详细推导HMM算法+直观例子+项目应用
HMM模型介绍
本文将帮您深入浅出的彻底理解HMM模型架构和维特比算法,全文阅读大约需要10分钟,如果您希望亲自手推公式,则总耗时约20分钟。
本文为贪心学院课程的学习笔记,讲师为李文哲博士。
阅读本文需要概率论中的概率相关与不相关的基础知识。
模型解释
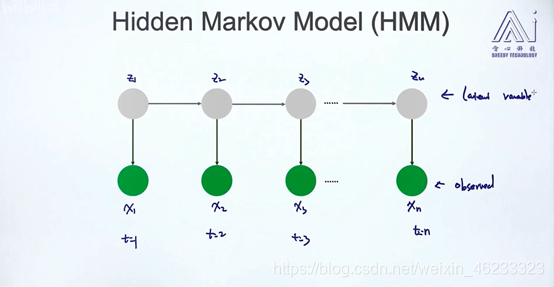
像图片,人脸特征之类的非时序数据是长度确定的,但时序数据的长度是不确定的,所以需要一个能动态接受数据的模型,因此提出了HMM和CRF,都是传统意义上的机器学习模型,后来深度学习领域在此基础上提出了RNN。
HMM结构如上图, 是隐式状态,每个隐式状态 下都会产生一个观测值 ,这就构成了HMM的模型框架。
这个模型是一个有向图(Directed)、生成模型(Gener model),当然也可以转换成判别模型。
举例
假设有两种不同的不均衡硬币AB,A出现证明的概率u1,B是u2。
现在做实验,有一个小明,他会按一定概率扔这两个硬币,假设我和小明之间有一道黑布,我无法观测到他扔了哪块硬币(即
),但是可以看到硬币正反(即观测值
)。
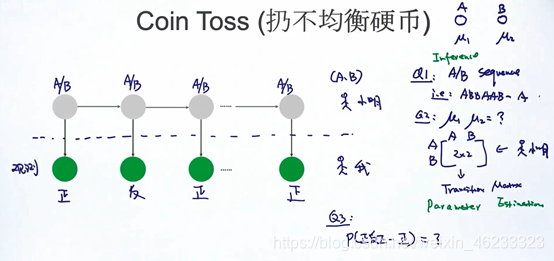
现在提出两个问题:
- 1、预测扔的哪个硬币(即decoding/inference problem——知道观测值,反推背后序列)
- 2、小明的扔硬币概率转移矩阵(parameter estimation——给定观测值,估计模型参数)
- 3、计算观测到 P(正反正反) 这个序列的概率(——计算边缘概率)
这就是HMM最核心的三个问题类型。
举例2
每个绿色的圈可以是单词,灰色的圈是词性,同样可以列出三个问题:
- Q1: 反推词性(decoding/inference)算法:维特比算法
- Q2:参数估计,给定一个词性,如“动词”,下面自己生成一个单词,即单词出现的概率,以及词性转换的概率.这个概率可能是由语法决定的,即估计词性转移矩阵和句子开始的时候是什么词性,用EM算法
- Q3:P(w1,w2,w3),即边缘概率
在接下来的学习中,我们会多次遇到这几个算法,没学过不用害怕,我们会详细推导他们。
模型建立
我们用
来表示HMM模型中的一切参数,下面将对参数进行解释,请看图:
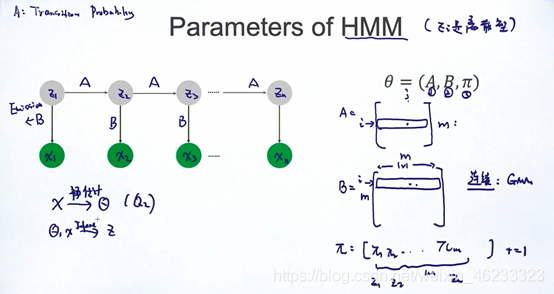
灰色圆圈,即状态,使用zi表示,绿色圆圈,即观测值,使用xi表示。
- A表示状态转移矩阵,aij表示从i到j的概率。
- B表示生成概率矩阵,代表从zi生成xi的概率,称为emission,bij代表在i状态下生成j字母的概率(也是HMM被叫做生成模型的原因,因为给定了参数,可以生成观测值)。
- π代表 “起始z1是什么 ‘’的概率,是一个向量。
当然,模型的观测值常常不是离散的,比如语音识别时,用户说的是一个连续波形,这个时候要借助GMM(高斯混合模型)把它变成离散的。
两种case
HMM模型要估计出θ的每个参数都是什么,针对这个问题,有两种不同的情况:
- complete case情况下,即已知x和他的标签z情况下求解问题,这个时候我们很容易能拿到参数,也就很好解决问题。
- incomplete case 下,不知道标签,要借助EM算法。
在下面的推导中我们也会根据不同的case选取不同方法。
维特比算法介绍与推导
维特比算法是一种很聪明的,针对complete case的算法。
在接下来的问题里,我们将一步步推导维特比算法。
问题1:已知θ,X,判断z。
即:已知观测值和一切参数,要推理隐藏值,即小明的硬币是什么,或者单词的词性是什么?
先考虑最笨的方法:把一切可能的z排列组合都列出来,再直接把一切参数代入,求一个可能性最大的z排列组合。
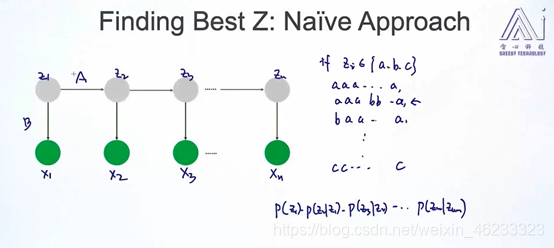
在这个算法里,算p(x|z)很方便,因为已知B矩阵,即生成矩阵,倒推z是容易的。
但因为排列组合可能性太多,是指数级复杂度,所以不是个好算法。
更好的算法:维特比算法。
本质上是动态规划,动态规划的本质是,本来是指数级别复杂度,但是我通过不断储存,减少重复运算,从而减少复杂度。
HMM的模型假设(限制条件)
先引入一个条件:
HMM的限制条件:zi只会和前后的zi-1或zi+1有关(倒序计算时和zi+1有关),从而减少可能性和计算量。
如果是网图,和其他剩余节点都有联系,那么即使使用维特比算法,复杂度也下不来。
图说维特比算法
维特比算法:寻找最好的z
路径图例:z1代表第二个状态,z2代表第一个状态…希望针对(列)1到m个观测值,选取最好的z。
路径连接节点,即可以表示观测值1到m对应的z
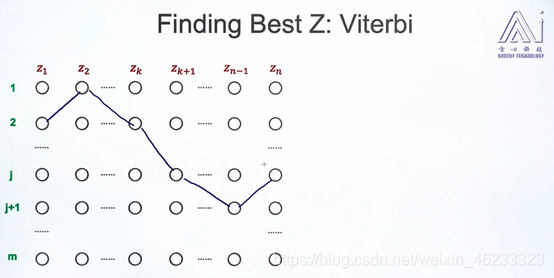
现在我要寻找最好的路径,就是连乘得到概率最大的路径。
计算方法:不断计算和更新路径的概率得分。概率大的路径就是最好的路径。
对于如图所示的路径,p(z1=2)可以通过
向量获得,此时观察值x1的概率也确定了,接下来p(z2=1|z1=1)也可以查θ得到。
因此,针对这样一个路径,总可以计算出概率得分。
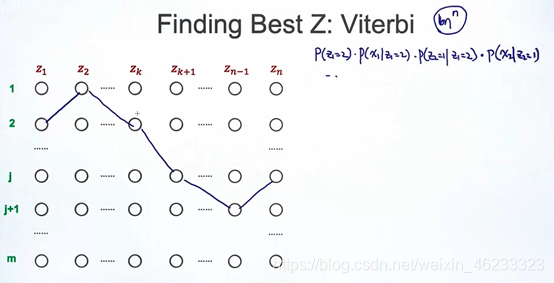
维特比算法:把原来的大问题拆分成子问题(也是动态规划的核心)
定义δk(i):给定了最后时刻的状态(第zk对应i状态),接下来最好路径的值。
δk(i)名为the score of the best path ending at state I at time k
δk+1(j)可以写成递归形式,因为前一个时刻可能来自很多东西。假设上一次来自δk(1)则概率是(log(p(zk+1=j|zk=1))+log(p(xk+1|zk+1)),(用log变加法),则针对不同的δk(i),可以写出矩阵:
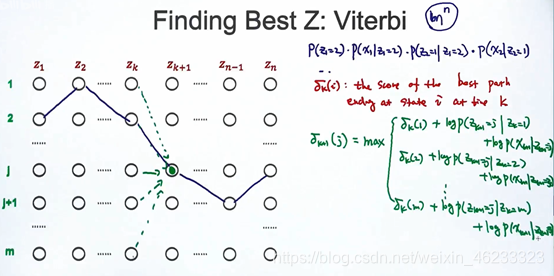
δk+1就是这所有可能取值里,max的一个。
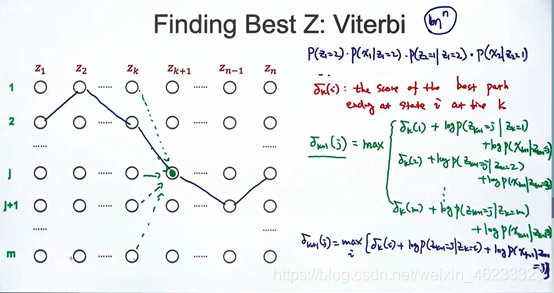
这就变成了经典的动态规划。
计算过程:
先列一个长m的表格用来记录δ,先填充第一列,然后填满第二列,不断接下去,把表格填满。
类似拿空间换时间,多了m*n矩阵。

在计算zn的时候,要用到zn-1,再用到zn-2,递归调用表中数据即可。
哈哈,今天先写到这里,剩下的明天写。
