我们平时处理高并发的请求处理时,服务器的压力会很大。我们常做的就是构建一个高效的可伸缩的缓存来减轻服务器的压力。
1.第一次尝试
分析:使用 HashMap充当cache。
public interface Computable<A,V> {
V compute(A arg)throws InterruptedException;
}
public class Memoizer1<A, V> implements Computable<A, V>{
private final Map<A, V> cache = new HashMap<>();
private final Computable<A, V> c;
public Memoizer1(Computable<A, V> c) {
this.c = c;
}
@Override
public synchronized V compute(A arg) throws InterruptedException {
String name = Thread.currentThread().getName();
V result = cache.get(arg);
if (result == null) {
System.out.println(name+"没有命中!!!!!!!!!!!!");
result = c.compute(arg);
cache.put(arg, result);
}else {
System.out.println(name+"命中!!!!!!!!!!!!");
}
return result;
}
}
缺点:这种方式使用synchronized来保持同步,在多个线程并发访问时,会出现一些线程得不到Memoizer1对象得锁,它们会排队等锁,所以不是高效的,甚至是低效的。
2.第二次改进
分析:使用ConcurrentHashMap来代替HashMap
代码如下:
public class Memoizer2<A,V> implements Computable<A,V>{
private final Computable<A, V> c;
private final Map<A, V> cache = new ConcurrentHashMap<A,V>();
public Memoizer2(Computable<A, V> computable) {
// TODO Auto-generated constructor stub
this.c = computable;
}
@Override
public V compute(A arg) throws InterruptedException {
V result = cache.get(arg);
if (result == null) {
result = c.compute(arg);
cache.put(arg, result);
}
return result;
}
}
缺点:
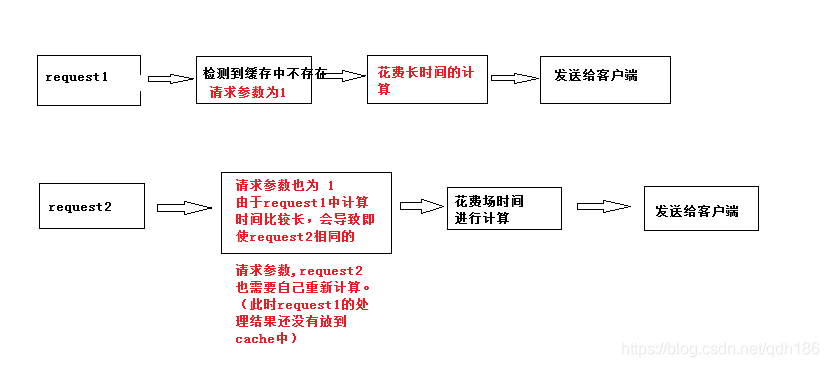
3.第三次改进
分析:为了改进第二种方法中的弊端,我们可以使用Future来代替ConcurrentHashMap中的value值。这个Future 的get方法,解决了即使第一次请求花费时间较长,当第二次携带相同的参数请求时,不会重新再去计算,而会去等待第一次计算完成后,自己从缓存中获取。
public class Memoizer3<A, V> implements Computable<A, V> {
private final Computable<A, V> c;
private final Map<A, Future<V>> cache = new ConcurrentHashMap<>();
public Memoizer3(Computable<A, V> c) {
this.c = c;
}
@Override
public V compute(final A arg) throws InterruptedException {
Future<V> f = cache.get(arg);
if (f == null) {
Callable<V> callable = new Callable<V>() {
@Override
public V call() throws Exception {
// TODO Auto-generated method stub
return c.compute(arg);
}
};
FutureTask<V> ft = new FutureTask<>(callable);
f = ft;
cache.put(arg, ft);
ft.run(); //调用callable中的compute方法
}else {
System.out.println("命中!!!");
}
try {
return f.get();
} catch (ExecutionException e) {
}
return null;
}
}
缺点:第三种方法实现上来说在某种意义上已经很大程度上改进了第二种方法的弊端,但是 if 里面的操作不是原子操作,所以还是有几率会出现第二种方法的弊端。
4.第四次改进
分析:使用ConcurrentMap的putIfAbsent来代替Map的put方法。
public class Memoizer4<A,V> implements Computable<A, V> {
private final ConcurrentMap<A, Future<V>> cache = new ConcurrentHashMap<>();
private final Computable<A, V> c;
public Memoizer4(Computable<A, V> c) {
// TODO Auto-generated constructor stub
this.c = c;
}
@Override
public V compute(final A arg) throws InterruptedException {
while (true) {
Future<V> f = cache.get(arg);
if (f == null) {
Callable<V> callable = new Callable<V>() {
@Override
public V call() throws Exception {
// TODO Auto-generated method stub
return c.compute(arg);
}
};
FutureTask<V> ft = new FutureTask<>(callable);
f = cache.putIfAbsent(arg, ft);
if (f == null) {
f = ft;
ft.run();
}
}else {
System.out.println("memoizer4命中了");
}
try {
return f.get();
} catch (ExecutionException e) {
cache.remove(arg);
}
}
}
}
缺点:第四种方法的实现彻底的改进了第二种方法中的弊端,但是在解决缓存中的值的时间有效性还没有解决。