一屋不扫何以扫天下?———《后汉书·陈蕃传》
它告诉我们,要从一点一滴的小事开始积累,才能做成一番大事业。
PS: 如果觉得本文有用的话,请帮忙点赞,留言评论支持一下哦,您的支持是我最大的动力!谢谢啦~
这几天更新了这么多篇文章,其实这些都是并发编程中最基础的知识。现在,我们是时候利用这些知识来写一个小程序了。本篇文章就来介绍如何构建一个用来存储计算结果的高效、可伸缩高速缓存,虽然简单,但也可以说算是对前面知识的一次运用了。
高速缓存,无论是在服务器端还是在前端程序中都有不同形式的实现。复用缓存里的结果可以大大缩短程序的等待时间,提高吞吐量。说的通俗一点就是利用空间换时间。在本篇文章中,将展示构建缓存程序的过程,并且分析每次优化的过程主要是针对什么问题,直至搭建好我们缓存程序。
缓存相关介绍可以参考我的这篇文章,基本概念了解一下:https://blog.csdn.net/amd123456789/article/details/52092927
下面的例子,我们想构建一个存放计算结果的缓存程序,其中计算的过程是耗时操作。
第一个版本
首先,创建一个接口 Compute,V 表示计算出来结果的类型,A表示输入对象的类型。
其次,创建一个实现类继承这个接口,ExpensiveCompute,用来实现这个计算耗时操作。
然后,创建一个 Compute 接口的包装器,Memorizer,程序的核心类;用于存储计算结果和封装整个缓存的逻辑实现。到时候,如果我们要更改方案,只需要简单修改这个包装器就可以了,其他实现类都不用修改。(装饰器的好处体现在这里)
最后,创建一个控制类 Controller 来模拟缓存的过程。
下面直接看代码,已经详细注释。

(1)Compute 接口。
public interface Compute<A, V> {
public V compute(A arg) throws InterruptedException;
}(2)ExpensiveFunction,计算耗时操作的实现类。
import java.util.concurrent.atomic.AtomicInteger;
//实现计算的类
public class ExpensiveFunction implements Compute<String, Integer>{
//原子变量
private static AtomicInteger count = new AtomicInteger(0);
//实现计算函数
public Integer compute(String arg) throws RuntimeException{
//这里表示耗时操作
for(int i = 0; i < 999898999; i++);
//这里返回计算结果
return count.incrementAndGet();
}
}(3)Memorizer,缓存核心类,封装缓存实现机制,存储计算结果。
import java.util.HashMap;
import java.util.Map;
//包装器,缓存程序的核心类
public class Memorizer<A, V> implements Compute<A, V>{
//创建一个非线程安全的Map,用以存储计算结果
public final Map<A, V> cache = new HashMap<A, V>();
//存放计算的实现类,计算最终是调用这个实现类
private Compute<A, V> c;
//构造函数,将具体计算实现类传递进来
public Memorizer(Compute<A, V> c) {
this.c = c;
}
//同步方法,确保线程安全,每次只能有一个程序进来
@Override
public synchronized V compute(A arg){
//先看是否有存储的结构了,如果有直接返回
V result = cache.get(arg);
if(result == null) {
System.out.println(arg+" 没有缓存,开始结算");
try {
//计算结果
result = this.c.compute(arg);
//存进map
cache.put(arg, result);
} catch (Exception e) {
e.printStackTrace();
}
} else {
System.out.println(arg+" 已经存有计算结果");
}
return result;
}
}(4)Controller, 控制类,启动整个程序。
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.atomic.AtomicInteger;
public class Controller {
//子线程数量
private static final int THREAD_SIZE = 10;
//设置key的个数,小于线程的个数
private static final int STR_SIZE = 5;
//传入需要计算结果的字符参数
private static final String str[] = {"key1", "key2", "key3", "key4", "key5"};
//包装类,缓存核心类
private volatile Memorizer<String, Integer> mCacheImpl ;
//闭锁,必须等待所有子线程计算结果出来,才可以打印map里面的对象
private volatile static CountDownLatch mLdc;
//构造函数
public Controller(Compute<String, Integer> c) {
mCacheImpl = new Memorizer(c);
mLdc = new CountDownLatch(THREAD_SIZE);
}
public static void main(String[] arg) {
//创建控制器
Controller mController = new Controller(new ExpensiveFunction());
//创建多个子线程,获取计算结果
for(int i = 0; i < THREAD_SIZE; i++) {
new Thread(new ComputeRunnable(mController, mLdc, i)).start();
}
try {
//等待所有线程执行完毕
mLdc.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
//打印缓存信息,即map里面的内容
Set set = mController.mCacheImpl.cache.keySet();
Iterator it = set.iterator();
while(it.hasNext()) {
String key = it.next().toString();
System.out.println(key +":"+ mController.mCacheImpl.cache.get(key));
}
}
//子线程的具体调用过程
static class ComputeRunnable implements Runnable {
private Controller controller;
private CountDownLatch cdl;
private int index;
public ComputeRunnable(Controller c, CountDownLatch cdl, int i) {
this.controller = c;
this.cdl = cdl;
this.index = i;
}
public void run() {
//调用计算函数
this.controller.mCacheImpl.compute(getKeyStr(index));
//计算完毕,打开闭锁
this.cdl.countDown();
}
}
//获取每次输入的参数
public static String getKeyStr(int index) {
return str[index % STR_SIZE];
}
}程序的执行结果如下:
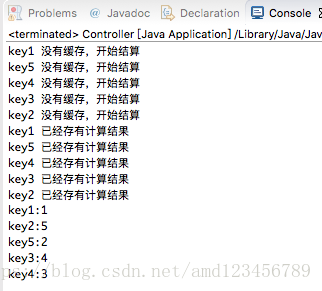
从打印的 log 可以看出执行过程了,存储过的结果不会再重复计算,能够正确的把计算结果缓存起来。
但是这样的程序,面对高并发的情况,效率会很低。为什么?
因为 compute 是同步方法,每次只能有一个线程访问,其他线程全部阻塞!假如当前操作非常耗时,那么其他线程将会全部阻塞,程序的吞吐量和响应性将会变得十分糟糕。
面对这样潜在的问题,那么我们可以用一个线程安全的 Map 来替代 HashMap。
第二个版本
Memorizer的实现用 ConcurrentHashMap 来代替 HashMap,同时去掉compute方法同步锁。
修改如下:
//创建一个线程安全的Map,用以存储计算结果
public final Map<A, V> cache = new ConcurrentHashMap<A, V>();
//去掉同步锁
@Override
public V compute(A arg){}但是执行结果还是有些小问题:

这里我们可以看到,key1 计算了两次,说明现在的程序还不能保证线程安全。我们来看下面时序图,就明白了为啥程序执行会出错:
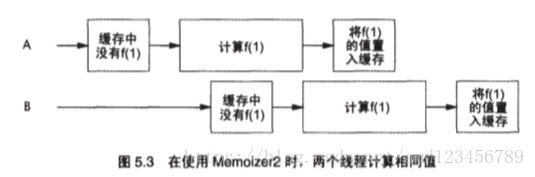
那么,怎么样才能避免这种情况发生?这又是一个需要我们思考的问题。有没有办法 B 线程去访问的时候,知道 A 线程已经在计算了,避免重复计算呢?
问题的原因就是这个代码中存在 [检查没有则更新] 的复合操作。如果想要这个复合操作能够保证同步,那么必须将这个复合代码全部加上锁。然而还有更好的方法,因为并发容器提供了这个同步操作ConcurrentHashMap@putIfAbsent(),保证这个复合操作是同步的。所以省去了手动加锁,直接用这个容器便解决了问题。
另外,我们还想把耗时操作在存进缓存的时候提取出来,不必等待计算出结果,再把结果存进缓存。FutureTask 具备这种功能,它代表一个计算可能在运行中,也可能已经结束。把这个耗时操作封装在 FutureTask 里面,然后直接把 FutureTask 存进缓存。同时,上图 B 线程访问的时候,它可以阻塞 B 线程,直至 A 计算出结果,然后 B 直接拿到 A 计算的结果。
第三个版本
现在知道方案了,这次我们同样修改 Memorizer 类。
//创建一个非线程安全的Map,用以存储计算结果
public final Map<A, Future<V>> cache = new ConcurrentHashMap<A, Future<V>>();
//去掉同步锁
@Override
public V compute(A arg){
//先看是否有存储的结构了,如果有直接返回
Future<V> f = cache.get(arg);
if(f == null) {
//创建 Callable 对象,返回结果
Callable<V> eval = new Callable<V>() {
@Override
public V call() throws Exception {
//存放计算结果
return c.compute(arg);
}
};
//FutureTask对象
FutureTask ft = new FutureTask<V>(eval);
//存储数据
f = cache.putIfAbsent(arg, ft);
if(f == null) {
//没有缓存
System.out.println(arg+" 没有缓存,开始结算");
f = ft;
ft.run(); //调用 c.compute 的耗时操作发生在这里
} else
{
//已有缓存
System.out.println(arg+" 已经存有计算结果");
}
} else {
System.out.println(arg+" 已经存有计算结果");
}
try {
return f.get();
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (ExecutionException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}按照上面修改后,执行结果已经达到我们的预期:
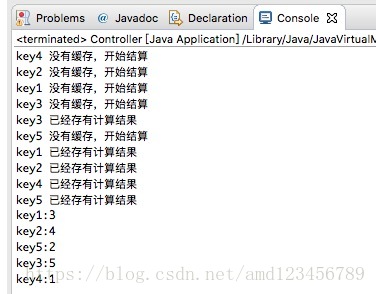
这便是我们想要构建的高效可复用的缓存程序。但是真正实用的话,远远不止这些。比如,实际运用中如何处理下面这个问题:
1. 缓存过期怎么处理?
这个问题留给我们去思考,当然,如果你想知道怎么处理,可以关注我的微信公众号:[林里少年](id:seaicelin)
回复 [缓存] 获取这个问题的答案源代码。