下面是HashMap的一个构造函数,两个参数initialCapacity,loadFactor
1. initialCapacity是map的初始化容量,initialCapacity > MAXIMUM_CAPACITY,表明map的最大容量是1<<30,也就是1左移30位,每左移一位乘以2,所以就是1*2^30=1073741824.
2. loadFactor是map的负载因子,loadFactor <= 0 || Float.isNaN(loadFactor),表明负载因子要大于0,且是非无穷大的数字
负载因子为什么会影响HashMap性能
首先回忆HashMap的数据结构,
我们都知道有序数组存储数据,对数据的索引效率都很高,但是插入和删除就会有性能瓶颈(回忆ArrayList),
链表存储数据,要一次比较元素来检索出数据,所以索引效率低,但是插入和删除效率高(回忆LinkedList),
两者取长补短就产生了哈希散列这种存储方式,也就是HashMap的存储逻辑.
而负载因子表示一个散列表的空间的使用程度,有这样一个公式:initailCapacity*loadFactor=HashMap的容量。
所以负载因子越大则散列表的装填程度越高,也就是能容纳更多的元素,元素多了,链表大了,所以此时索引效率就会降低。
反之,负载因子越小则链表中的数据量就越稀疏,此时会对空间造成烂费,但是此时索引效率高。
如何科学设置 initailCapacity,loadFactor的值
HashMap有三个构造函数,可以选用无参构造函数,不进行设置。默认值分别是16和0.75.
官方的建议是initailCapacity设置成2的n次幂,laodFactor根据业务需求,如果迭代性能不是很重要,可以设置大一下。
为什么initailCapacity要设置成2的n次幂,网友解释了,我觉得很对,以下摘自网友博客:深入理解HashMap
左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定
位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以
发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能
存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
这关系HashMap的迭代性能。
/**
* Constructs an empty <tt>HashMap</tt> with the specified initial
* capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}关于这两个参数值的设定界限:
1. initialCapacity是map的初始化容量,initialCapacity > MAXIMUM_CAPACITY,表明map的最大容量是1<<30,也就是1左移30位,每左移一位乘以2,所以就是1*2^30=1073741824.
2. loadFactor是map的负载因子,loadFactor <= 0 || Float.isNaN(loadFactor),表明负载因子要大于0,且是非无穷大的数字
负载因子为什么会影响HashMap性能
首先回忆HashMap的数据结构,
我们都知道有序数组存储数据,对数据的索引效率都很高,但是插入和删除就会有性能瓶颈(回忆ArrayList),
链表存储数据,要一次比较元素来检索出数据,所以索引效率低,但是插入和删除效率高(回忆LinkedList),
两者取长补短就产生了哈希散列这种存储方式,也就是HashMap的存储逻辑.
而负载因子表示一个散列表的空间的使用程度,有这样一个公式:initailCapacity*loadFactor=HashMap的容量。
所以负载因子越大则散列表的装填程度越高,也就是能容纳更多的元素,元素多了,链表大了,所以此时索引效率就会降低。
反之,负载因子越小则链表中的数据量就越稀疏,此时会对空间造成烂费,但是此时索引效率高。
如何科学设置 initailCapacity,loadFactor的值
HashMap有三个构造函数,可以选用无参构造函数,不进行设置。默认值分别是16和0.75.
官方的建议是initailCapacity设置成2的n次幂,laodFactor根据业务需求,如果迭代性能不是很重要,可以设置大一下。
为什么initailCapacity要设置成2的n次幂,网友解释了,我觉得很对,以下摘自网友博客:深入理解HashMap
左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定
位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以
发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能
存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
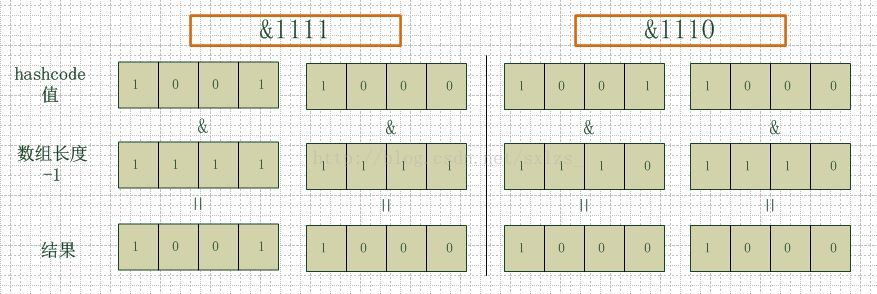
所以说,当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用
遍历某个位置上的链表,这样查询效率也就较高了。
resize()方法
initailCapacity,loadFactor会影响到HashMap扩容。
HashMap每次put操作是都会检查一遍 size(当前容量)>initailCapacity*loadFactor 是否成立。如果不成立则HashMap扩容为以前的两倍(数组扩成两倍),
然后重新计算每个元素在数组中的位置,然后再进行存储。这是一个十分消耗性能的操作。
所以如果能根据业务预估出HashMap的容量,应该在创建的时候指定容量,那么可以避免resize().
文章出处 : https://www.cnblogs.com/yesiamhere/p/6653135.html