一 序
在并发编程中我们有时候需要使用线程安全的队列。如果我们要实现一个线程安全的队列有两种实现方式一种是使用阻塞算法,另一种是使用非阻塞算法。使用阻塞算法的队列可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队用不同的锁)等方式来实现,而非阻塞的实现方式则可以使用循环CAS的方式来实现.例如:ConcurrentLinkedQueue
下面从源代码中分析ConcurrentLinkedQueue的实现方法。
二 类图
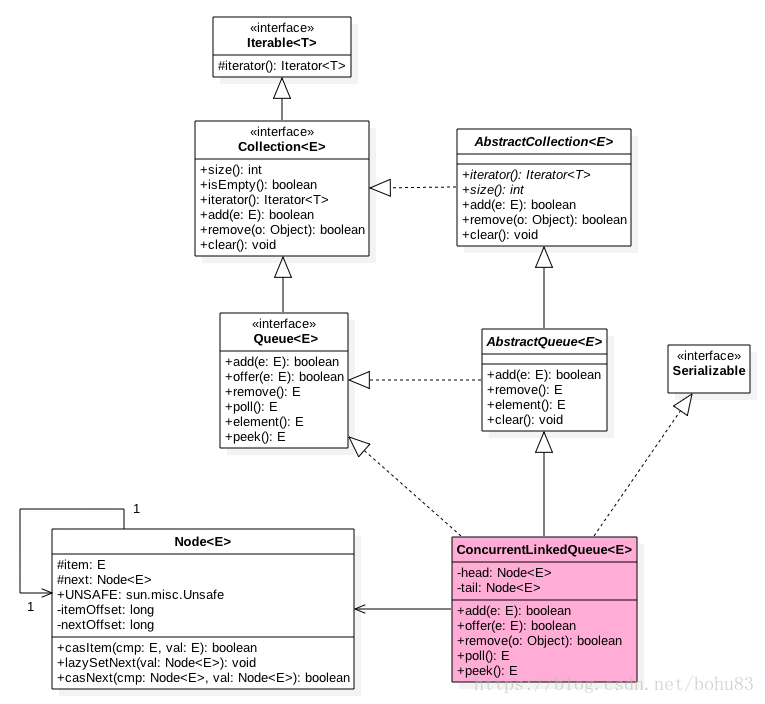
ConcurrentLinkedQueue中有两个volatile类型的Node节点分别用来存在列表的首尾节点,其中head节点存放链表第一个item为null的节点,tail则并不是总指向最后一个节点。Node节点内部则维护一个变量item用来存放节点的值,next用来存放下一个节点,从而链接为一个单向无界列表。
private transient volatile Node<E> head;
private transient volatile Node<E> tail;
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);
}再来看看Node。Node的item和next两个域都是volatile变量,保证可见性。casItem和casNext方法使用了UNSAFE提供的CAS方法保证操作的原子性。
//Node代码中使用了UNSAFE提供的CAS方法保证操作的原子性,
//UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
//第一个参数表示要更新的对象,第二个参数nextOffset是Field的偏移量,第三个参数表示期望值,最后一个参数更新后的值。若next域的值等于cmp,则把next域更新为val并返回true;否则不更新并返回false。
private static class Node<E> {
volatile E item; //Node值,volatile保证可见性
volatile Node<E> next; //Node的下一个元素,volatile保证可见性
/**
* Constructs a new node. Uses relaxed write because item can
* only be seen after publication via casNext.
*/
Node(E item) {
UNSAFE.putObject(this, itemOffset, item);
}
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long itemOffset;
private static final long nextOffset;
static {
//初始化UNSAFE和各个域在类中的偏移量
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();//初始化UNSAFE
Class k = Node.class;
//itemOffset是指类中item字段在Node类中的偏移量,先通过反射获取类的item域,然后通过UNSAFE获取item域在内存中相对于Node类首地址的偏移量。
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
//nextOffset是指类中next字段在Node类中的偏移量
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
} Node类中的lazySetNext(Node<E> val)方法,可以理解为延迟设置Next,内部是使用UNSAFE类的putOrderedObject方法实现,putOrderedXXX方法是putXXXVolatile方法的延迟实现,不保证值的改变被其他线程立即看到。为什么要lazySetNext这个方法呢?
lazySet是使用Unsafe.putOrderedObject方法,它能够实现非堵塞的写入,这些写入不会被Java的JIT重新排序指令(instruction reordering),这样它使用快速的存储-存储(store-store) 内存屏障barrier, 而不是较慢的存储-加载(store-load) 内存屏障barrier, 后者总是用在volatile的写操作上(《Java并发编程艺术》3.4章节对此有详细说明),这种性能提升是有代价的,就是写后结果并不会被其他线程看到,甚至是自己的线程,通常是几纳秒后被其他线程看到,这个时间比较短,所以代价可以忍受。需要注意的是,StoreStore屏障仅可以避免写写重排序,不保证内存可见性。
补充下背景知识:(内存屏障(Memory Barrier,或有时叫做内存栅栏,Memory Fence)是一种CPU指令,用于控制特定条件下的重排序和内存可见性问题。Java编译器也会根据内存屏障的规则禁止重排序。
内存屏障可以被分为以下几种类型
LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。 在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。)可以找个例子试试优化效果对比。
三 入队offer
入队列就是将入队节点添加到队列的尾部。为了方便理解入队时队列的变化,以及head节点和tair节点的变化,每添加一个节点我就做了一个队列的快照图。下图来自并发编程网:
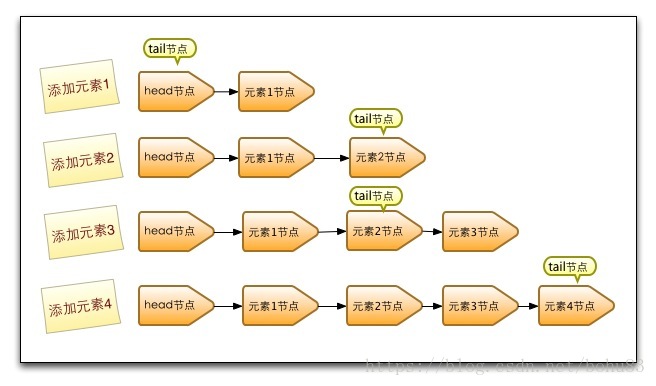
有篇文章:https://www.jianshu.com/p/9e73b9216322 ,对实现源码的每种分支都讲的很清晰,值得一看,
因为上面的流程图只考虑了单线程情况,对于并发的情况有多种判断。而且,大师写的源码我自己看起来不是那么容易懂。
//向队列的尾部插入指定的元素
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);//构造新Node
//循环CAS直到入队成功。1、根据tail节点定位出尾节点(last node);2、将新节点置为尾节点的下一个节点,3、更新尾节点casTail。
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) { //判断p是不是尾节点,tail节点不一定是尾节点,判断是不是尾节点的依据是该节点的next是不是null
// p is last node
if (p.casNext(null, newNode)) {
//设置P节点的下一个节点为新节点,如果p的next为null,说明p是尾节点,casNext返回true;如果p的next不为null,说明有其他线程更新过队列的尾节点,casNext返回false。
// Successful CAS is the linearization point
// for e to become an element of this queue,
// and for newNode to become "live".
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
else if (p == q)
//p节点是null的head节点刚好被出队,更新head节点时h.lazySetNext(h)把旧的head节点指向自己,然后head的next变为新head,所以这里需要重新找新的head,因为新的head后面的节点才是激活的节点
// We have fallen off list. If tail is unchanged, it
// will also be off-list, in which case we need to
// jump to head, from which all live nodes are always
// reachable. Else the new tail is a better bet.
p = (t != (t = tail)) ? t : head;
else
// Check for tail updates after two hops.
p = (p != t && t != (t = tail)) ? t : q;
//判断tail节点有没有被更新,如果没被更新,1)p=q:p指向p.next继续寻找尾节点;
//如果被更新了,2)p=t:P赋值为新的tail节点
//p != t && t != (t = tail)是怎么执行的?见随笔附录《通过字节码指令分析 p != t && t != (t = tail) 语句的执行》
//什么情况下p!=t.只有本分支和else if (p == q)分支含有更新变量p和t的语句,所以在p!=t出现之前已经循环过这两个分支至少一次。
}
}
private boolean casTail(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, tailOffset, cmp, val);
}下面是tail节点永远作为Queue的尾节点的入队方法代码:
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
Node</e><e> n = new Node</e><e>(e);
for (;;) {
Node</e><e> t = tail;
if (t.casNext(null, n) && casTail(t, n)) {
return true;
}
}
}让tail节点永远作为队列的尾节点,这样实现代码量非常少,而且逻辑非常清楚和易懂。但是这么做有个缺点就是每次都需要使用循环CAS更新tail节点。如果能减少CAS更新tail节点的次数,就能提高入队的效率,所以doug lea并不是每次节点入队后都将 tail节点更新成尾节点,而是当 tail节点和尾节点的距离至少间隔一个节点时才更新tail节点,tail和尾节点的距离越长使用CAS更新tail节点的次数就会越少,但是距离越长带来的负面效果就是每次入队时定位尾节点的时间就越长,因为循环体需要多循环一次来定位出尾节点,但是这样仍然能提高入队的效率,因为从本质上来看它通过增加对volatile变量的读操作来减少了对volatile变量的写操作,而对volatile变量的写操作开销要远远大于读操作,所以入队效率会有所提升。
jdk老版本1.6是使用hops变量实现的,现在注释里面还有hops的使用痕迹。
四 出队 poll
poll的实现思路与offer的实现类似,只不过把tail节点换成head节点。以下是poll过程中head节点变化示意图:
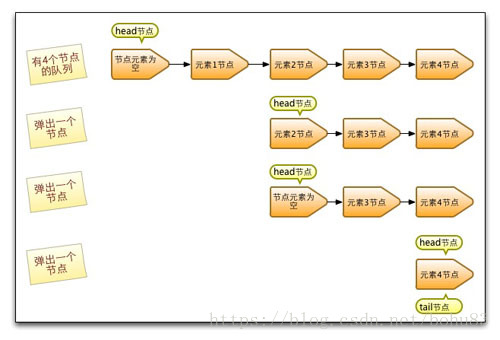
和入队相似,出队时也不是每次都会更新head节点,当head节点的item不为null时,直接弹出item;否则会更新head节点。更新head节点成功时,会把旧的head节点指向自己。也是减少使用CAS更新head节点的消耗,从而提高出队效率。
public E poll() {
restartFromHead:
//死循环
for (;;) {
//死循环
for (Node<E> h = head, p = h, q;;) {
//保存当前节点值
E item = p.item;
//当前节点有值则cas变为null(1)
if (item != null && p.casItem(item, null)) {
//cas成功标志当前节点以及从链表中移除
if (p != h) // 类似tail间隔2设置一次头节点(2)
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
//当前队列为空则返回null(3)
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
//自引用了,则重新找新的队列头节点(4)
else if (p == q)
continue restartFromHead;
else//(5)
p = q;
}
}
}
final void updateHead(Node<E> h, Node<E> p) {
if (h != p && casHead(h, p))
h.lazySetNext(h);//把旧的head节点指向自己
}
五 peek
peek操作是获取链表头部一个元素(只读取不移除),下面看看实现原理。
代码与poll类似,只是少了castItem.并且peek操作会改变head指向,offer后head指向哨兵节点,第一次peek后head会指向第一个真的节点元素。
public E peek() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
if (item != null || (q = p.next) == null) {
updateHead(h, p);
return item;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}六 size
获取当前队列元素个数,在并发环境下不是很有用,因为使用CAS没有加锁所以从调用size函数到返回结果期间有可能增删元素,导致统计的元素个数不精确。
public int size() {
int count = 0;
for (Node<E> p = first(); p != null; p = succ(p))
if (p.item != null)
// Collection.size() spec says to max out
if (++count == Integer.MAX_VALUE)
break;
return count;
}注意:这里使用上不推荐size了,时间复杂度为O(n),开销较大。并且如果在遍历的过程中,Queue有入队或出队的操作,会导致该方法统计的结果不准确。所以size()方法不太有用。那如何判断Queue是否为空呢?使用isEmpty()方法,判断第一个节点是否为null,时间复杂度为O(1)。有个例子对比下看看。
public class ConcurrentLinkedQueueTest {
private static ConcurrentLinkedQueue<Integer> queue = new ConcurrentLinkedQueue<Integer>();
private static int count = 100000;
private static int count2 = 2; // 线程个数
private static CountDownLatch cd = new CountDownLatch(count2);
public static void dothis() {
for (int i = 0; i < count; i++) {
queue.offer(i);
}
}
public static void main(String[] args) throws InterruptedException {
long timeStart = System.currentTimeMillis();
ExecutorService es = Executors.newFixedThreadPool(4);
ConcurrentLinkedQueueTest.dothis();
for (int i = 0; i < count2; i++) {
es.submit(new Poll());
}
cd.await();
System.out.println("cost time "
+ (System.currentTimeMillis() - timeStart) + "ms");
es.shutdown();
}
static class Poll implements Runnable {
@Override
public void run() {
while (queue.size()>0) {
// while (!queue.isEmpty()) {
System.out.println(queue.poll());
}
cd.countDown();
}
}
}对比下看看。size:cost time 11874ms
isEmpty:cost time 739ms
完全不是一个数量级啊,size这种全部遍历的效率太低。使用一定要慎重,不然就踩坑了。
七 contains
判断队列里面是否含有指定对象,由于是遍历整个队列,所以类似size 不是那么精确,有可能调用该方法时候元素还在队列里面,但是遍历过程中才把该元素删除了,那么就会返回false.
public boolean contains(Object o) {
if (o == null) return false;
for (Node<E> p = first(); p != null; p = succ(p)) {
E item = p.item;
if (item != null && o.equals(item))
return true;
}
return false;
}八 判断条件理解
offer里面:t != (t = tail)
还有p = (p != t && t != (t = tail)) ? t : q; 不好理解。分别来看。
demo1:
t != (t = tail)
这个判断是看当前t是不是和tail相等,相等则返回true否者为false,但是无论结果是啥执行后t的值都是tail
public static void main(String[] args) {
int t = 2;
int tail = 3;
System.out.println(t != (t = tail));
System.out.println("t "+t);
}输出结果:true
t 3javap -verbose TestNodeList
警告: 二进制文件TestNodeList包含com.daojia.collect.TestNodeList
Classfile /E:/work/test/target/classes/com/daojia/collect/TestNodeList.class
Last modified 2018-6-19; size 859 bytes
MD5 checksum aa9fe5b34c61b4aaf95e79262e9b516c
Compiled from "TestNodeList.java"
public class com.daojia.collect.TestNodeList
minor version: 0
major version: 52
flags: ACC_PUBLIC, ACC_SUPER
Constant pool:
#1 = Class #2 // com/daojia/collect/TestNodeList
#2 = Utf8 com/daojia/collect/TestNodeList
#3 = Class #4 // java/lang/Object
#4 = Utf8 java/lang/Object
#5 = Utf8 <init>
#6 = Utf8 ()V
#7 = Utf8 Code
#8 = Methodref #3.#9 // java/lang/Object."<init>":()V
#9 = NameAndType #5:#6 // "<init>":()V
#10 = Utf8 LineNumberTable
#11 = Utf8 LocalVariableTable
#12 = Utf8 this
#13 = Utf8 Lcom/daojia/collect/TestNodeList;
#14 = Utf8 main
#15 = Utf8 ([Ljava/lang/String;)V
#16 = Fieldref #17.#19 // java/lang/System.out:Ljava/io/Print
Stream;
#17 = Class #18 // java/lang/System
#18 = Utf8 java/lang/System
#19 = NameAndType #20:#21 // out:Ljava/io/PrintStream;
#20 = Utf8 out
#21 = Utf8 Ljava/io/PrintStream;
#22 = Methodref #23.#25 // java/io/PrintStream.println:(Z)V
#23 = Class #24 // java/io/PrintStream
#24 = Utf8 java/io/PrintStream
#25 = NameAndType #26:#27 // println:(Z)V
#26 = Utf8 println
#27 = Utf8 (Z)V
#28 = Class #29 // java/lang/StringBuilder
#29 = Utf8 java/lang/StringBuilder
#30 = String #31 // t
#31 = Utf8 t
#32 = Methodref #28.#33 // java/lang/StringBuilder."<init>":(L
java/lang/String;)V
#33 = NameAndType #5:#34 // "<init>":(Ljava/lang/String;)V
#34 = Utf8 (Ljava/lang/String;)V
#35 = Methodref #28.#36 // java/lang/StringBuilder.append:(I)L
java/lang/StringBuilder;
#36 = NameAndType #37:#38 // append:(I)Ljava/lang/StringBuilder;
#37 = Utf8 append
#38 = Utf8 (I)Ljava/lang/StringBuilder;
#39 = Methodref #28.#40 // java/lang/StringBuilder.toString:()
Ljava/lang/String;
#40 = NameAndType #41:#42 // toString:()Ljava/lang/String;
#41 = Utf8 toString
#42 = Utf8 ()Ljava/lang/String;
#43 = Methodref #23.#44 // java/io/PrintStream.println:(Ljava/
lang/String;)V
#44 = NameAndType #26:#34 // println:(Ljava/lang/String;)V
#45 = Utf8 args
#46 = Utf8 [Ljava/lang/String;
#47 = Utf8 t
#48 = Utf8 I
#49 = Utf8 tail
#50 = Utf8 StackMapTable
#51 = Class #46 // "[Ljava/lang/String;"
#52 = Utf8 SourceFile
#53 = Utf8 TestNodeList.java
{
public com.daojia.collect.TestNodeList();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #8 // Method java/lang/Object."<init>
":()V
4: return
LineNumberTable:
line 3: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/daojia/collect/TestNodeList;
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=4, locals=3, args_size=1
0: iconst_2
1: istore_1
2: iconst_3
3: istore_2
4: getstatic #16 // Field java/lang/System.out:Ljav
a/io/PrintStream;
7: iload_1
8: iload_2
9: dup
10: istore_1
11: if_icmpeq 18
14: iconst_1
15: goto 19
18: iconst_0
19: invokevirtual #22 // Method java/io/PrintStream.prin
tln:(Z)V
22: getstatic #16 // Field java/lang/System.out:Ljav
a/io/PrintStream;
25: new #28 // class java/lang/StringBuilder
28: dup
29: ldc #30 // String t
31: invokespecial #32 // Method java/lang/StringBuilder.
"<init>":(Ljava/lang/String;)V
34: iload_1
35: invokevirtual #35 // Method java/lang/StringBuilder.
append:(I)Ljava/lang/StringBuilder;
38: invokevirtual #39 // Method java/lang/StringBuilder.
toString:()Ljava/lang/String;
41: invokevirtual #43 // Method java/io/PrintStream.prin
tln:(Ljava/lang/String;)V
44: return
LineNumberTable:
line 6: 0
line 7: 2
line 9: 4
line 10: 22
line 11: 44
LocalVariableTable:
Start Length Slot Name Signature
0 45 0 args [Ljava/lang/String;
2 43 1 t I
4 41 2 tail I
StackMapTable: number_of_entries = 2
frame_type = 255 /* full_frame */
offset_delta = 18
locals = [ class "[Ljava/lang/String;", int, int ]
stack = [ class java/io/PrintStream ]
frame_type = 255 /* full_frame */
offset_delta = 0
locals = [ class "[Ljava/lang/String;", int, int ]
stack = [ class java/io/PrintStream, int ]
}
SourceFile: "TestNodeList.java"开始栈为空
第0行指令作用是把值2入栈栈顶元素为2
第1行指令作用是将栈顶int类型值保存到局部变量t中。
第2行指令作用是把值3入栈栈顶元素为3
第3行指令作用是将栈顶int类型值保存到局部变量tail中。
第4调用打印命令
第7行指令作用是把变量t中的值入栈.栈中元素2
第8行指令作用是把变量tail中的值入栈, 此时栈中元素为3,2并且3位栈顶
第9行指令作用是复制栈顶一个字长的数据,将复制后的数据压栈,所以现在栈内容3,3,2
第10行指令作用是把栈顶元素存放到t,现在栈内容3,2
第11行指令if_icmpeq作用是判断栈顶两个元素值,相等则跳转 18。由于现在栈顶元素为3,2不相等所以返回(true )1.
第14行指令作用是把(true)1入栈。
可见编译器是采用了if_icmpeq 来截断了!=判断。左侧的赋值。右侧的计算,再进行对比。
demo2:
public static void main(String[] args) {
int t = 8;
int p = t;
int tail = 9;
boolean result = (p != t && t != (t = tail));
System.out.println("p=" + p + ", t=" + t + ", result=" + result);
}输出:p=8, t=8, result=false,t=8说明没有执行t != (t = tail)语句。
看看反编译后的代码:
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=4, locals=5, args_size=1
0: bipush 8 //valuebyte值带符号扩展成int值入栈。8
2: istore_1 //将栈顶int类型值保存到局部变量1中。即赋值给变量t,8出栈
3: iload_1 //从局部变量1中装载int类型值入栈。即t值入栈,
4: istore_2 从局部变量2中装载int类型值入栈。即赋值给q,同时t出栈
5: bipush 9 //常量9入栈
7: istore_3 //赋值给变量tail,9出栈
8: iload_2 //q值入栈
9: iload_1 //t值入栈
10: if_icmpeq 24 //比较栈顶两int型数值大小,当结果等于0时跳转。即比较p!=t,结果为false(0),跳转到24行,同时p和t出栈
13: iload_1
14: iload_3
15: dup
16: istore_1
17: if_icmpeq 24
20: iconst_1
21: goto 25
24: iconst_0 //将int型0压入栈顶。
25: istore 4 //将栈顶int型数值存入指定本地变量。即将result赋值为0(false)
27: getstatic #16 // Field java/lang/System.out:Ljav
a/io/PrintStream;总结:
ConcurrentLinkedQueue是并发大师Doug Lea根据Michael-Scott提出的非阻塞链接队列算法的基础上修改而来,它是一个基于链表的无界线程安全队列,它采用先入先出的规则对节点进行排序,当我们添加一个节点的时候,它会添加到队列的尾部;当我们获取一个元素的时,它会返回队列头部的元素。它通过使用head和tail引用延迟更改的方式,减少CAS操作,在满足线程安全的前提下,提高了队列的操作效率。jdk1.6版本用了hops来计算。1.8版本已经用变量p来替代。
需要注意的是由于使用CAS没有使用锁,所以获取size的时候有可能进行offer,poll或者remove操作,导致获取的元素个数不精确,所以在并发情况下size函数不是很有用,遍历耗时慢,要慎重,可能的情况用isEmpty替代。
参考:
http://ifeve.com/concurrentlinkedqueue/
https://www.cnblogs.com/zaizhoumo/p/7726218.html