CNN图像分类综合设计指南
昨天看到爱可可老师推送的一篇Hackernoon上的文章,是实打实的经验总结,读完感觉与我自己的实验经验差不多,但是比我总结的更详细,就翻译出来给大家看看吧。原文链接
https://hackernoon.com/a-comprehensive-design-guide-for-image-classification-cnns-46091260fb92
译者导言
这个博客基本相当于是综述,讲了一些设计CNN时的原则性问题,不适合完全没有炼丹经验的新手读,适合于有一定实验经验,但是困惑于究竟该如何设计网络的初级炼丹师们。在如何削减存储消耗部分只给出了几个论文,并没有进行详细讲解,所以最好还是去把原论文看一下,毕竟深度学习还是要多看论文多种实现才是最好的学习方式。
想完成图像分类任务但是不知该如何开始。例如选择哪个预训练网络?如何对其进行修改以适应自己的需求?是否应该使用20或100层的网络?哪个网络是最快的,哪个又是准确率最高的?当尝试为图像分类任务选择最佳的网络模型时这些均需要考虑。
当选择CNN来完成自己的图像分类任务时,有3个主要指标:精度、速度、存储消耗。这些性能指标取决于选择了哪个CNN网络以及做了何种修改。不同的神经网路例如VGG、Inception、Resnet都对着指标进行了各自的权衡。另外,你自己也可以进行修改,例如剪裁一些网络层、添加更多层、用更宽的网络或者使用不同的训练技巧等等。
这篇文章将是你针对自己任务设计CNN网络的设计指南。我们将着眼于精度、速度、存储消耗这三个主要指标。我们将审查一些不同的CNN网络,研究它们这三个指标。我们也将探讨我们可以对这些基础网络做何种修改,以及其如何影响这些指标。在最后我们将学习如何对特定的图像分类任务最优的设计CNN。
网络类型
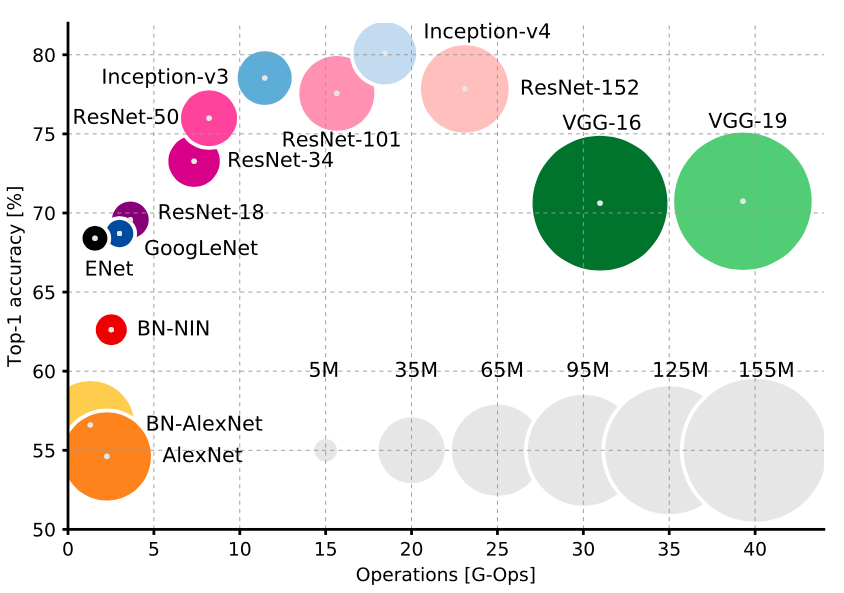
图中清晰的展示了这些网络对不同指标的权衡。首先我们应该选择Resnet或者Inception,它们比VGG和AlexNet更新同时在精度及速度上都比VGG更加优秀。斯坦福大学Justin Johnson提供了这写模型的benchmark
在Inception 和Resnet之间是真正的速度与准确率的权衡。想要准确率?用极深的Resnet。想要速度?用Inception
用聪明的卷积设计削减运行时内存消耗
近年来CNN发展出了一些方案削减运行时内存消耗,并且不会有很大的准确率损失。这些技巧能够十分容易的集成进任何CNN网络。
- MobileNets使用深度可分离卷积(depth-wise separable convolutions )极大的减小了运行时的计算消耗及储存消耗,但是只牺牲了1%到5%的准确率。这个牺牲程度取决于你想节省多少计算量。
- XNOR-Net使用二进制卷积例如卷积只有01两个值。在这个设计下网络高度稀疏因此易于压缩,不占用太大储存
- ShuffleNet使用逐点组卷积(pointwise group convolution)和通道随机(channel shuffle)在牺牲很少准确率的情况下极大的削减计算量,甚至比MobileNets做的更好。事实上,其能够以快10倍的速度实现以前的顶尖网络所达到的准确率。
- Network Pruning是个移除部分CNN网络的技术,其目的是在不减少准确率的情况下减少运行时间及存储消耗。为了维持准确率,移除的部分应该不影响最终输出。链接的这个文章展示了在Resnet上实现这个技术是多么容易。
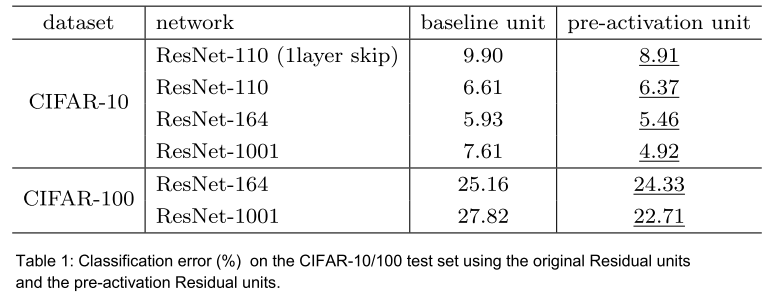
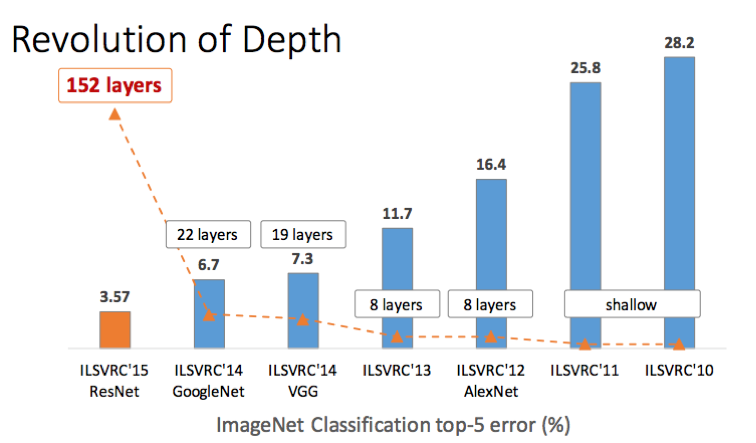
网络深度
容易想到,添加更多的层通常会提升准确率、降低速度、提升存储消耗。但是需要注意到层数越多,每层带来的准确率改善觉越少。
译者注:提升层数的性价比随着层数增加而变低。
激活函数
激活函数选取有很大争议,但是一个非常好的准则是从使用ReLU开始。使用ReLU经常能获得一个很好的结果,其略次于ELU, PReLU 或者 LeakyReLU,但是这些需要进行沉闷的调参。一但确定某网络设计在ReLU下工作的很好后,在考虑使用其他的激活函数,调整他们的参数来得到最后一点准确率提升。
译者注:这意味着更改激活函数是完成其他所有工作之后的事,不要一开始就使用ReLU以外的函数。
卷积核尺寸
可能有人会认为使用较大的卷积核将产生高准确率但是损失计算速度及存储空间,但是其实不是这样。已经多次发现使用大的卷积核使得网络难以衍化(译者注:难以训练)。更好的选择是堆叠较小的卷积核如3x3。ResNet和VGG都非常彻底的解释释并论证了这个结论。我们也可以向着两个论文做的一样,使用1x1卷积核作为bottleneck layers来削减特征图数量。
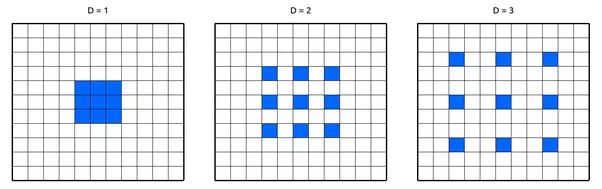
Dilated Convolutions
(扩张卷积 膨胀卷积 空洞卷积 这个翻译不统一)
Dilated convolutions使用卷积核内部有空间间隔的卷积来使用距离中心更远的信息。这使得在不增加参数情况下(存储消耗一点也不增长),网络的感受野指数增长。文章展示了使用Dilated convolutions能够改善网络准确率,而只有很小的速度降低。
数据增强
我们几乎必须做数据增强。使用更多的数据能够持续的改善性能,甚至是海量数据轻快下增加数据也能改善性能。使用数据增强,我们能够得到更多的数据。而数据增强的类型取决于应用的需求,例如我们不会遇到颠倒的树,车以及房子,所以对图像进行垂直翻转是没有意义的。但是我们总是会遇到天气变化产生的灯光影响,以及场景的变化。所以用灯光变化和水平翻转是有意义的。参见这个数据增强库
优化器
当训练网络时,有几个可选的优化算法。很多人说SGD能得到最好的准确率,经过我的实验发现确实如此。但是其调参是具有挑战性并且无聊的。但是另一方面,使用自适应学习率的算法例如Adam, Adagrad, or Adadelta很简单还很快,但是可能不会达到SGD所能达到的最高准确率。
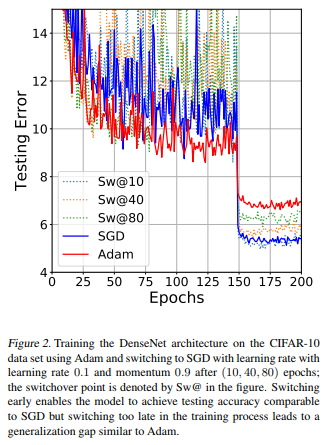
最好的方法是采用与选择激活函数时类似的策略:先用简单的看看我们设计的网络是不是work,然后调参以及使用复杂一些更复杂的方法。我个人建议从Adam开始,根据我的经验该算法及其好用:设置一个不太高的学习率,一般默认是0.0001(1e-4)就能够得到一个很好的结果!之后可以使用SGD从头开始,或者先用Adam,然后使用SGD微调。实际上这篇论文发现训练中从Adam切换到SGD能以最简单的方法达到最佳效果。
类别均衡
大多数情况下我们处理的是失衡数据(译者注:不平衡数据,不同类别数据量不一样,例如正例1000个,但反例只有100个),尤其是在真实的应用中。举个简单例子:为了安全原因,训练一个网络来预测视频中的某人是否拿着致命的武器。但是在你的训练数据里只有50个视频中有人拿着武器,1000个没有。如果仅仅使用这些数据来训练网络,网络将倾向于没有人拿枪!
(译者注:这是因为如果网络简单的判断没有人拿枪,在这总情况下也会有95.2%的准确率,将任何人判断为持枪都需要冒大幅降低准确率的风险)
我们有如下方法可以弥补:
- 加权:在损失函数中给不同类别使用不同权重。样本数量少的类在损失函数中占更大比重,这使得任何此类的任何误分类都会造成较大的损失。
- 过采样:对样本数量少的类别重复采样。该方法在可用数据较少是效果很好
- 欠采样:忽略一些样本量较大的类别总的数据。该方法在数据量极大时较好
- 数据增强:给样本较少的类别做数据增强
优化你的迁移学习
对大部应用来说,与从头开始训练相比,使用迁移学习更合适也更快。但是保留哪些层,那些层需要重新训练仍然是问题,这取决于你的数据集。你的数据越像用于预训练的数据集(大部分网络都用ImageNet做预训练),需要重新训练的层越少,反之亦然。例如,如果我们训练网络来判断图片中时候有葡萄,而我们有一组图片,部分有葡萄,其他的没有。这也图片和ImageNet数据集中图片很像,所以只需要重新训练最后的几层网络,甚至只训练最后的全连接层。但是如果你训练网络是为了判断外太空是否有某个行星,数据就和ImageNet很大程度不同,就需要重新训练一些后面的卷积层。简言之,遵从下面这个图: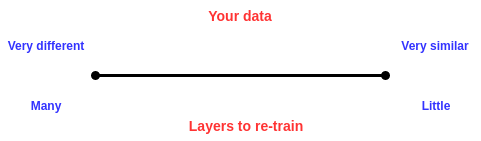
(译者注:网络的浅层大部分是不需要训练的,或者及其轻微的训练)
结论
你们已经有了!这是一个设计CNN的综合指南。希望你喜欢这个文章并且学到一些有用的东西。