对于一个特殊的隐马尔科夫模型(HMM)及一个相应的观察序列,我们常常希望能找到生成此序列最可能的隐藏状态序列。
1.穷举搜索
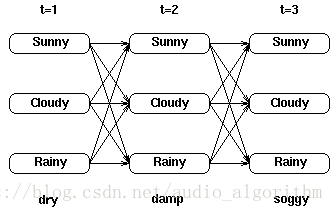
我们使用下面这张网格图片来形象化的说明隐藏状态和观察状态之间的关系:
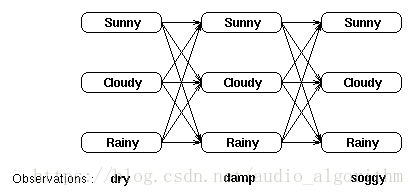
我们可以通过列出所有可能的隐藏状态序列并且计算对于每个组合相应的观察序列的概率来找到最可能的隐藏状态序列。最可能的隐藏状态序列是使下面这个概率最大的组合:
Pr(观察序列|隐藏状态的组合)
例如,对于网格中所显示的观察序列,最可能的隐藏状态序列是下面这些概率中最大概率所对应的那个隐藏状态序列:
Pr(dry,damp,soggy | sunny,sunny,sunny),Pr(dry,damp,soggy | sunny,sunny,cloudy), Pr(dry,damp,soggy |sunny,sunny,rainy), . . . . Pr(dry,damp,soggy | rainy,rainy,rainy)
这种方法是可行的,但是通过穷举计算每一个组合的概率找到最可能的序列是极为昂贵的。与前向算法类似,我们可以利用这些概率的时间不变性来降低计算复杂度。
2.使用递归降低复杂度
给定一个观察序列和一个隐马尔科夫模型(HMM),我们将考虑递归地寻找最有可能的隐藏状态序列。我们首先定义局部概率,它是到达网格中的某个特殊的中间状态时的概率。然后,我们将介绍如何在t=1和t=n(>1)时计算这些局部概率。
这些局部概率与前向算法中所计算的局部概率是不同的,因为它们表示的是时刻t时到达某个状态最可能的路径的概率,而不是所有路径概率的总和。
2a.局部概率‘s和局部最佳途径
考虑下面这个网格,它显示的是天气状态及对于观察序列干燥,湿润及湿透的一阶状态转移情况:
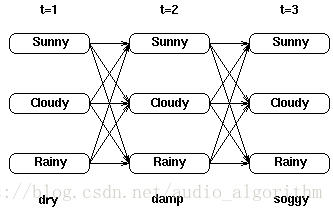
对于网格中的每一个中间及终止状态,都有一个到达该状态的最可能路径。举例来说,在t=3时刻的3个状态中的每一个都有一个到达此状态的最可能路径,或许是这样的:

因而(i,t)是t时刻到达状态i的所有序列概率中最大的概率,而局部最佳路径是得到此最大概率的隐藏状态序列。对于每一个可能的i和t值来说,这一类概率(及局部路径)均存在。
特别地,在t=T时每一个状态都有一个局部概率和一个局部最佳路径。这样我们就可以通过选择此时刻包含最大局部概率的状态及其相应的局部最佳路径来确定全局最佳路径(最佳隐藏状态序列)。
2b.计算t=1时刻的局部概率‘s
我们计算的局部概率是作为最可能到达我们当前位置的路径的概率(已知的特殊知识如观察概率及前一个状态的概率)。当t=1的时候,到达某状态的最可能路径明显是不存在的;但是,我们使用t=1时的所处状态的初始概率及相应的观察状态k1的观察概率计算局部概率;即
——与前向算法类似,这个结果是通过初始概率和相应的观察概率相乘得出的。
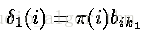
2c.计算t>1时刻的局部概率
现在我们来展示如何利用t-1时刻的局部概率计算t时刻的局部概率。
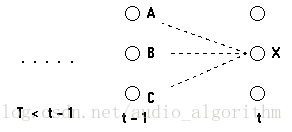
考虑如下的网格:
我们考虑计算t时刻到达状态X的最可能的路径;这条到达状态X的路径将通过t-1时刻的状态A,B或C中的某一个。
因此,最可能的到达状态X的路径将是下面这些路径的某一个
(状态序列),…,A,X
(状态序列),…,B,X
(状态序列),…,C,X
我们想找到路径末端是AX,BX或CX并且拥有最大概率的路径。
回顾一下马尔科夫假设:给定一个状态序列,一个状态发生的概率只依赖于前n个状态。特别地,在一阶马尔可夫假设下,状态X在一个状态序列后发生的概率只取决于之前的一个状态,即
Pr (到达状态A最可能的路径).Pr (X | A) . Pr (观察状态 | X)
与此相同,路径末端是AX的最可能的路径将是到达A的最可能路径再紧跟X。相似地,这条路径的概率将是:
Pr (到达状态A最可能的路径).Pr (X | A) . Pr (观察状态 | X)
因此,到达状态X的最可能路径概率是:
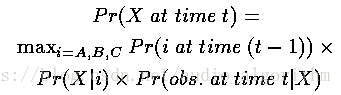
泛化上述公式,就是在t时刻,观察状态是kt,到达隐藏状态i的最佳局部路径的概率是:
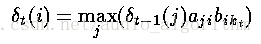
这里,我们假设前一个状态的知识(局部概率)是已知的,同时利用了状态转移概率和相应的观察概率之积。然后,我们就可以在其中选择最大的概率了(局部概率)。
2d.最佳途径
考虑下面这个网格
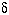 (i,t)。然而我们的目标是在给定一个观察序列的情况下寻找网格中最可能的隐藏状态序列——因此,我们需要一些方法来记住网格中的局部最佳路径。
(i,t)。然而我们的目标是在给定一个观察序列的情况下寻找网格中最可能的隐藏状态序列——因此,我们需要一些方法来记住网格中的局部最佳路径。
回顾一下我们是如何计算局部概率的,计算t时刻的‘s我们仅仅需要知道t-1时刻的‘s。在这个局部概率计算之后,就有可能记录前一时刻哪个状态生成了(i,t)——也就是说,在t-1时刻系统必须处于某个状态,该状态导致了系统在t时刻到达状态i是最优的。这种记录(记忆)是通过对每一个状态赋予一个反向指针完成的,这个指针指向最优的引发当前状态的前一时刻的某个状态。
形式上,我们可以写成如下的公式

其中argmax运算符是用来计算使括号中表达式的值最大的索引j的。
总结(Summary)
对于一个特定的隐马尔科夫模型,维特比算法被用来寻找生成一个观察序列的最可能的隐藏状态序列。我们利用概率的时间不变性,通过避免计算网格中每一条路径的概率来降低问题的复杂度。维特比算法对于每一个状态(t>1)都保存了一个反向指针(),并在每一个状态中存储了一个局部概率()。
局部概率是由反向指针指示的路径到达某个状态的概率。
当t=T时,维特比算法所到达的这些终止状态的局部概率‘s是按照最优(最可能)的路径到达该状态的概率。因此,选择其中最大的一个,并回溯找出所隐藏的状态路径,就是这个问题的最好答案。
关于维特比算法,需要着重强调的一点是它不是简单的对于某个给定的时间点选择最可能的隐藏状态,而是基于全局序列做决策——因此,如果在观察序列中有一个“非寻常”的事件发生,对于维特比算法的结果也影响不大。
这在语音处理中是特别有价值的,譬如当某个单词发音的一个中间音素出现失真或丢失的情况时,该单词也可以被识别出来。
维特比算法程序示例如下(在viterbi.c中):
void Viterbi(HMM *phmm, int T, int *O, double **delta, int **psi,int *q, double*pprob)
{
int i, j; /* state indices */
int t; /* time index */
intmaxvalind;
double maxval, val;
/* 1. Initialization */
for (i= 1; i <= phmm->N; i++)
{
delta[1][i] = phmm->pi[i] *(phmm->B[i][O[1]]);
psi[1][i] = 0;
}
/* 2.Recursion */
for (t = 2; t <= T; t++)
{
for (j = 1; j <=phmm->N; j++)
{
maxval = 0.0;
maxvalind = 1;
for (i = 1; i <= phmm->N; i++)
{
val = delta[t-1][i]*(phmm->A[i][j]);
if (val > maxval)
{
maxval = val;
maxvalind = i;
}
}
delta[t][j]= maxval*(phmm->B[j][O[t]]);
psi[t][j] = maxvalind;
}
}
/* 3. Termination */
*pprob= 0.0;
q[T] = 1;
for (i = 1; i <= phmm->N; i++)
{
if (delta[T][i] > *pprob)
{
*pprob = delta[T][i];
q[T] = i;
}
}
/* 4. Path (state sequence) backtracking */
for (t= T – 1; t >= 1; t–)
q[t] = psi[t+1][q[t+1]];
}
在UMDHMM包中所生成的4个可执行程序中,testvit是用来测试维特比算法的, 对于给定的观察符号序列及HMM,利用Viterbi 算法生成最可能的隐藏状态序列。这里我们利用UMDHMM包中test.hmm和test.seq来测试维特比算法,关于这两个文件,具体如下:
test.hmm:
——————————————————————–
M= 2
N= 3
A:
0.333 0.333 0.333
0.333 0.333 0.333
0.333 0.333 0.333
B:
0.5 0.5
0.75 0.25
0.25 0.75
pi:
0.333 0.333 0.333
——————————————————————–
test.seq:
——————————————————————–
T= 10
1 1 1 1 2 1 2 2 2 2
——————————————————————–
对于维特比算法的测试程序testvit来说,运行:
testvit test.hmm test.seq
结果如下:
————————————
Viterbi using log probabilities
Viterbi MLE log prob = -1.387295E+01
Optimal state sequence:
T= 10
2 2 2 2 3 2 3 3 3 3
————————————
The two log probabilites and optimal state sequences
should identical (within numerical precision).
序列“2 2 2 2 3 2 3 3 3 3”就是最终所找到的隐藏状态序列。