CNN图像分类模型(一)——LeNet
一)简介
LeNet-5是一种用于手写体字符识别的非常高效的卷积神经网络,自论文Gradient-Based Learning Applied to Document Recognition,由Yann LeCun等人于1998年发表。LeNet模型虽然结构相对简单,但包含了深度学习的基本模块——卷积层,池化层,全链接层,是后续各类CNN识别模型的基础。
二)LeNet模型简介
LeNet-5网络结构
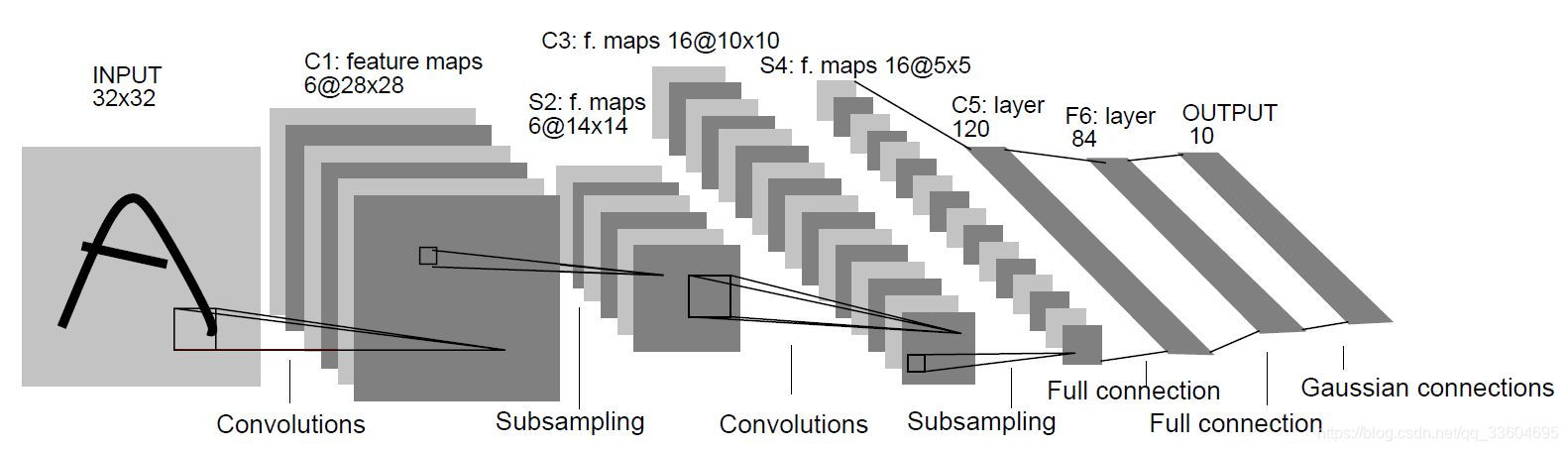
如图所示为LeNet-5网络的基本结构,一共由7层(不包含输入层):
0)输入层——32x32尺寸图像
1)C1——卷积层1
2)S2——池化层1
3)C3——卷积层2
4)S4——池化层2
5)C5——全连接层1
6)F6——全连接层2
7)输出层——全连接层2
2.1)输入图像
首先是图像输入层,输入灰度图像的尺寸归一化为32*32像素。
2.2)卷积层C1
卷积核大小:5x5(卷积核每次滑动一个像素,即stride=1)
卷积核个数:6
输出featuremap尺寸:28x28 (由32-5+1得来)
输出神经元的数量:28x28x6
可训练参数:(5x5+1) x 6(每个卷积核5x5个参数,另加一个bias参数,一共6个卷积核)
连接数(5x5+1)x28x28x6=122304
2.3)池化层S2
输入:C1输出的6通道featuremap(28x28x6)
池化窗口: 2x2
池化采样个数:6
池化方式:4个单元相加,乘以一个可训练参数,再加上一个bias,然后结果进行sigmoid映射
输出featuremap尺寸:14x14(长宽各减半)
输出神经元的数量:14x14x6
可训练参数:(1+1) x 6(池化核的比例、bias)
连接数(2x2+1)x14x14x6
2.4)卷积层C3
输入为S2输出的6通道featuremap
卷积核大小:5x5(卷积核每次滑动一个像素stride=1)
卷积核个数:16
输出featuremap尺寸:10x10 (由14-5+1得来)
输出神经元的数量:10x10x6
可训练参数/连接数:需考虑如下的组合方式
原文中对C3的说明:
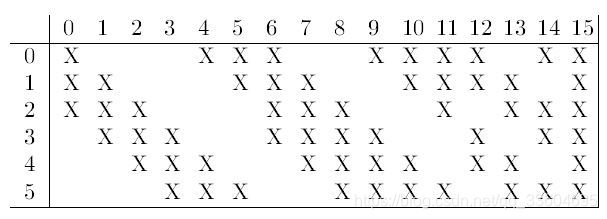
其中横坐标为C3的16个featuremap,纵坐标为上一层S2的6个featuremap。通过对S2中featuremap不用组合的卷积组合,卷积得到16个featuremap。
0-5的6个特征图,通过S2相邻的3个featuremap组合得到;
6-11的6个特征图,通过S2相邻的4个featuremap组合得到;
12-14的3个特征图,通过S2不相邻的4个featuremap组合得到;
15的1个特征图,通过S2的全部6个featuremap组合得到。
注:卷积核的厚度=被卷积的图像的通道数
卷积核的个数=卷积操作后输出的通道数
2.5)池化层S4
S4同S2相似,池化核个数增加到16
输出featuremap尺寸:5x5(长宽各减半)
输出神经元的数量:5x5x16
可训练参数:(1+1) x 16(池化核的比例、bias)
连接数(2x2+1)x5x5x16
2.6)全连接层C5(卷积层)
输入为S4输出的16通道featuremap
卷积核大小:5x5
卷积核种类:120
输出featuremap尺寸:1x1
可训练参数:(5x5x16+1)x120
2.7)全连接层F6
输入:120维向量
节点数:84
计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过sigmoid函数输出
训练参数/连接数:(120+1)x84

2.8)全连接层G7(输出层)
节点数:10(代表数字0-9)
连接方式:径向基函数 Euclidean Radial Basis Function (RBF)
训练参数/连接数:84x10
三)总结
关于LeNet模型,Tensorflow教程中的MNIST数据集是一个很好的练手选择。