MapReduce分为Map和Reduce,Map主要作用是做映射,Reduce是做规约。
一、MapReduce 1.x
MR1是hadoop1.x中作为计算和资源调度使用,含有
- JobTracke
- TaskTracke 作为计算
- map task
- reduce task
二、MapReduce 2.x
MR2是hadoop 2.x 上的只做计算,而资源调度使用Yarn去做,这样可以加载更多的计算框架,不只是MR。下面这个图,表示MR流程:
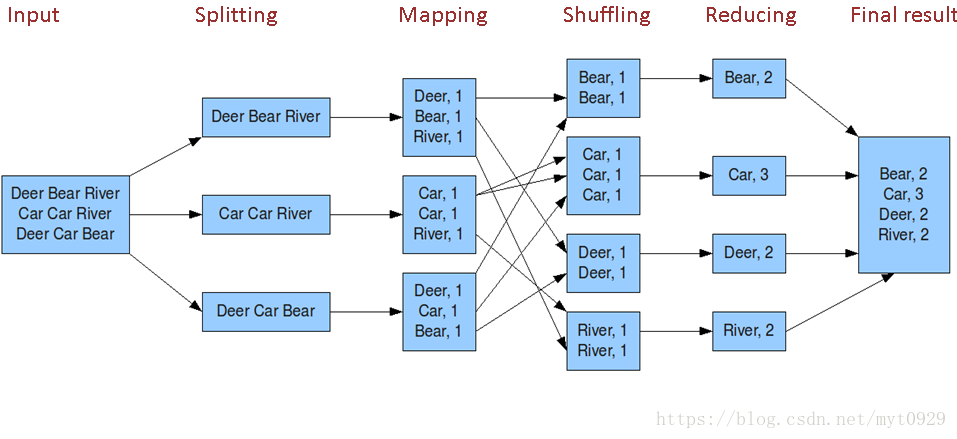
2.1 Input
MR2通过运行时的配置要读取哪些文件,从而后面的分片做配置,MR2运行在Yarn上,Yarn会根据资源的情况,将任务优先派发到块所在节点上。
2.2 Splitting
分片。在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务,所以关系到Map任务数,分片至关重要。输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组,输入分片(input split)往往和hdfs的block(块)关系很密切,假如我们设定hdfs的块的大小是64mb,如果我们输入有三个文件,大小分别是3mb、65mb和127mb,那么mapreduce会把3mb文件分为一个输入分片(input split),65mb则是两个输入分片(input split)而127mb也是两个输入分片(input split),换句话说我们如果在map计算前做输入分片调整,例如合并小文件。这个例子中就会有5个map任务将执行,而且每个map执行的数据大小不均,这个也是mapreduce优化计算的一个关键点。这不是绝对这么分的。
2.3 Mapping
映射。简单的说,我们拿到这些切分的数据初始化value,这些value之后用来干嘛。在Wordcount中,就初始化1,为之后累加做赋值。mapred-default.xml中的mapreduce.job.maps设置一个job默认启动的map数,但是实际设置没什么意义。
2.4 Shuffling
洗牌。Shuffling是在Reduce任务中的,他的作用就是把之前Map生成的混乱数据进行清洗,就是洗牌。将key相同的放在一起(通过hash做)。为方便后面Reduce做好铺垫。
2.5 Reducing
规约。就是拿到相同的keyvalue对,干甚么用。在Wordcount中,就是累加。一般生产上reduce数量在3-5个。mapred-default.xml中的mapreduce.job.reduces 这个参数设置默认数量,当然提交任务时候指定(推荐)也是可以的。
2.6 Final
输出。有多少个Reduce,就有多少个文件。
三、MapReduce 1.x 架构设计
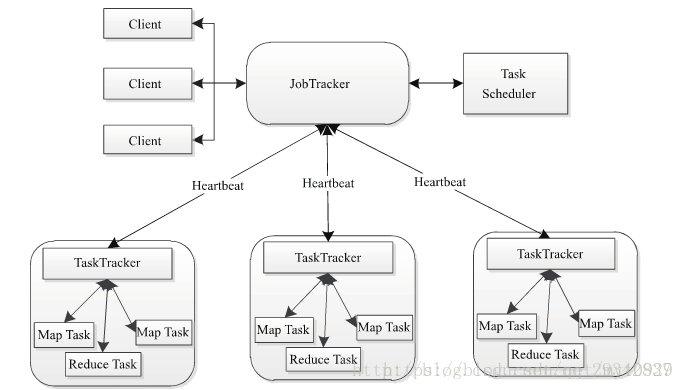
MR1也是典型的主从架构,JobTracker即做资源的管理还要配合TaskSchedule做任务的调度。
资源管理:
- 有多少节点
- 各个节点的cpu资源,内存资源
任务管理:
- 多少任务
- 任务分配方式
- 任性执行情况
三、MapReduce 2.x 架构设计
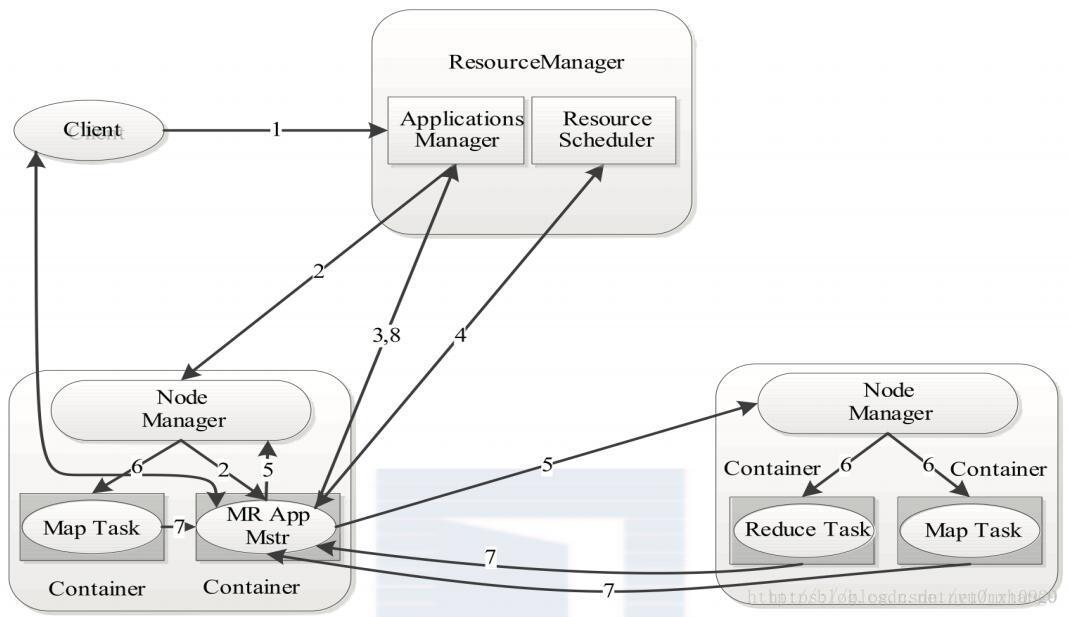
MR2是跑在Yarn上面,所以MR2的架构其实就是Yarn架构设计。
- Client
- ResourceManager节点,包含ApplicationManager(应用任务管理器)和 ResourceSchediler(资源调度器)
- NodeManager节点,包含Container(运行任务容器)
- Client 提交作业job(或者称之应用)到ResourceManager节点中的ApplicationManager。
- ApplicationManager 会通知一个 Nodemanger申请一个Container 容器来启动该应用(APP)的ApplicationMaster。
- 启动好的ApplicationMaster向ApplicationManager 注册,这样就能在web上查看运行状态。
- ApplicationMaster注册好后通过RPC向ResourceScheduler资源调度器申请和领取资源。
- 获取到资源后,ApplicationMaster就向资源所在节点通讯,要求NodeManager启动任务。
- NodeManger为任务设置好容器,该容器拥有启动该任务所需要的jar包、环境变量、运行脚本等。(这里的任务就是MR2中的MapTask、ReduceTask)
- 任务定时向ApplicationMaster汇报任务运行状态,从而让ApplicationMaster在得知任务失败后再去重启或者重开一个任务。
- 整个作业完成后,ApplicationMaster会向ApplicationManager 申请关闭和注销作业。
四、ResourceManager节点
4.1 ApplicationManager 应用程序管理器
任务管理器,用于管理任务,启动、注销任务等。
4.2 ResourceSchediler 资源管理器
资源的调度掐,用于调度节点资源、计算资源、内存资源等等。常见的调度器有:先进先出调度器、计算调度器、公平调度器等。
五、NodeManager节点
5.1 Container 容器
Container容器是用来运行job的小房间,这个小房间独享自己的资源。生产上Container容器一般占用一台物理机的内存和cpu核数的75%-85%之间。
NodeManager上配置Container参数
1、yarn.nodemanager.resource.memory-mb
告诉yarn可用这台物理机上多少资源 一般 = 实际内存*0.8
2、yarn.scheduler.minimum-allocation-mb
一个容器最小能使用内存 生产上一般设置1G,
涉及到任务所需要的内存大于容器能提供的内存,作业可能会挂。
3、yarn.scheduler.maximum-allocation-mb
一个容器最大能使用内存 涉及到你想要容器的数量(并行度,实现性) 生产上16G
4、yarn.scheduler.minimum-allocation-vcores
同理虚拟的核数,虚拟的核数是物理核数*2
5、yarn.scheduler.maximum-allocation-vcores
同理虚拟的核数六、Yarn资源调度器
调度器的意思就是ResourceManager将某个NodeManager上的资源分配给任务,保证资源的独占性。
6.1 先进先出调度器(FIFO)
该调度器是最简单,不需要任何的配置,FIFO吧应用按提交的先后顺序排成队列,先来得先分配资源,待应用需求满足后再给下一个分配。不适用共享计算集群。
6.2 计算调度器(CapacityScheduler)
该调度器有队列,不同队列会占有一定的独立的集群资源。不同任务来,会分配到不同队列中,相互独立。
6.3 公平调度器(FairScheduler)
该调度器不像计算调度器那样占着资源。这个意思是,在某个任务正在运行后如果释放一小部分资源,则这部分会被下一个任务使用,从而不会被浪费。