1、爬虫概念
模拟用户访问抓取网页内容并存储,执行“抓取”网页操作的工具称为爬虫
2、最简单的抓取网页的实现
import requests # package
req = requests.get(
'http://www.sina.com.cn/', # url, as you like
params={"wd": "find", "rn": "100"},
headers={'user-agent': 'Mozilla/5.0'}
)
req.encoding = "utf-8"
print(req.text)运行结果示例:

3、Scrapy简介
Scrapy是Python开发的高效抓取网页内容的框架,框架!可用于数据挖掘、监测和自动化测试!
官网API:https://docs.scrapy.org/en/latest/
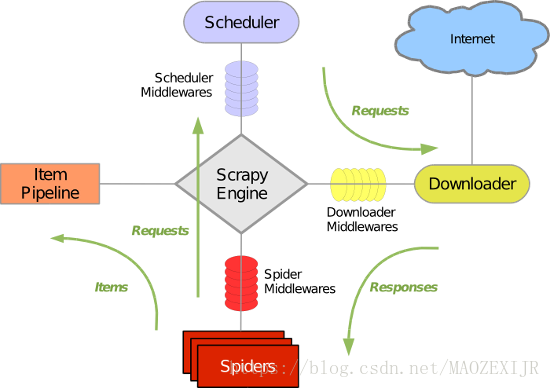
4、Scrapy框架组件
(1)Scrapy 引擎(Engine):核心模块,控制事件和数据流;(无需实现)
(2)调度器(Schedule):根据Url队列依次执行触发,接收爬虫给定的Url压入队列并去重;(无需实现)
(3)下载器(Downloader):发起Http请求(Request),接收应答内容(Response);(无需实现)
(4)爬虫(Spider):“抓取”实现的主要部分,指定爬取网页的Url,指定爬取规则;(按需实现)
(5)条目管道(Item Pipeline):从爬虫那里获取的数据,数据清洗、数据重构、数据保存;(按需实现)
(6)中间件(Middlewares):调度器中间件,下载器中间件,爬虫中间件,引导数据流转;(无需实现)
5、Scrapy执行流程
(1)调度器从引擎获取网址访问的Url队列
(2)引擎触发下载器依次请求和应答
(3)爬虫解析下载器过来的响应信息
(4)解析到的数据实体Item流转给管道
(5)解析到的Url传入调度器压入队列
6、Scrapy包导入
(1)方式一:命令行执行Pip,链接
(2)方式二:PyCharm支持,链接
7、生成Scrapy模板
参看另外一篇博客,《PyCharm创建scrapy项目》
8、开发自己的Spider
# -*- coding: utf-8 -*- import scrapy from scrapy.http import Request from scrapy.selector import HtmlXPathSelector class ModSpider(scrapy.spiders.Spider): # -*- coding: utf-8 -*- name = "mod" # you must define this variable and use its name start_urls = { "http://www.mod.gov.cn/" } allowed_domains = { ".mod.gov.cn" } def parse(self, response): # you must define this function and use its name # sel = Selector(response, "utf-8", "html") print("req: " + response.url) html = response.body_as_unicode() if html.find("H-20") > 0 or html.find("轰20") > 0: with open("d:/h20/html.txt", "a") as f: # append file content f.write(html) with open("d:/h20/url.txt", "a") as f: # append file content f.write(response.url + "\n")
(1)模块中spiders文件夹中新建自己的spider.py,如mod_spider.py
(2)定义Spider类,如ModSpider,必须继承自scrapy.spiders.Spider
(3)必须声明变量:name、start_urls、allowed_domain并赋值
(4)必须实现parse方法
9、运行一下
(1)命令行方式
找到PyCharm的Terminal,输入命令
1)cd 模块名
2)scrapy crawl 爬虫名 -- nolog
(--nolog表示不输出系统日志)
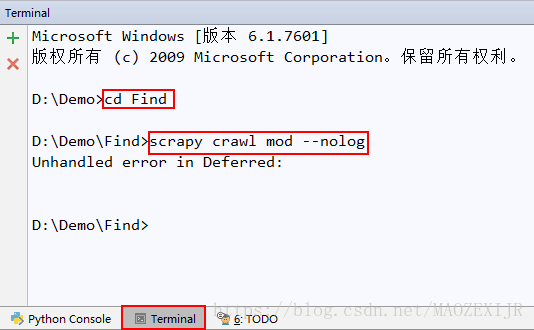
遇到"Unhandled error in Deferred"错误,这是因为缺少pywin32包
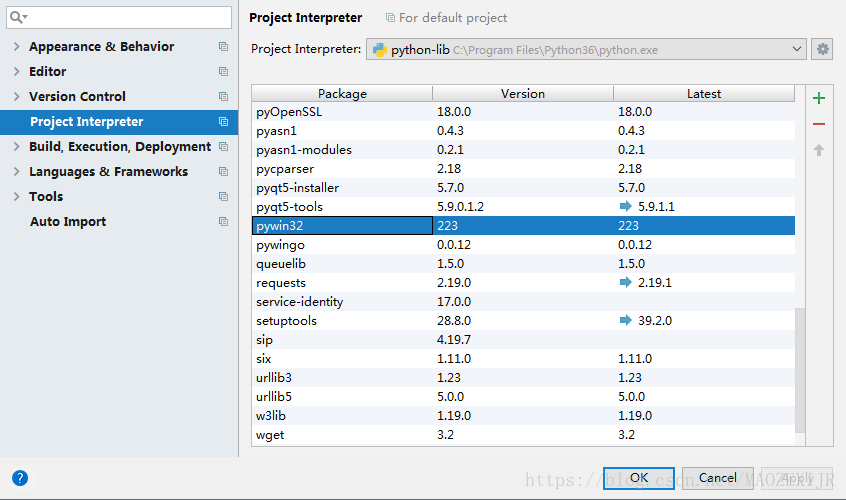
在File → Default Settings → Project Interpreter里选择Python安装路径下的解析器,如
C:\Program Files\Python36\python.exe
并增加pywin32的包
再次执行

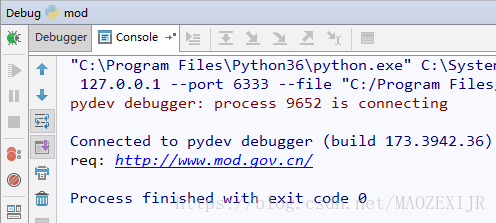
(2)Run/Debug方式
在Run/Debug Configs里配置
1)脚本路径:C:\Program Files\Python36\Lib\site-packages\scrapy\cmdline.py
2)运行参数:crawl 爬虫名 --nolog
3)工作路径:D:\Demo\Find\Find

点击执行Debug
9、Html元素筛选 — 选择器
(1)正则匹配方式查找需要的元素
(2)选择器
查询子子孙孙中的某个标签(以div标签为例)://div
查询儿子中的某个标签(以div标签为例):/div
查询标签中带有某个class属性的标签://div[@class=’c1′]即子子孙孙中标签是div且class=‘c1’的标签
查询标签中带有某个class=‘c1’并且自定义属性name=‘alex’的标签://div[@class=’c1′][@name=’alex’]
查询某个标签的文本内容://div/span/text() 即查询子子孙孙中div下面的span标签中的文本内容
查询某个属性的值(例如查询a标签的href属性)://a/@href
10、递归访问(深度遍历)
settings.py中 DEPTH_LIMIT=1来限定“递归”的层数
def parse(self, response): # you must define this function and use its name
hps = HtmlXPathSelector(response)
urls = hps.select('//a/@href').extract()
for href in urls:
if "" == href or "#" == href or href.startswith("javascript:"):
continue
elif href.startswith('http://') \
or href.startswith('https://') or href.startswith('www'):
yield Request(href, callback=self.parse)11、开发条目管道
12、模拟用户登录
13、使用Cookie
14、使用代理
参考链接