转自:https://www.cnblogs.com/edisonchou/p/4287784.html



1.3 MapReduce工作机制
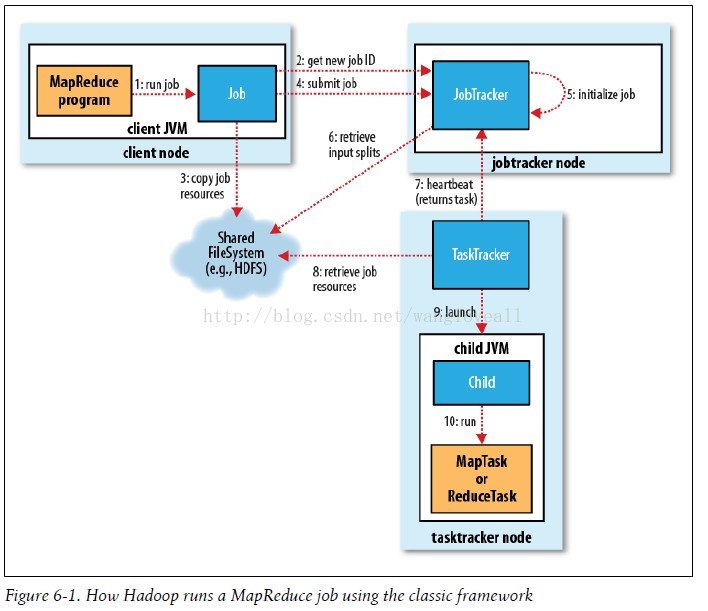
MapReduce的整个工作过程如上图所示,它包含如下4个独立的实体:
实体一:客户端,用来提交MapReduce作业。
实体二:JobTracker,用来协调作业的运行。
实体三:TaskTracker,用来处理作业划分后的任务。
实体四:HDFS,用来在其它实体间共享作业文件。
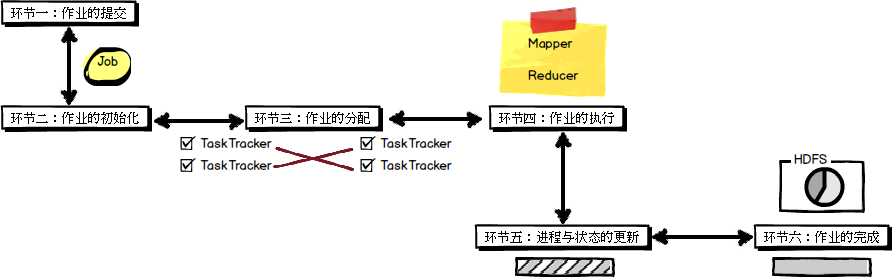
通过审阅MapReduce的工作流程图,可以看出MapReduce整个工作过程有序地包含如下工作环节:
二、Hadoop中的MapReduce框架
在Hadoop中,一个MapReduce作业通常会把输入的数据集切分为若干独立的数据块,由Map任务以完全并行的方式去处理它们。框架会对Map的输出先进行排序,然后把结果输入给Reduce任务。通常作业的输入和输出都会被存储在文件系统中,整个框架负责任务的调度和监控,以及重新执行已经关闭的任务。
通常,MapReduce框架和分布式文件系统是运行在一组相同的节点上,也就是说,计算节点和存储节点通常都是在一起的。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使得整个集群的网络带宽被非常高效地利用。
2.1 MapReduce框架的组成

(1)JobTracker
JobTracker负责调度构成一个作业的所有任务,这些任务分布在不同的TaskTracker上(由上图的JobTracker可以看到2 assign map 和 3 assign reduce)。你可以将其理解为公司的项目经理,项目经理接受项目需求,并划分具体的任务给下面的开发工程师。
(2)TaskTracker
TaskTracker负责执行由JobTracker指派的任务,这里我们就可以将其理解为开发工程师,完成项目经理安排的开发任务即可。
2.2 MapReduce的输入输出
MapReduce框架运转在<key,value>键值对上,也就是说,框架把作业的输入看成是一组<key,value>键值对,同样也产生一组<key,value>键值对作为作业的输出,这两组键值对有可能是不同的。
一个MapReduce作业的输入和输出类型如下图所示:可以看出在整个流程中,会有三组<key,value>键值对类型的存在。

2.3 MapReduce的处理流程
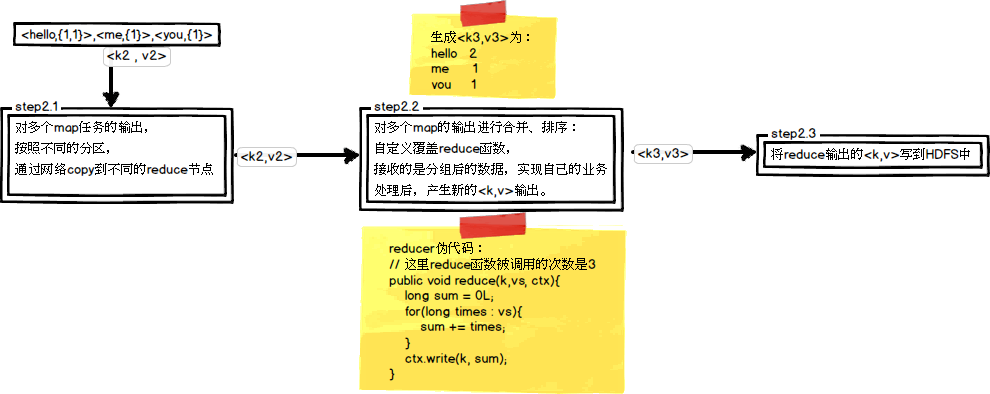
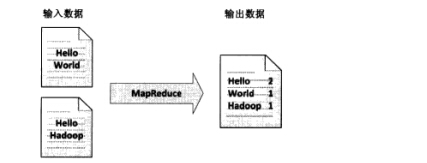
这里以WordCount单词计数为例,介绍map和reduce两个阶段需要进行哪些处理。单词计数主要完成的功能是:统计一系列文本文件中每个单词出现的次数,如图所示:
(1)map任务处理
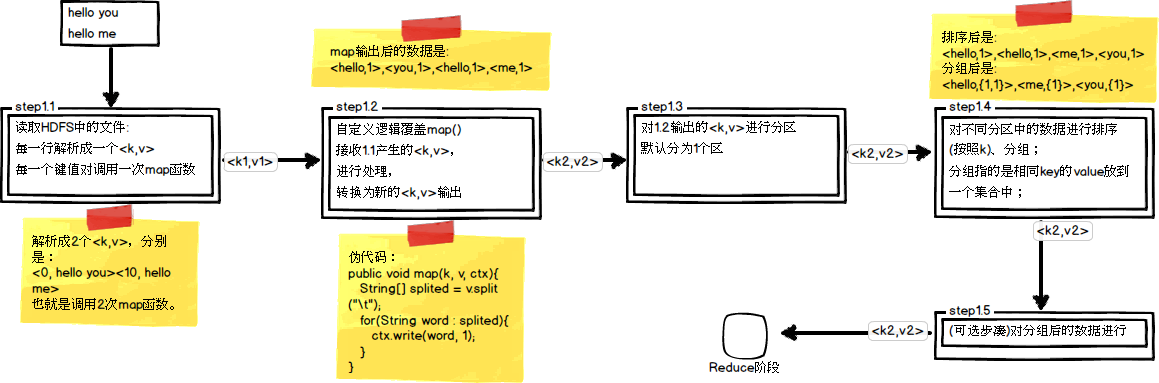
(2)reduce任务处理