【中英】【吴恩达课后测验】Course 4 -卷积神经网络 - 第四周测验 - 特殊应用:人脸识别和神经风格转换
1.面部验证只需要将新图片与
个人的面部进行比较,而面部识别则需要将新图片与
个人的面部进行比较。
【★】正确
【 】错误
2.在人脸验证中函数
起什么作用?
【★】只需要给出一个人的图片就可以让网络认识这个人。
【★】为了解决一次学习的问题。
【 】这可以让我们使用softmax函数来学习预测一个人的身份,在这个单元中分类的数量等于数据库中的人的数量加1。
Softmax output unit has been removed.
Softmax 输出单元在这里已经被去掉了。
【 】鉴于我们拥有的照片很少,我们需要将它运用到迁移学习中。
We don’t need to use transfer learning.
我们不需要使用迁移学习。
3.为了训练人脸识别系统的参数,使用包含了10万个不同的人的10万张图片的数据集进行训练是合理的。
【 】正确
【★】错误
More than one pictures per person are needed.
每个人需要多张照片的。
4.下面哪个是三元组损失的正确定义(请把
也考虑进去)?
【★】
【 】
【 】
【 】
5.在下图中的孪生卷积网络(Siamese network)结构图中,上下两个神经网络拥有不同的输入图像,但是其中的网络参数是完全相同的。
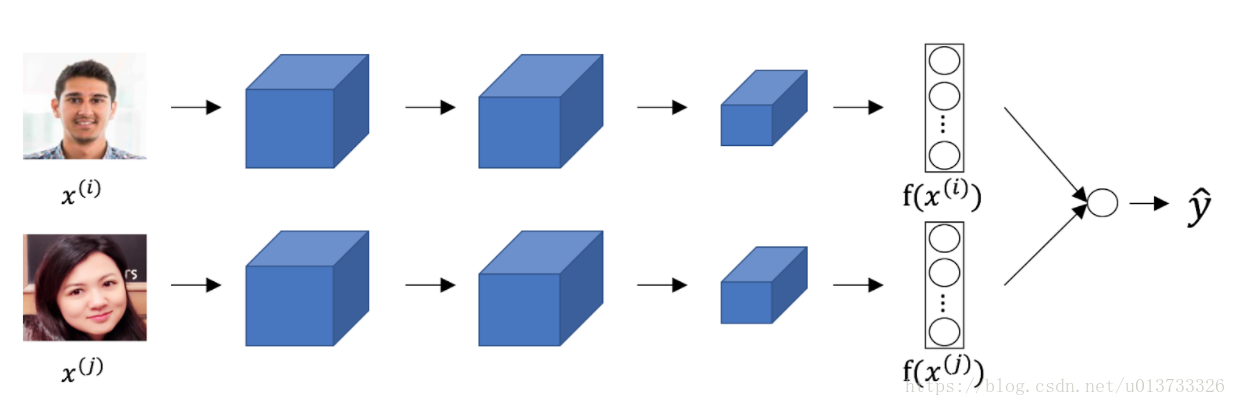
【★】正确
【 】错误
Wee need the same parameters to get
我们需要相同的参数来获得 。
6.你在一个拥有100种不同的分类的数据集上训练一个卷积神经网络,你想要知道是否能够找到一个对猫的图片很敏感的隐藏节点(即在能够强烈激活该节点的图像大多数都是猫的图片的节点),你更有可能在第4层找到该节点而不是在第1层更有可能找到。
【★】正确
【 】错误
7.神经风格转换被训练为有监督的学习任务,其中的目标是输入两个图像 (
),并训练一个能够输出一个新的合成图像(
)的网络。
【 】正确
【★】错误
Images have no labels.
监督学习需要标签,但是这里的图像没有标签。
8.在一个卷积网络的深层,每个通道对应一个不同的特征检测器,风格矩阵
度量了
层中不同的特征探测器的激活(或相关)程度。
【★】正确
【 】错误
9.在神经风格转换中,在优化算法的每次迭代中更新的是什么?
【 】神经网络的参数
【★】生成图像
的像素值
【 】正则化参数
【 】内容图像 的像素值
10.你现在用拥有的是3D的数据,现在构建一个网络层,其输入的卷积是
(此卷积有16个通道),对其使用
个
的过滤器(无填充,步伐为1)进行卷积操作,请问输出的卷积是多少?
【★】
【 】不能操作,因为指定的维度不匹配,所以这个卷积步骤是不可能执行的。
【 】
博主注:本节英文来源于github.com,以下是原作者在文中注的的CSDN指向连接:
Please refer to https://blog.csdn.net/koala_tree/article/details/78647528 for further information.
Special applications: Face recognition & Neural style transfer
Quiz, 10 questions
1. Question 1
Face verification requires comparing a new picture against one person’s face, whereas face recognition requires comparing a new picture against K person’s faces.
[x] True
[ ] False
2. Question 2
Why do we learn a function for face verification? (Select all that apply.)
[x] This allows us to learn to recognize a new person given just a single image of that person.
[x] We need to solve a one-shot learning problem.
[ ] This allows us to learn to predict a person’s identity using a softmax output unit, where the number of classes equals the number of persons in the database plus 1 (for the final “not in database” class).
Softmax output unit has been removed.
- [ ] Given how few images we have per person, we need to apply transfer learning.
We don’t need to use transfer learning.
3. Question 3
In order to train the parameters of a face recognition system, it would be reasonable to use a training set comprising 100,000 pictures of 100,000 different persons.
[ ] True
[x] False
More than one pictures per person are needed.
4. Question 4
Which of the following is a correct definition of the triplet loss? Consider that . (We encourage you to figure out the answer from first principles, rather than just refer to the lecture.)
[x]
[ ]
[ ]
[ ]
5
. Question 5
Consider the following Siamese network architecture:
The upper and lower neural networks have different input images, but have exactly the same parameters.
[x] True
[ ] False
Wee need the same parameters to get
6. Question 6
You train a ConvNet on a dataset with 100 different classes. You wonder if you can find a hidden unit which responds strongly to pictures of cats. (I.e., a neuron so that, of all the input/training images that strongly activate that neuron, the majority are cat pictures.) You are more likely to find this unit in layer 4 of the network than in layer 1.
[x] True
[ ] False
7. Question 7
Neural style transfer is trained as a supervised learning task in which the goal is to input two images ( ), and train a network to output a new, synthesized image ( ).
[ ] True
[x] False
Images have no labels.
8. Question 8
In the deeper layers of a ConvNet, each channel corresponds to a different feature detector. The style matrix measures the degree to which the activations of different feature detectors in layer vary (or correlate) together with each other.
[x] True
[ ] False
9. Question 9
In neural style transfer, what is updated in each iteration of the optimization algorithm?
[ ] The neural network parameters
[x] The pixel values of the generated image
[ ] The regularization parameters
[ ] The pixel values of the content image
10. Question 10
You are working with 3D data. You are building a network layer whose input volume has size 32x32x32x16 (this volume has 16 channels), and applies convolutions with 32 filters of dimension 3x3x3 (no padding, stride 1). What is the resulting output volume?
[x] 30x30x30x32
[ ] Undefined: This convolution step is impossible and cannot be performed because the dimensions specified don’t match up.
[ ] 30x30x30x16
Please refer to https://blog.csdn.net/koala_tree/article/details/78647528 for further information.