参考:http://keras-cn.readthedocs.io/en/latest/
一、Keras简介
Keras是一个高层神经网络API,Keras由纯Python编写而成并基Tensorflow、Theano以及CNTK后端。Keras 为支持快速实验而生,能够把你的idea迅速转换为结果。
Keras适用的Python版本是:Python 2.7-3.6
Keras的核心数据结构是“模型”,模型是一种组织网络层的方式。Keras中主要的模型是Sequential模型,Sequential是一系列网络层按顺序构成的栈。另一种是函数式模型。
keras:符号式,类似于管道搭建供水系统,拼水管时没有水,所有管子都接完才能送水。Keras的模型搭建形式就是这种方法,在你搭建Keras模型完毕后,你的模型就是一个空壳子,只有实际生成可调用的函数后(K.function),输入数据,才会形成真正的数据流。
二、模型
1、序贯Sequential模型
(1)序贯模型是多个网络层的线性堆叠,也就是“一条路走到黑”。可以通过向Sequential模型传递一个layer的list来构造该模型:
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([
Dense(32, units=784),
Activation('relu'),
Dense(10),
Activation('softmax'),
])
也可以通过.add()方法一个个的将layer加入模型中:
model = Sequential()
model.add(Dense(32, input_shape=(784,)))
model.add(Activation('relu'))(2)模型属性:model.layers是添加到模型上的层的list
(3)Sequential模型方法:
add、pop、compile、fit、evaluate、predict、train_on_batch、predict_on_batch
fit_generator、evaluate_on_batch、predict_on_batch
2、函数式模型
(1)Keras函数式模型接口是用户定义多输出模型、非循环有向模型或具有共享层的模型等复杂模型的途径。只要模型不是类似VGG一样一条路走到黑的模型,或者模型需要多于一个的输出,那么应该选择函数式模型。函数式模型是最广泛的一类模型,序贯模型(Sequential)只是它的一种特殊情况。
from keras.models import Model
from keras.layers import Input, Dense
a = Input(shape=(32,))
b = Dense(32)(a)
model = Model(inputs=a, outputs=b)
在这里,我们的模型以a为输入,以b为输出,同样我们可以构造拥有多输入和多输出的模型
model = Model(inputs=[a1, a2], outputs=[b1, b3, b3])(2)模型属性:
model.layers:组成模型图的各个层model.inputs:模型的输入张量列表model.outputs:模型的输出张量列表
(3)函数式模型方法
compile、fit、evaluate、predict、train_on_batch、test_on_batch、predict_on_batch、
fit_generator、evaluate_on_batch、predict_on_batch
三、层
1、常用层Core
(1)全连接层
keras.layers.core.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
(2)激活层
keras.layers.core.Activation(activation)
(3)Dropout层
keras.layers.core.Dropout(rate, noise_shape=None, seed=None)
(4)Flatten层
keras.layers.core.Flatten()
(5)Reshape层
keras.layers.core.Reshape(target_shape)
(6)Permute层:将维度交换
keras.layers.core.Permute(dims)
(7)RepeatVector层:将输入重复N次
keras.layers.core.RepeatVector(n)
(8)Lambda层:对上一层输出进行任何表达式
keras.layers.core.Lambda(function, output_shape=None, mask=None, arguments=None)
(9)ActivityRegularizer:更新损失函数
keras.layers.core.ActivityRegularization(l1=0.0, l2=0.0)
(10)Masking层:信号屏蔽
keras.layers.core.Masking(mask_value=0.0)
2、卷积层
keras.layers.convolutional.Conv1D(filters, kernel_size, strides=1, padding='valid', dilation_rate=1, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
3、池化层
keras.layers.pooling.MaxPooling1D(pool_size=2, strides=None, padding='valid')
keras.layers.pooling.GlobalAveragePooling1D()
4、局部连接层
keras.layers.local.LocallyConnected1D(filters, kernel_size, strides=1, padding='valid', data_format=None, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
5、循环层
keras.layers.recurrent.Recurrent(return_sequences=False, go_backwards=False, stateful=False, unroll=False, implementation=0)
6、嵌入层
keras.layers.embeddings.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)
7、融合层
8、规范层
keras.layers.normalization.BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True, beta_initializer='zeros', gamma_initializer='ones', moving_mean_initializer='zeros', moving_variance_initializer='ones', beta_regularizer=None, gamma_regularizer=None, beta_constraint=None, gamma_constraint=None)
9、噪声层
keras.layers.noise.GaussianNoise(stddev)
四、数据预处理
1、序列预处理
(1)填充序列
keras.preprocessing.sequence.pad_sequences(sequences, maxlen=None, dtype='int32', padding='pre', truncating='pre', value=0.)
(2)跳字
keras.preprocessing.sequence.skipgrams(sequence, vocabulary_size, window_size=4, negative_samples=1., shuffle=True, categorical=False, sampling_table=None)
(3)获取采样表
keras.preprocessing.sequence.make_sampling_table(size, sampling_factor=1e-5)
2、文本预处理
(1)句子分割
keras.preprocessing.text.text_to_word_sequence(text, filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~\t\n', lower=True, split=" ")
(2)one-hot编码
keras.preprocessing.text.one_hot(text, n, filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~\t\n', lower=True, split=" ")
(3)特征哈希
keras.preprocessing.text.hashing_trick(text, n, hash_function=None, filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~\t\n', lower=True, split=' ')
(4)分词器
keras.preprocessing.text.Tokenizer(num_words=None, filters='!"#$%&()*+,-./:;<=>?@[\]^_`{|}~\t\n', lower=True, split=" ", char_level=False)
3、图片预处理:图片生成器
五、图片
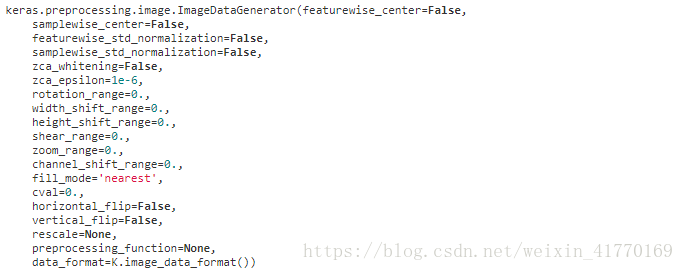
六、网络配置
1、目标函数:损失函数
model.compile(loss='mean_squared_error', optimizer='sgd')
可用的目标函数:
mean_squared_error或mse
mean_absolute_error或mae
mean_absolute_percentage_error或mape
mean_squared_logarithmic_error或msle
squared_hinge
hinge
categorical_hinge
binary_crossentropy(亦称作对数损失,logloss)
logcosh
categorical_crossentropy:亦称作多类的对数损失,注意使用该目标函数时,需要将标签转化为形如
(nb_samples, nb_classes)的二值序列sparse_categorical_crossentrop:如上,但接受稀疏标签。注意,使用该函数时仍然需要你的标签与输出值的维度相同,你可能需要在标签数据上增加一个维度:
np.expand_dims(y,-1)kullback_leibler_divergence:从预测值概率分布Q到真值概率分布P的信息增益,用以度量两个分布的差异.
poisson:即
(predictions - targets * log(predictions))的均值cosine_proximity:即预测值与真实标签的余弦距离平均值的相反数
2、优化器optimizer
model.compile(loss='mean_squared_error', optimizer='sgd')
可用的优化器有:SGD、RMSprop、Adagrad、Adadelta、Adam、Adamax、NAdam、TFOptimizer
3、激活函数Acitivation
激活函数可以通过设置单独的激活层实现,也可以在构造层对象时通过传递activation参数实现。
from keras.layers import Activation, Dense
model.add(Dense(64))
model.add(Activation('tanh'))
等价于
model.add(Dense(64, activation='tanh'))(1)预定义激活函数
softmax:对输入数据的最后一维进行softmax,输入数据应形如
(nb_samples, nb_timesteps, nb_dims)或(nb_samples,nb_dims)elu
selu: 可伸缩的指数线性单元(Scaled Exponential Linear Unit),参考Self-Normalizing Neural Networks
softplus
softsign
relu
tanh
sigmoid
hard_sigmoid
linear
含有可学习参数的激活函数,可通过高级激活函数实现,如PReLU,LeakyReLU等
4、性能评估
性能评估函数类似与目标函数, 只不过该性能的评估结果讲不会用于训练.
model.compile(loss='mean_squared_error', optimizer='sgd', metrics=['mae', 'acc'])
可用的预定义张量:
- binary_accuracy: 对二分类问题,计算在所有预测值上的平均正确率
- categorical_accuracy:对多分类问题,计算再所有预测值上的平均正确率
- sparse_categorical_accuracy:与
categorical_accuracy相同,在对稀疏的目标值预测时有用 - top_k_categorical_accracy: 计算top-k正确率,当预测值的前k个值中存在目标类别即认为预测正确
- sparse_top_k_categorical_accuracy:与top_k_categorical_accracy作用相同,但适用于稀疏情况
5、初始化方法
不同的层可能使用不同的关键字来传递初始化方法,一般来说指定初始化方法的关键字是kernel_initializer 和 bias_initializer,例如:
model.add(Dense(64,
kernel_initializer='random_uniform',
bias_initializer='zeros'))预定义初始化方法:
Zeros、Ones、Constant、RandomNormal、RandomUniform、TruncatedNormal、VarianceScaling
Orthogonal、Identity、lecun_normal、glorot_normal、glorot_uniform、he_normal、he_uniform
6、正则项
正则项在优化过程中层的参数或层的激活值添加惩罚项,这些惩罚项将与损失函数一起作为网络的最终优化目标
惩罚项基于层进行惩罚,目前惩罚项的接口与层有关,但Dense, Conv1D, Conv2D, Conv3D具有共同的接口。
这些层有三个关键字参数以施加正则项:
kernel_regularizer:施加在权重上的正则项,为keras.regularizer.Regularizer对象bias_regularizer:施加在偏置向量上的正则项,为keras.regularizer.Regularizer对象activity_regularizer:施加在输出上的正则项,为keras.regularizer.Regularizer对象
可用的正则项:
keras.regularizers.l1(0.)
keras.regularizers.l2(0.)
keras.regularizers.l1_l2(0.)
7、约束项
Dense, Conv1D, Conv2D, Conv3D这些层通过一下关键字施加约束项:
kernel_constraint:对主权重矩阵进行约束bias_constraint:对偏置向量进行约束
8、回调函数keras.callbacks.*
回调函数是一组在训练的特定阶段被调用的函数集,你可以使用回调函数来观察训练过程中网络内部的状态和统计信息。
Callback、BaseLogger、ProgbarLogger、Histroy、ModelCheckPoint、EarlyStopping、RemoteMonitor
LearningRateScheduler、TensorBoard、ReduceLROnPlateau、CSVLogger、LambdaCallback
七、已有模型、数据库、可视化
1、已有模型
Kera的应用模块Application提供了带有预训练权重的Keras模型,这些模型可以用来进行预测、特征提取和finetune
模型的预训练权重将下载到~/.keras/models/并在载入模型时自动载入
Xception、VGG16、VGG19、ResNet50、InceptionV3、InceptionResNetV2、MobileNet
2、数据库
CIFAR10、CIFAR100、IMDB影评、路透社新闻主题分类、MNIST手写数字识别、Fashion-MNIST数据集
Boston房屋价格回归数据集
3、模型可视化
keras.utils.vis_utils模块提供了画出Keras模型的函数(利用graphviz)
该函数将画出模型结构图,并保存成图片:
from keras.utils import plot_model
plot_model(model, to_file='model.png')八、工具
提供了一系列有用的utils工具