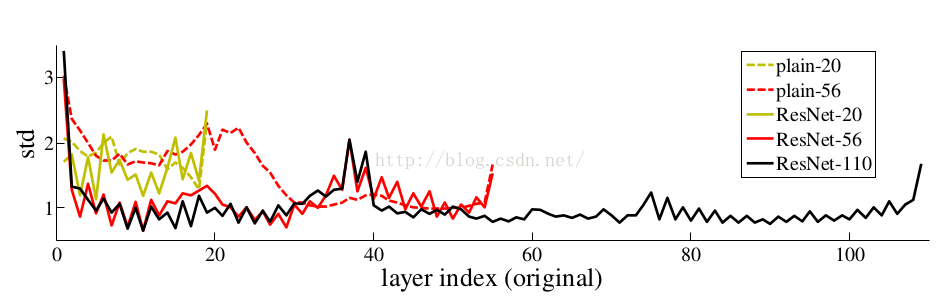
但是,不退化不是我们的目的,我们希望有更好性能的网络。 resnet学习的是残差函数F(x) = H(x) - x, 这里如果F(x) = 0, 那么就是上面提到的恒等映射。事实上,resnet是“shortcut connections”的在connections是在恒等映射下的特殊情况,它没有引入额外的参数和计算复杂度。 假如优化目标函数是逼近一个恒等映射, 而不是0映射, 那么学习找到对恒等映射的扰动会比重新学习一个映射函数要容易。从下图可以看出,残差函数一般会有较小的响应波动,表明恒等映射是一个合理的预处理。
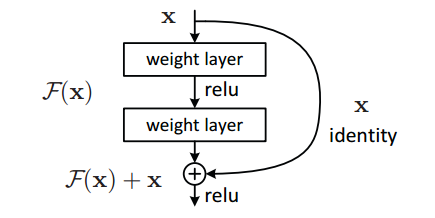
残差块的结构如下图,
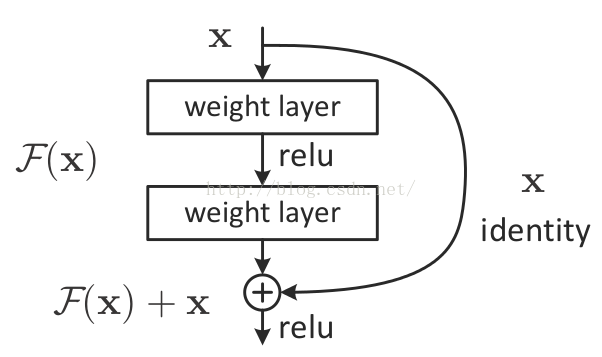
它有二层,如下表达式,其中σ代表非线性函数ReLU
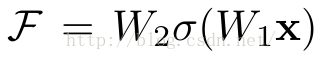
然后通过一个shortcut,和第2个ReLU,获得输出y
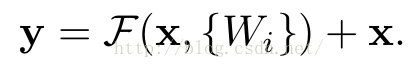
当需要对输入和输出维数进行变化时(如改变通道数目),可以在shortcut时对x做一个线性变换Ws,如下式,然而实验证明x已经足够了,不需要再搞个维度变换,除非需求是某个特定维度的输出,如文章开头的resnet网络结构图中的虚线,是将通道数翻倍。
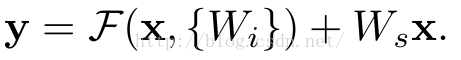
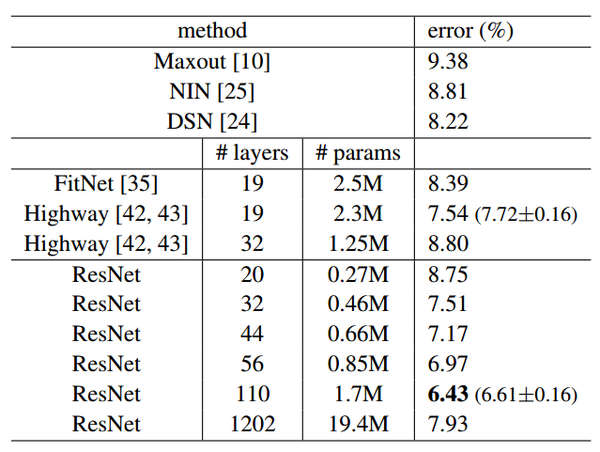
实验证明,这个残差块往往需要两层以上,单单一层的残差块(y=W1x+x)并不能起到提升作用。
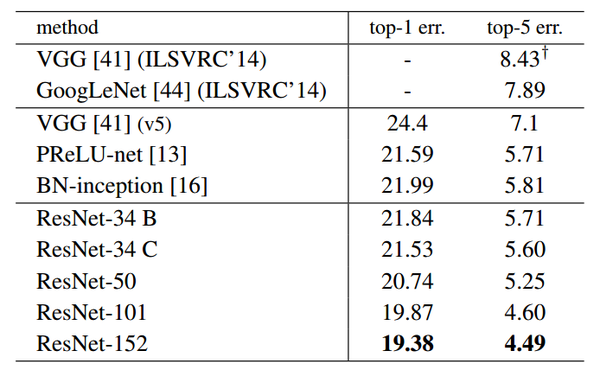
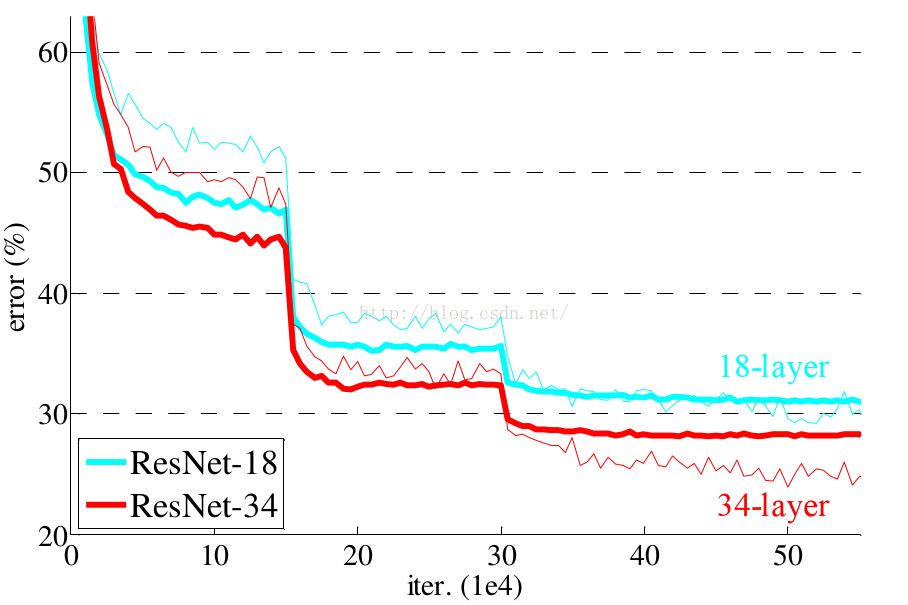
残差网络的确解决了退化的问题,在训练集和校验集上,都证明了的更深的网络错误率越小,如下图
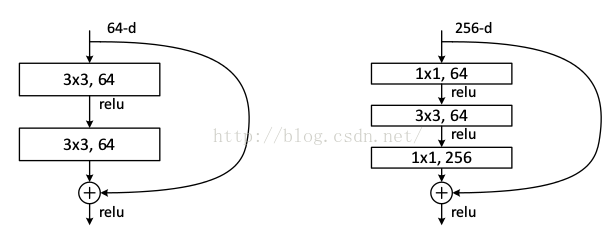
实际中,考虑计算的成本,对残差块做了计算优化,即将两个3x3的卷积层替换为1x1 + 3x3 + 1x1, 如下图。新结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原,既保持了精度又减少了计算量。
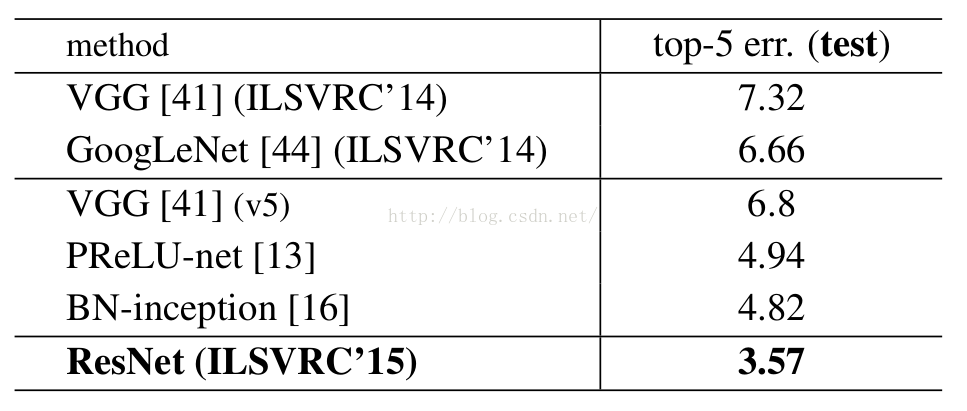
下面是resnet的成绩单, 在imagenet2015夺得冠军