感知器(PLA——Perceptron Learning Algorithm),也叫感知机,处理的是机器学习中的分类问题,通过学习得到感知器模型来对新实例进行预测,因此属于判别模型。感知器于1957年提出,是神经网络的基础。
感知器模型
以最简单的二分类为例,假设医院需要根据肿瘤患者的病患特x1肿瘤大小,x2肿瘤颜色,判断肿瘤是良性(+1)还是恶性(-1),那么所有数据集都可以在一个二维空间表示;如果能找到一条直线将所有1和-1分开,这个数据集就是线性可分的,否则就是线性不可分。将两个特征向量分别用x1, x2表示,分隔直线的函数是:
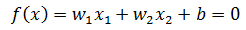
这里x1和x2都是变量。也许写成初中的直线方程更容易让人理解:

平面中每个点都由x,y两个坐标确定,所以也可以将y也看成自变量,用x1表示x,x2表示y:

感知器的模型函数:
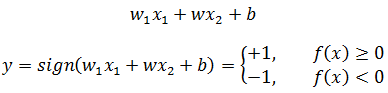
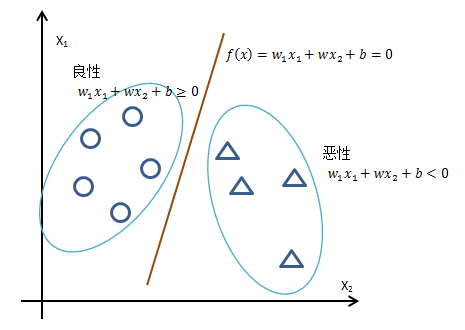
w和b称为感知器的模型参数。需要注意的是,上图中左右两侧的w1x1 + w2x2 + b不是直线,它们的x1和x2都是具体的特征值,是一个具体的实数数值;直线是f(x) = w1x1 + w2x2 + b = 0,它的x1和x2才是变量。
感知器需要做的就是根据训练集中的样本数据计算出恰当的w和b,以使得直线f(x) 最终能够正确地分开数据集中的所有1和-1(对于线性不可分问题是找到最好的直线以划分尽可能多的1和-1)。
感知器也可以扩展到多维数据,比如判断肿瘤时除了大小和颜色外还有发病时间、以前是否有过类似肿瘤等。对于三维空间,最终将找到一个平面;对于更多维的空间,最终将找到一个超平面。超平面是一个概念,可以将多维数据的正负例一分为二,但很难在平面媒体中呈现。
现在,对于n维空间的一个样本,xn表示一个样本中的第n个特征向量,wn表示xn对应的权重:
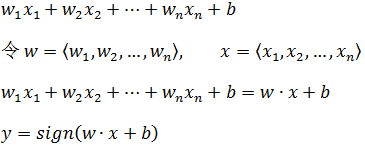
现在变成了w和x的点乘,可以看作多维空间的线性函数。
感知器的学习策略
为了计算最佳的w和b,需要制定一个学习策略,即定义一个用来计算误分类的损失函数,使损失函数极小化,从而通过优化的手段求解w。
现在设L(w,b)是损失函数,第一感觉很自然会将误分类数量作为损失函数:

上式表示在样本集中对于特定的感知器参数,共有k个样本被分错,x(i)表示误分类集中的第i个样本。然而这样做存在问题,该函数的结果可能是0,1,2,3……,是离散而非连续数据;因为L(w,b)不是连续的,不连续的函数必定不可导,不可导的函数也不易优化,所以没有办法根据这样的L(w,b)制定算法。(关于导数和利用导数求极值的问题,可参考《单变量微积分》系列中的相关章节)。
下面的图片由其他网友提供,忘记了来源,它很形象地说明了连续和可导的关系:

现在需要将L(w,b)变成连续函数,以分类点到直线超平面的总距离作为损失函数,每个误分类点到超平面的距离是:
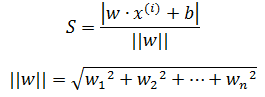
关于点到平面的距离可参考《线性代数笔记5——平面方程与矩阵》。
由于是误分类,所有正确结果是1的被判定为-1,-1的被判定为1,所以可以用下面的方法将绝对值符号去掉:
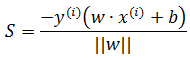
损失函数也就是所有误分类点的总距离:
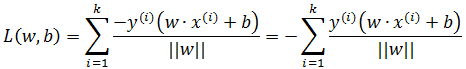
感知器是处理二分类的工作,它最终不关心超平面距离点的距离是多少,只关心结果是否正确,也就是说下面两条直线多于感知器来说是一样的:

由此可以去掉二阶范数:
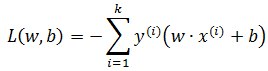
损失函数是非负的,如果没有误分类点,损失函数为0,误分类点越少,误分类点离超平面越近,损失函数越小,L(w,b)是w,b的连续可导函数。
感知器的学习算法
现在感知器学习问题转换为求解损失函数的最优化问题,也就是通过优化算法使得对于全体训练样本来说L(w,b)最小。具体来说,使用梯度下降法求解模型参数。关于梯度下降,可参考《ML(附录1)——梯度下降》。
闹心事太多,先到这里,待续。。。。
参考《统计学习方法》李航
作者:我是8位的
出处:http://www.cnblogs.com/bigmonkey
本文以学习、研究和分享为主,如需转载,请联系本人,标明作者和出处,非商业用途!
扫描二维码关注公众号“我是8位的”
