一旦数据仓库开始使用,就需要不断从源系统给数据仓库提供新数据。为了确保数据流的稳定,需要使用所在平台上可用的任务调度器来调度ETL定期执行。调度模块是ETL系统必不可少的组成部分,它不但是数据仓库的基本需求,也对项目的成功起着举足轻重的作用。本篇说明如何使用HDP中的Oozie和Falcon服务实现ETL执行自动化。

Oozie是一种Java Web应用程序,它运行在Java Servlet容器、即Tomcat中,并使用数据库来存储以下内容:
hPDL是一种很简洁的语言,它只会使用少数流程控制节点和动作节点。控制节点会定义执行的流程,并包含工作流的起点和终点(start、end和fail节点)以及控制工作流执行路径的机制(decision、fork和join节点)。动作节点是实际执行操作的部分,通过它们工作流会触发执行计算或者处理任务。
所有由动作节点触发的计算和处理任务都不在Oozie中运行。它们是由Hadoop的MapReduce框架执行的。这种低耦合的设计方法让Oozie可以有效利用Hadoop的负载平衡、灾难恢复等机制。这些任务主要是串行执行的,只有文件系统动作例外,它是并行处理的。这意味着对于大多数工作流动作触发的计算或处理任务类型来说,在工作流操作转换到工作流的下一个节点之前都需要等待,直到前面节点的计算或处理任务结束了之后才能够继续。Oozie可以通过两种不同的方式来检测计算或处理任务是否完成,这就是回调和轮询。当Oozie启动了计算或处理任务时,它会为任务提供唯一的回调URL,然后任务会在完成的时候发送通知给这个特定的URL。在任务无法触发回调URL的情况下(可能是因为任何原因,比方说网络闪断),或者当任务的类型无法在完成时触发回调URL的时候,Oozie有一种机制,可以对计算或处理任务进行轮询,从而能够判断任务是否完成。
Oozie工作流可以参数化,例如在工作流定义中使用像${inputDir}之类的变量等。在提交工作流操作的时候,我们必须提供参数值。如果经过合适地参数化,比如使用不同的输出目录,那么多个同样的工作流操作可以并发执行。
一些工作流是根据需要触发的,但是大多数情况下,我们有必要基于一定的时间段、数据可用性或外部事件来运行它们。Oozie协调系统(Coordinator system)让用户可以基于这些参数来定义工作流执行计划。Oozie协调程序让我们可以用谓词的方式对工作流执行触发器进行建模,谓词可以是时间条件、数据条件、内部事件或外部事件。工作流作业会在谓词得到满足的时候启动。不难看出,这里的谓词,其作用和SQL语句的WHERE子句中的谓词类似,本质上都是在满足某些条件时触发某种事件。
有时,我们还需要连接定时运行、但时间间隔不同的工作流操作。多个以不同频率运行的工作流的输出会成为下一个工作流的输入。把这些工作流连接在一起,会让系统把它作为数据应用的管道来引用。Oozie协调程序支持创建这样的数据应用管道。
(1)记录当前Sqoop作业的last.value值
(2)在MySQL中创建Sqoop的元数据存储数据库
在Ambari的Sqoop -> Configs -> Custom sqoop-site中添加如图2所示的参数。

(4)重启Sqoop服务
保存配置并重启完成后,MySQL的sqoop库中有了一个名为SQOOP_ROOT的空表。
(1)修改/etc/passwd文件
HDP缺省运行Oozie Server的用户是Oozie,因此在/etc/passwd中更改Oozie用户,使得其可登录。我的环境配置是:
我是用root提交Oozie的任务的,所以这里要对从Oozie用户到root用户做免密码登录。
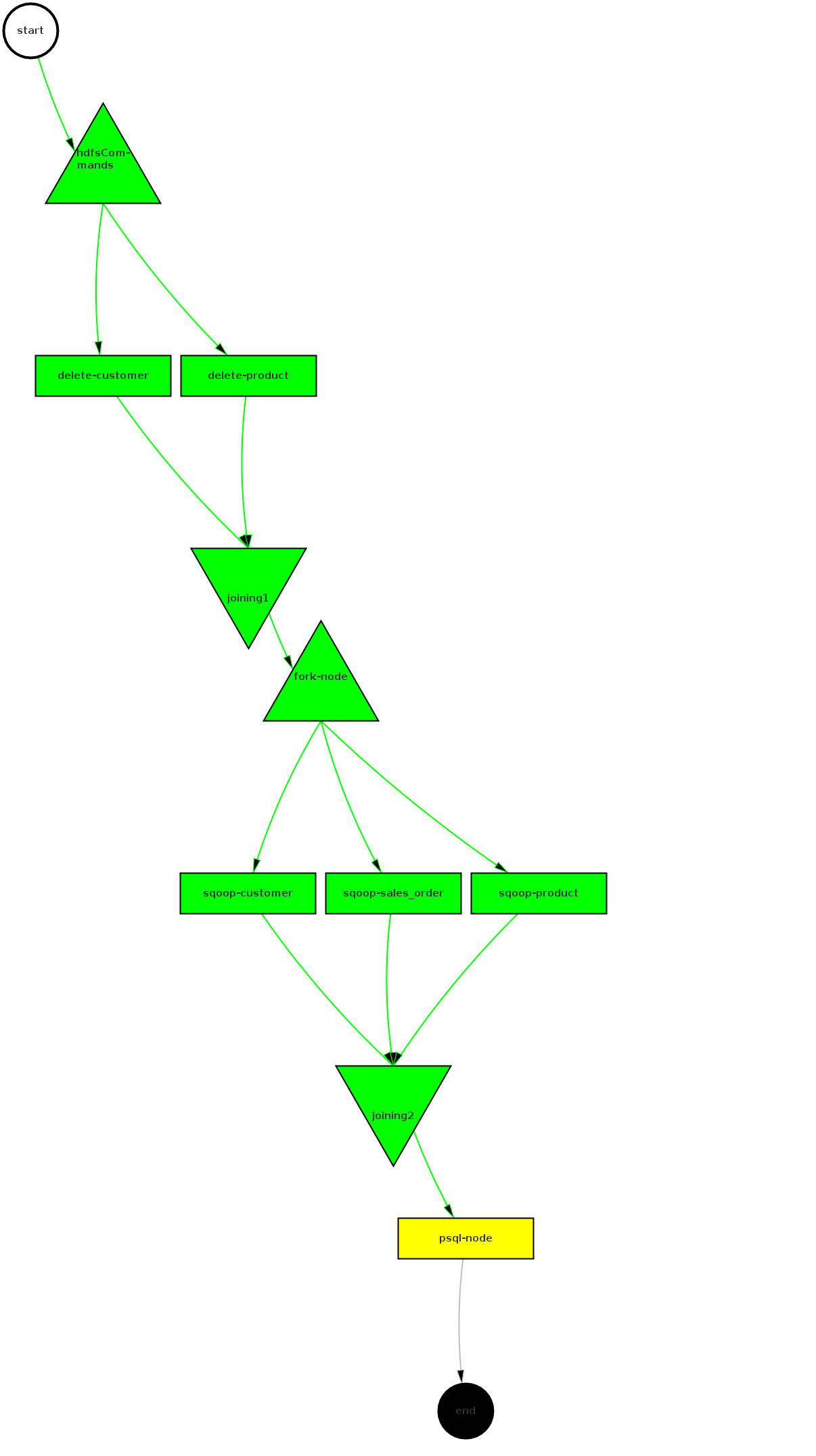
上面的XML文件使用hPDL的语法定义了一个名为RegularETL的工作流。该工作流包括13个节点,其中有7个控制节点,6个动作节点:工作流的起点start、终点end、失败处理节点fail(DAG图中未显示);四个执行路径控制节点hdfsCommands、joining1、fork-node和joining2;两个并行的FS动作节点delete-customer、delete-product,用于删除全量抽取的HDFS数据目录;三个并行处理的Sqoop动作节点sqoop-customer、sqoop-product、sqoop-sales_order用作数据抽取;一个SSH动作节点psql-node调用本地shell脚本,执行OushuDB数据装载。
Oozie的工作流节点分为控制节点和动作节点两类。控制节点控制着工作流的开始、结束和作业的执行路径。动作节点触发计算或处理任务的执行。节点的名字必须符合[a-zA-Z][\-_a-zA-Z0-0]*这种正则表达式模式,并且不能超过20个字符。为了能让Falcon调用Oozie工作流,工作流名称不要带下划线等字符。
工作流定义中可以使用形式参数。当工作流被Oozie执行时,所有形参都必须提供具体的值。参数定义使用JSP 2.0的语法,参数不仅可以是单个变量,还支持函数和复合表达式。参数可以用于指定动作节点和decision节点的配置值、XML属性值和XML元素值,但是不能在节点名称、XML属性名称、XML元素名称和节点的转向元素中使用参数。上面工作流中的${jobTracker}和${nameNode}两个参数,分别指定YARN资源管理器的主机/端口和HDFS NameNode的主机/端口(如果配置了HDFS HA,nameNode使用Nameservice ID)。${focusNodeLogin}指定本地shell脚本所在主机,${myScript}指定本地shell脚本文件全路径。
Oozie的工作流作业本身还提供了丰富的内建函数,Oozie将它们统称为表达式语言函数(Expression Language Functions,简称EL函数)。通过这些函数可以对动作节点和decision节点的谓词进行更复杂的参数化。我的工作流中使用了wf:errorMessage和wf:lastErrorNode两个内建函数。wf:errorMessage函数返回特定节点的错误消息,如果没有错误则返回空字符串。错误消息常被用于排错和通知的目的。wf:lastErrorNode函数返回最后出错的节点名称,如果没有错误则返回空字符串。
Apache Falcon解决了大数据领域中一个非常重要和关键的问题。升级为顶级项目是该项目的一个重大进展。Apache Falcon有一个完善的路线图,可以减少应用程序开发和管理人员编写和管理复杂数据管理和处理应用程序的痛苦。
用户会发现,在Apache Falcon中,“基础设施端点(infrastructure endpoint)”、数据集(也称 Feed )、处理规则均是声明式的。这种声明式配置显式定义了实体之间的依赖关系。这也是该平台的一个特点,它本身只维护依赖关系,而并不做任何繁重的工作。所有的功能和工作流状态管理需求都委托给工作流调度程序来完成。
从上图可以看出,Apache Falcon:
定义Falcon Process可以参考“ DEFINE AND PROCESS DATA PIPELINES IN HADOOP WITH APACHE FALCON”。
在Oozie Web UI可以看到,Falcon在Oozie中自动创建了Workflow Job、Coordinator Job和Bundle Job,分别如图8、图9、图10所示。



一、Oozie简介
Oozie是一个管理Hadoop作业、可伸缩、可扩展、可靠的工作流调度系统,它内部定义了三种作业:工作流作业、协调器作业和Bundle作业。工作流作业是由一系列动作构成的有向无环图(Directed Acyclic Graph,DAG),协调器作业是按时间频率周期性触发Oozie工作流的作业,Bundle管理协调器作业。Oozie支持的用户作业类型有Java map-reduce、Streaming map-reduce、Pig、 Hive、Sqoop和Distcp,及其Java程序和shell脚本或命令等特定的系统作业。1. 为什么使用Oozie
使用Oozie主要基于以下两点原因:- 在Hadoop中执行的任务有时候需要把多个MapReduce作业连接到一起执行,或者需要多个作业并行处理。Oozie可以把多个MapReduce作业组合到一个逻辑工作单元中,从而完成更大型的任务。
- 从调度的角度看,如果使用crontab的方式调用多个工作流作业,可能需要编写大量的脚本,还要通过脚本来控制好各个工作流作业的执行时序问题,不但不好维护,而且监控也不方便。基于这样的背景,Oozie提出了Coordinator的概念,它能够将每个工作流作业作为一个动作来运行,相当于工作流定义中的一个执行节点,这样就能够将多个工作流作业组成一个称为Coordinator Job的作业,并指定触发时间和频率,还可以配置数据集、并发数等。
2. Oozie的体系结构
Oozie的体系结构如图1所示。
图1
Oozie是一种Java Web应用程序,它运行在Java Servlet容器、即Tomcat中,并使用数据库来存储以下内容:
- 工作流定义。
- 当前运行的工作流实例,包括实例的状态和变量。
hPDL是一种很简洁的语言,它只会使用少数流程控制节点和动作节点。控制节点会定义执行的流程,并包含工作流的起点和终点(start、end和fail节点)以及控制工作流执行路径的机制(decision、fork和join节点)。动作节点是实际执行操作的部分,通过它们工作流会触发执行计算或者处理任务。
所有由动作节点触发的计算和处理任务都不在Oozie中运行。它们是由Hadoop的MapReduce框架执行的。这种低耦合的设计方法让Oozie可以有效利用Hadoop的负载平衡、灾难恢复等机制。这些任务主要是串行执行的,只有文件系统动作例外,它是并行处理的。这意味着对于大多数工作流动作触发的计算或处理任务类型来说,在工作流操作转换到工作流的下一个节点之前都需要等待,直到前面节点的计算或处理任务结束了之后才能够继续。Oozie可以通过两种不同的方式来检测计算或处理任务是否完成,这就是回调和轮询。当Oozie启动了计算或处理任务时,它会为任务提供唯一的回调URL,然后任务会在完成的时候发送通知给这个特定的URL。在任务无法触发回调URL的情况下(可能是因为任何原因,比方说网络闪断),或者当任务的类型无法在完成时触发回调URL的时候,Oozie有一种机制,可以对计算或处理任务进行轮询,从而能够判断任务是否完成。
Oozie工作流可以参数化,例如在工作流定义中使用像${inputDir}之类的变量等。在提交工作流操作的时候,我们必须提供参数值。如果经过合适地参数化,比如使用不同的输出目录,那么多个同样的工作流操作可以并发执行。
一些工作流是根据需要触发的,但是大多数情况下,我们有必要基于一定的时间段、数据可用性或外部事件来运行它们。Oozie协调系统(Coordinator system)让用户可以基于这些参数来定义工作流执行计划。Oozie协调程序让我们可以用谓词的方式对工作流执行触发器进行建模,谓词可以是时间条件、数据条件、内部事件或外部事件。工作流作业会在谓词得到满足的时候启动。不难看出,这里的谓词,其作用和SQL语句的WHERE子句中的谓词类似,本质上都是在满足某些条件时触发某种事件。
有时,我们还需要连接定时运行、但时间间隔不同的工作流操作。多个以不同频率运行的工作流的输出会成为下一个工作流的输入。把这些工作流连接在一起,会让系统把它作为数据应用的管道来引用。Oozie协调程序支持创建这样的数据应用管道。
二、建立工作流前的准备
我们的定期ETL需要使用Oozie中的FS、Sqoop和SSH三种动作,其中增量数据抽取要用到Sqoop job。由于Oozie在执行这些动作时存在一些特殊要求,因此在定义工作流前先要进行适当的配置。1. 启动Oozie服务
我的实验环境用的是HDP2.5.3,在安装之时就已经配置并启动了Oozie服务。HDP安装过程参见“ OushuDB入门(一)——安装篇”2. 配置Sqoop的metastore
缺省时,Sqoop metastore自动连接存储在~/.sqoop/.目录下的本地嵌入式数据库。然而要在Oozie中执行Sqoop job需要Sqoop使用共享的元数据存储,否则会报类似如下的错误:ERROR org.apache.sqoop.metastore.hsqldb.HsqldbJobStorage - Cannot restore job。在本例中我使用hdp2上的MySQL数据库存储Sqoop的元数据。(1)记录当前Sqoop作业的last.value值
last_value=`sqoop job --show myjob_incremental_import | grep incremental.last.value | awk '{print $3 " " $4}'`(2)在MySQL中创建Sqoop的元数据存储数据库
create database sqoop;
create user 'sqoop'@'%' identified by 'sqoop';
grant all privileges on sqoop.* to 'sqoop'@'%';
flush privileges;在Ambari的Sqoop -> Configs -> Custom sqoop-site中添加如图2所示的参数。
图2
- sqoop.metastore.server.location:指定元数据服务器位置,初始化建表时需要。
- sqoop.metastore.client.autoconnect.url:客户端自动连接的数据库的URL。
- sqoop.metastore.client.autoconnect.username:连接数据库的用户名。
- sqoop.metastore.client.enable.autoconnect:启用客户端自动连接数据库。
- sqoop.metastore.client.record.password:在数据库中保存密码,不需要密码即可执行sqoop job脚本。
- sqoop.metastore.client.autoconnect.password:连接数据库的密码。
(4)重启Sqoop服务
保存配置并重启完成后,MySQL的sqoop库中有了一个名为SQOOP_ROOT的空表。
mysql> show tables;
+-----------------+
| Tables_in_sqoop |
+-----------------+
| SQOOP_ROOT |
+-----------------+
1 row in set (0.00 sec)use sqoop;
insert into SQOOP_ROOT values (NULL, 'sqoop.hsqldb.job.storage.version', '0'); sqoop job --listmysql> show tables;
+-----------------+
| Tables_in_sqoop |
+-----------------+
| SQOOP_ROOT |
| SQOOP_SESSIONS |
+-----------------+
2 rows in set (0.00 sec)alter table SQOOP_ROOT engine=myisam;
alter table SQOOP_SESSIONS engine=myisam; 3. 创建myjob_incremental_import作业
sqoop job --delete myjob_incremental_import
sqoop job --create myjob_incremental_import \
-- import \
--connect "jdbc:mysql://172.16.1.127:3306/source?usessl=false&user=dwtest&password=123456" \
--table sales_order \
--hcatalog-database test \
--hcatalog-table sales_order \
--compress \
--incremental lastmodified \
--check-column entry_date \
--skip-dist-cache \
--last-value "$last_value"ERROR org.apache.sqoop.tool.ImportTool - Imported Failed: Can not create a Path from an empty string
ERROR [main] tool.ImportTool (ImportTool.java:run(607)) - Imported Failed: Can not create a Path from an empty stringselect * from SQOOP_SESSIONS\G
...
*************************** 54. row ***************************
job_name: myjob_incremental_import
propname: db.batch
propval: false
propclass: SqoopOptions
*************************** 55. row ***************************
job_name: myjob_incremental_import
propname: hcatalog.table.name
propval: sales_order
propclass: SqoopOptions
*************************** 56. row ***************************
job_name: myjob_incremental_import
propname: sqoop.job.storage.implementations
propval: com.cloudera.sqoop.metastore.hsqldb.HsqldbJobStorage,com.cloudera.sqoop.metastore.hsqldb.AutoHsqldbStorage
propclass: config
*************************** 57. row ***************************
job_name: myjob_incremental_import
propname: mapreduce.client.genericoptionsparser.used
propval: true
propclass: config
57 rows in set (0.00 sec)sqoop job --list
...
Available jobs:
myjob_incremental_import4. 准备java-json.jar文件
Oozie中执行Sqoop时如果缺少java-json.jar文件,会报类似如下的错误:Failing Oozie Launcher, Main class [org.apache.oozie.action.hadoop.SqoopMain], main() threw exception, org/json/JSONObjectcp java-json.jar /usr/hdp/current/sqoop-client/lib/
su - hdfs -c 'hdfs dfs -put /usr/hdp/current/sqoop-client/lib/java-json.jar /user/oozie/share/lib/lib_20180428131446/sqoop/'5. 配置SSH免密码登录
实际的数据装载过程是通过OushuDB的自定义函数实现的,自然工作流中要执行包含psql命令行的本地shell脚本文件。这需要明确要调用的shell使用的是本地的shell,可以通过Oozie中的SSH动作指定本地文件。在使用SSH这个动作的时候,可能会遇到AUTH_FAILED:Not able to perform operation的问题,解决该问题要对Oozie的服务器做免密码登录。(1)修改/etc/passwd文件
HDP缺省运行Oozie Server的用户是Oozie,因此在/etc/passwd中更改Oozie用户,使得其可登录。我的环境配置是:
oozie:x:506:504:Oozie user:/home/oozie:/bin/bash我是用root提交Oozie的任务的,所以这里要对从Oozie用户到root用户做免密码登录。
su - oozie
ssh-keygen
... 一路回车生成密钥文件 ...
su -
# 将oozie的公钥复制到root的authorized_keys文件中
cat /home/oozie/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
chmod 0600 /home/oozie/.ssh/id_rsa二、用Oozie建立定期ETL工作流
1. 建立workflow.xml文件
建立内容如下的workflow.xml文件:<?xml version="1.0" encoding="UTF-8"?>
<workflow-app xmlns="uri:oozie:workflow:0.4" name="RegularETL">
<start to="hdfsCommands"/>
<fork name="hdfsCommands">
<path start="delete-customer" />
<path start="delete-product" />
</fork>
<action name="delete-customer">
<fs><delete path='${nameNode}/data/rds/customer/*'/></fs>
<ok to="joining1"/>
<error to="fail"/>
</action>
<action name="delete-product">
<fs><delete path='${nameNode}/data/rds/product/*'/></fs>
<ok to="joining1"/>
<error to="fail"/>
</action>
<join name="joining1" to="fork-node"/>
<fork name="fork-node">
<path start="sqoop-customer" />
<path start="sqoop-product" />
<path start="sqoop-sales_order" />
</fork>
<action name="sqoop-customer">
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<arg>import</arg>
<arg>--connect</arg>
<arg>jdbc:mysql://172.16.1.127:3306/source?useSSL=false</arg>
<arg>--username</arg>
<arg>dwtest</arg>
<arg>--password</arg>
<arg>123456</arg>
<arg>--table</arg>
<arg>customer</arg>
<arg>--hcatalog-database</arg>
<arg>test</arg>
<arg>--hcatalog-table</arg>
<arg>customer</arg>
<arg>--null-string</arg>
<arg>'\\N'</arg>
<arg>--null-non-string</arg>
<arg>'\\N'</arg>
<arg>--compress</arg>
<arg>--skip-dist-cache</arg>
<file>/tmp/hive-site.xml#hive-site.xml</file>
</sqoop>
<ok to="joining2"/>
<error to="fail"/>
</action>
<action name="sqoop-product">
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<arg>import</arg>
<arg>--connect</arg>
<arg>jdbc:mysql://172.16.1.127:3306/source?useSSL=false</arg>
<arg>--username</arg>
<arg>dwtest</arg>
<arg>--password</arg>
<arg>123456</arg>
<arg>--table</arg>
<arg>product</arg>
<arg>--hcatalog-database</arg>
<arg>test</arg>
<arg>--hcatalog-table</arg>
<arg>product</arg>
<arg>--null-string</arg>
<arg>'\\N'</arg>
<arg>--null-non-string</arg>
<arg>'\\N'</arg>
<arg>--compress</arg>
<arg>--skip-dist-cache</arg>
<file>/tmp/hive-site.xml#hive-site.xml</file>
</sqoop>
<ok to="joining2"/>
<error to="fail"/>
</action>
<action name="sqoop-sales_order">
<sqoop xmlns="uri:oozie:sqoop-action:0.2">
<job-tracker>${jobTracker}</job-tracker>
<name-node>${nameNode}</name-node>
<command>job --meta-connect jdbc:mysql://hdp2/sqoop?user=sqoop&password=sqoop --exec myjob_incremental_import</command>
<file>/tmp/hive-site.xml#hive-site.xml</file>
<archive>/user/oozie/share/lib/lib_20180428131446/sqoop/java-json.jar#java-json.jar</archive>
</sqoop>
<ok to="joining2"/>
<error to="fail"/>
</action>
<join name="joining2" to="psql-node"/>
<action name="psql-node">
<ssh xmlns="uri:oozie:ssh-action:0.1">
<host>${focusNodeLogin}</host>
<command>${myScript}</command>
<capture-output/>
</ssh>
<ok to="end"/>
<error to="fail"/>
</action>
<kill name="fail">
<message>Sqoop failed, error message[${wf:errorMessage(wf:lastErrorNode())}]</message>
</kill>
<end name="end"/>
</workflow-app>
图3
上面的XML文件使用hPDL的语法定义了一个名为RegularETL的工作流。该工作流包括13个节点,其中有7个控制节点,6个动作节点:工作流的起点start、终点end、失败处理节点fail(DAG图中未显示);四个执行路径控制节点hdfsCommands、joining1、fork-node和joining2;两个并行的FS动作节点delete-customer、delete-product,用于删除全量抽取的HDFS数据目录;三个并行处理的Sqoop动作节点sqoop-customer、sqoop-product、sqoop-sales_order用作数据抽取;一个SSH动作节点psql-node调用本地shell脚本,执行OushuDB数据装载。
Oozie的工作流节点分为控制节点和动作节点两类。控制节点控制着工作流的开始、结束和作业的执行路径。动作节点触发计算或处理任务的执行。节点的名字必须符合[a-zA-Z][\-_a-zA-Z0-0]*这种正则表达式模式,并且不能超过20个字符。为了能让Falcon调用Oozie工作流,工作流名称不要带下划线等字符。
工作流定义中可以使用形式参数。当工作流被Oozie执行时,所有形参都必须提供具体的值。参数定义使用JSP 2.0的语法,参数不仅可以是单个变量,还支持函数和复合表达式。参数可以用于指定动作节点和decision节点的配置值、XML属性值和XML元素值,但是不能在节点名称、XML属性名称、XML元素名称和节点的转向元素中使用参数。上面工作流中的${jobTracker}和${nameNode}两个参数,分别指定YARN资源管理器的主机/端口和HDFS NameNode的主机/端口(如果配置了HDFS HA,nameNode使用Nameservice ID)。${focusNodeLogin}指定本地shell脚本所在主机,${myScript}指定本地shell脚本文件全路径。
Oozie的工作流作业本身还提供了丰富的内建函数,Oozie将它们统称为表达式语言函数(Expression Language Functions,简称EL函数)。通过这些函数可以对动作节点和decision节点的谓词进行更复杂的参数化。我的工作流中使用了wf:errorMessage和wf:lastErrorNode两个内建函数。wf:errorMessage函数返回特定节点的错误消息,如果没有错误则返回空字符串。错误消息常被用于排错和通知的目的。wf:lastErrorNode函数返回最后出错的节点名称,如果没有错误则返回空字符串。
2. 部署工作流
这里所说的部署就是把相关文件上传到HDFS的对应目录中。我们需要上传工作流定义文件,还要上传file、archive、script元素中指定的文件。可以使用hdfs dfs -put命令将本地文件上传到HDFS,-f参数的作用是,如果目标位置已经存在同名的文件,则用上传的文件覆盖已存在的文件。# 上传工作流文件
hdfs dfs -put -f /home/oozie/workflow.xml /user/oozie/
# 上传MySQL JDBC驱动文件到Oozie的共享库目录中
hdfs dfs -put -f /root/mysql-connector-java-5.1.38/mysql-connector-java-5.1.38-bin.jar /user/oozie/share/lib/lib_20180428131446/sqoop/
# 启动oozie作业时加载hcatalog包
hdfs dfs -put -f /usr/hdp/2.5.3.0-37/hive-hcatalog/share/hcatalog/* /user/oozie/share/lib/lib_20180428131446/sqoop/3. 建立本地shell脚本文件
建立内容如下的/root/regular_etl.sh文件:#!/bin/bash
# 使用gpadmin用户执行定期装载函数
su - gpadmin -c 'export PGPASSWORD=123456;psql -U dwtest -d dw -h hdp2 -c "set search_path=tds;select fn_regular_load ();"'三、Falcon简介
Apache Falcon 是一个面向Hadoop的、新的数据处理和管理平台,设计用于数据移动、数据管道协调、生命周期管理和数据发现。它使终端用户可以快速地将他们的数据及其相关的处理和管理任务“上载(onboard)”到Hadoop集群。Apache Falcon解决了大数据领域中一个非常重要和关键的问题。升级为顶级项目是该项目的一个重大进展。Apache Falcon有一个完善的路线图,可以减少应用程序开发和管理人员编写和管理复杂数据管理和处理应用程序的痛苦。
用户会发现,在Apache Falcon中,“基础设施端点(infrastructure endpoint)”、数据集(也称 Feed )、处理规则均是声明式的。这种声明式配置显式定义了实体之间的依赖关系。这也是该平台的一个特点,它本身只维护依赖关系,而并不做任何繁重的工作。所有的功能和工作流状态管理需求都委托给工作流调度程序来完成。
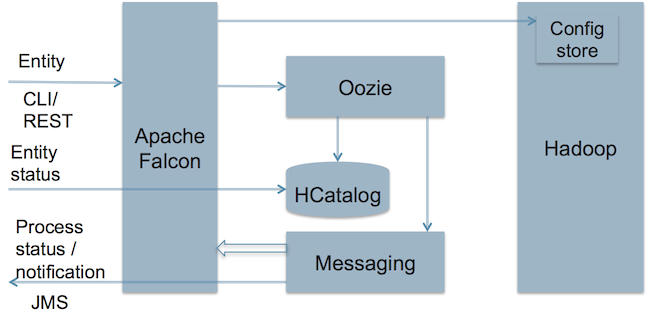
1. Falcon架构
图4是Falcon的架构图。
图4
从上图可以看出,Apache Falcon:
- 在Hadoop环境中各种数据和“处理元素(processing element)”之间建立了联系。
- 可以与Hive/HCatalog集成。
- 根据可用的Feed组向最终用户发送通知。
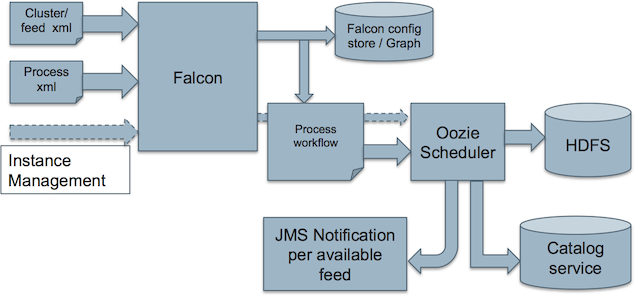
2. 调度器
Falcon选择Oozie作为缺省的调度器。Hadoop上的许多数据处理需要基于数据可用性或时间进行调度,当前Oozie本身就支持这些功能。同时Falcon系统又是开放的,可以整合其它调度器。Falcon process调度流程如图5所示。
图5
四、用Falcon process调度Oozie工作流自动执行
本示例中,只使用Falcon的process功能,调用前面定义的Oozie工作流定期自动执行。1. 启动Falcon服务
我的实验环境用的是HDP2.5.3,在安装之时就已经配置并启动了Falcon服务。2. 建立Falcon Cluster使用的HDFS目录
(1)建立目录hdfs dfs -mkdir -p /apps/falcon/primaryCluster
hdfs dfs -mkdir -p /apps/falcon/primaryCluster/staging
hdfs dfs -mkdir -p /apps/falcon/primaryCluster/workinghdfs dfs -chown -R falcon:users /apps/falcon/*hdfs dfs -chmod -R 777 /apps/falcon/primaryCluster/staging
hdfs dfs -chmod -R 755 /apps/falcon/primaryCluster/working 3. 建立Cluster
Falcon里的Cluster定义集群上各种资源的缺省访问点,还定义Falcon作业使用的缺省工作目录。在Falcon Web UI中,点击Create -> Cluster,在界面中填写Cluster相关信息,我的定义如下:- Cluster Name:集群的唯一标识,填写primaryCluster。
- Data Center or Colo Name:数据中心名称,填写primaryColo。
- Tags:标签用于对实体进行分组和定位,填写EntityType和Cluster。
- File System Read Endpoint Address:NameNode地址,填写hftp://hdp1:50070。
- File System Default Address:文件系统地址,我配置了HDFS HA,因此此处填写hdfs://mycluster。
- Yarn Resource Manager Address:YARN资源管理器地址,填写hdp2:8050。
- Workflow Address:工作流地址,填写http://hdp2:11000/oozie/
- Message Broker Address:消息代理地址,填写tcp://hdp2:61616?daemon=true。
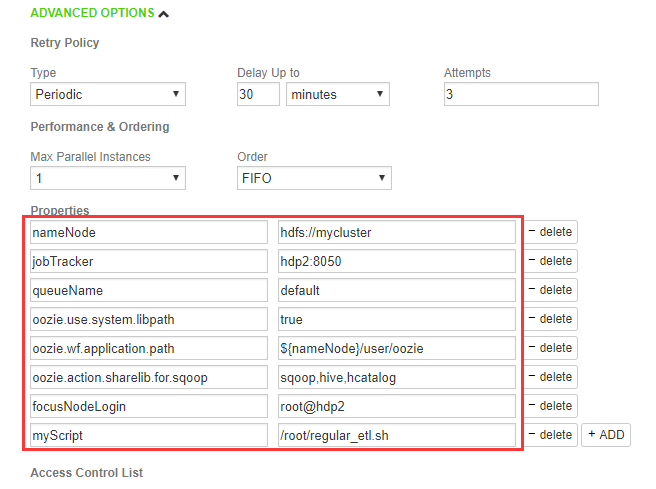
4. 建立process
在Falcon Web UI中,点击Create -> Process,在界面中填写Process相关信息,我的定义如下:- Process Name:处理名称,填写RegularETL。
- Engine:执行引擎,选择Oozie。
- Workflow Name:工作流名称,填写RegularETL。此名称是在Oozie的workflow.xml中定义的名称。
- Workflow Path:工作流目录,填写/user/oozie。该路径是workflow.xml文件所在的HDFS目录。
- Cluster:集群名称,选择primaryCluster。该集群是上一步建立的Cluster。
- Startd:执行开始时间,选2018/5/22 04:30 PM,下午4点半开始执行。
- End:执行结束时间,使用缺省的2099/12/31 11:59 AM。
- Repeat Every:重复执行周期,使用缺省的30 minutes,每半小时执行一次。本示例实际应该选1 Days,半小时执行一次主要方便看Process执行结果。
- Timezone:选择(GMT +8:00)。
图6
定义Falcon Process可以参考“ DEFINE AND PROCESS DATA PIPELINES IN HADOOP WITH APACHE FALCON”。
5. 执行process
首次执行process前,先将Sqoop的目标数据目录改为完全读写模式,否则可能报权限错误。这是初始化性质的一次性操作,之后不再需要这步。su - hdfs -c 'hdfs dfs -chmod -R 777 /data/rds'
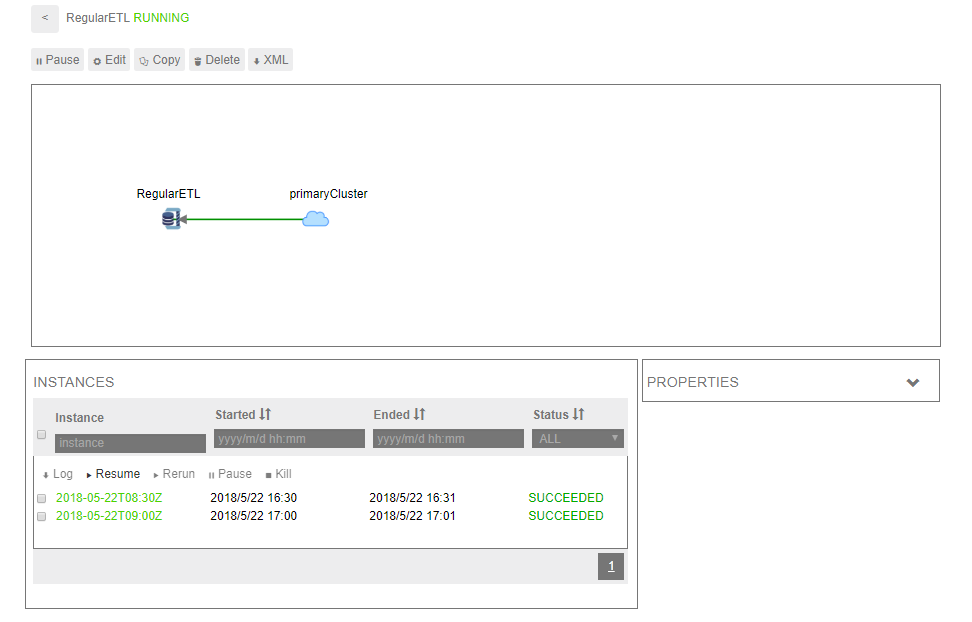
图7
在Oozie Web UI可以看到,Falcon在Oozie中自动创建了Workflow Job、Coordinator Job和Bundle Job,分别如图8、图9、图10所示。
图8
图9
图10