最近和班上的一些"猿友"重新来完善或重新写以前在学校用C语言实现的数据结构,实现单链表、双向链表、循环链表、树、图等等一些数据结构。需要实现这些数据结构就必须熟练掌握C语言中的自定义类型,即结构体(struct)。虽然以前在学学校实现过,但是不是很完善,然而就当我重新动手用C来实现链表,却发现自己的C语言大部分知识点都忘得差不多。今天在这里总结和测试C语言中的结构体(struct),熟练掌握结构体将帮助我们更容易实现链表、树、图等等一些数据结构,以及对学习C语言的面向对象编程都有非常大的帮助。就让我们一起加油吧!!!
一、结构体(struct)是什么?
结构体是C语言中另一种常用的构造数据类型,它相当于其他高级语言中的记录。“结构”是一种构造类型,它是由若干"成员"组成的,每一个成员可以是一个基本数据类型或者是一个构造类型。
二、定义结构体类型
struct 结构名
{
数据类型 成员名1;//数据类型可以是普遍数据类型(int float double char ),也可以是构造性数据类型(struct enum)
................................
数据类型 成员名n
};
例如,下面定义一个结构体student,包含8个成员,定义如下:

不明白函数指针和指针函数的同志们进入这篇博客 C语言面向对象编程(定义、函数指针、指针函数)
三、结构体变量定义
前面的定义格式只是指定了一个结构体类型,它相当于一个模型,但其中并无具体数据,系统对之也不分配实际的内存单元。为了能在程序中使用结构体类型的数据,需要定义结构体类型的变量,并在其中存放具体的数据。结构体类型变量定义与基本数据类型定义类似,但是要求完成结构体定义之后才能使用此结构体定义。换言之,只有完成新的数据类型定义之后才可以使用(只有定义结构体Student,才能用结构体Student去定义变量)。C语言中的所有数据类型遵循"先定义后使用"的原则。对于基本数据类型(float、int和char等),由于其已由系统预先定义了,因此在程序设计中可以直接使用,而无须重新定义。定义结构体类型变量有如下3种方式:
1、先定义结构体后定义变量
例如:
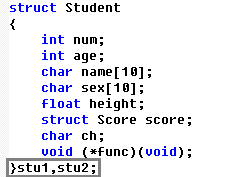
struct Student stu1,stu2;
上述代码定义了stu1和stu2为struct Student类型的变量,即它们具有struct student类型的结构。在定义了结构体变量后,系统会为之分配内存。

运行结果如下:

2、定义类型的同时定义变量
此种方式是在定义结构体类型的同时定义结构体类型变量。例如:
在定义结构体类型struct Student的同时定义了struct Student类型变量stu1和stu2。此时这个stu1和stu2就是对应文件中的全局变量,而如果在函数内部定义结构体则属于局部变量。
3、直接定义变量
此种方法在定义结构体的同时定义结构体类型的变量,但是不给出结构体名(结构体标识符),例如:

第3中方法与第二种方法的区别在于,第3种方法中省去了结构体名,而直接给出结构体变量。
四、结构体变量初始化
和其他类型的变量一样,对结构体变量定义时初始化赋值。例如:
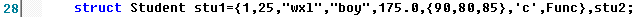
有几种结构体变量定义方式,就有几种结构体变量初始化方式,都是在结构体变量后加上“={对应成员的值,有逗号隔开}”。
五、结构体内存分布及字节对齐
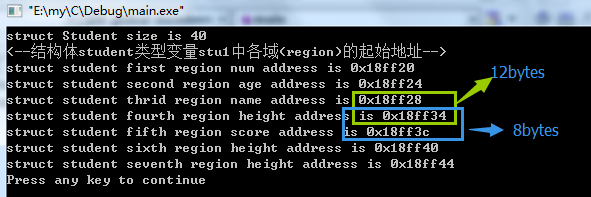
仍然以上面测试一旦结构体定义了结构体变量,系统就会自动分配内存的例子来分析结构体内存分布。程序中打印了结构体各成员变量的首地址,结果如图:
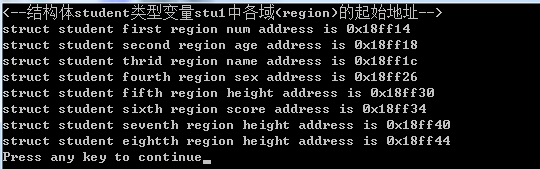
从结构体各个域的地址看,各域之间的首地址都是相差几个字节的,其实结构体中各个域在内存中是连续的,内存地址分布如下图:
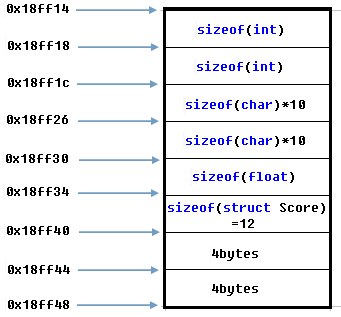
结构体Student的内存空间总大小=52bytes=(4+4+10+10+4+12+4+4);到这里我有个疑问:为什么倒数第二个内存空间大小是4bytes呢,结构体Student倒数第二个成员不是char ch;吗,不是占一个字节吗?至于最后一个为4bytes是因为一个指针的大小(sizeof)为4bytes,这根系统的位数有关,32位系统存储地址需要4个字节。
到这里我们就要看看结构体(struct)的字节对齐了,字节对齐的细节和编译器实现有关,但一般而言,满足以下准则:
- 结构体变量的首地址能够被其最宽基本类型成员的大小所整除。如,struct Student结构体的首地址是0x18ff14,对应十进制为1638164,其1638164整除4=409541,其中4为struct Student结构体成员最宽基本类型的的大小。为什么是最宽基本类型成员呢?那当该结构体包含结构体成员并且这个结构体成员的大小大于最宽基本类型成的大小呢?原因是:结构体在考虑最宽成员时会将包含于此的结构体成员"打散",被“打散”后里面也全部是基本类型。
- 结构体每个成员相对于结构体首地址的偏移量(offset)都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(internal adding)。即结构体成员的末地址减去结构体首地址(第一个结构体成员的首地址)得到的偏移量都要是对应成员大小的整数倍。
- 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在成员末尾加上填充字节。
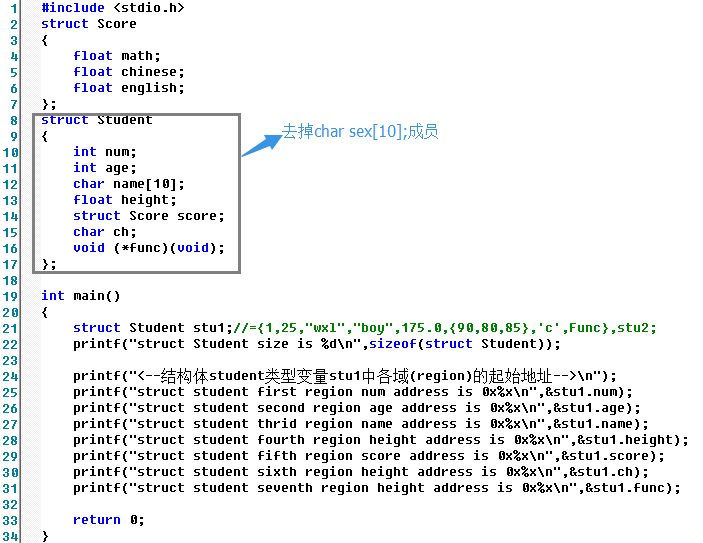

内存空间分布如下图所示:
从这里也可以看出编译器时向其对应结构体成员后面添加空间的。是不是又发现问题了:为什么第三个空间的大小是12bytes呢?既然结构体总大小要是结构体最宽基本成员的大小的整数倍,那不是只要在倒数第二个空间后面添加1byte就行吗?还有为什么上面(结构体包含char sex[10];)测试中结构体成员char name[10];是占用10bytes大小呢?
经过测试得出的结论:
为了满足字节对齐第三个准则结构体总大小要是结构体最宽基本成员大小的整数倍,则编译器先满足结构体每个成员是结构体最宽基本成员大小的整数倍,不构成整数倍往成员后面添加对应个字节。当补充的字节够下一个成员填充的话,那么这些补充的字节就用来存储下一个成员。如果下一个成员是构造类型(数组也是构造类型,由对个相同类型的基本类型构成),只有当构造类型中的最宽基本类型的大小小于等于上一个成员后面添加的字节,那么这个成员后面添加的字节将依次用来存储构造类型的成员,直到填满添加在字节数。
所有在上面包含char sex[10];成员的struct Student结构体的内存分布中,他们各自占10个字节。char name[10];后面填充的2个字节用来存储下面一个成员char sex[10];中的前两个成员(sex[0]和sex[1])。
可能的结论看起有点费劲,我们在看看几个例子吧。
测试结果如下图:
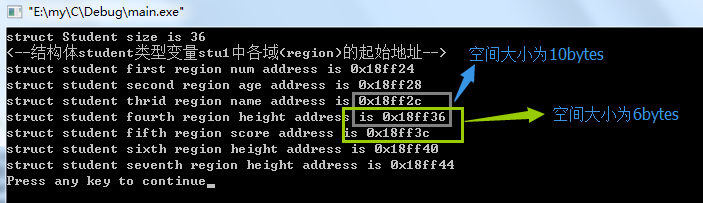
根据结果可以成员char name[10];现在只占10bytes,原因是因为下一个成员struct Score score;中的最宽基本类型大小为1byte,则struct Score结构体中的前两个成员填充了char name[10];成员后面填充的2个字节。而struct Score结构体的最后一个成员就需要在其后面添加3个字节填充字节。所有struct Score结构体最终占用空间为6个字节(3+3).
为什么当下一个成员是构造类型成员,要构造类型中的最宽基本类型的大小小于等于上一个成员后面添加的字节?测试一下就知道了,继续测试:
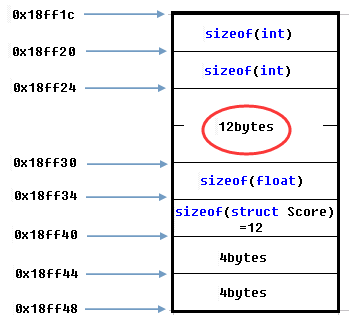
将struct Score结构体定义改为如下:

得到测试结果如下:
struct Score结构体中的第一个成员并没有填充上一个成员后面的2个字节。
我的结构体(struct)的使用、内存分布以及自己对齐测试总结先到这,等以后运到新问题再添加测试总结。