这几天不是特别忙,就晚上抽空顺便对数据库这块做一个全面的梳理,写几篇博客将这些知识做一个记录,方便自己以后的复习和查阅也同时希望可以和更多的朋友交流。如有不当之处,希望大家不吝赐教。
1. 数据库介绍
问题:什么是数据库,它的作用是什么?
数据库是一个存储数据的仓库。它可以帮助我们将数据持久化保存。
IO流也可以帮助我们做持久化操作,使用数据库,其本质就是操作文件,也就是说,数据库底层就是使用文件系统来帮助我们存储数据,只不过,不需要在直接操作IO的API,而是通过数据库提供的语法来完成操作,这样比IO流更方便,效率更高。有了数据库,我们可以对数据进行CRUD操作
常见数据库
1. oracle 大型收费 在java开发中应用比较多。
2. sqlserver 微软 中大型收费
3. mysql 中小型 免费数据库开源
4. DB2 IBM大型收费
关系数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
数据库发展历程如下所示:
l 没有数据库,使用磁盘文件存储数据;
l 层次结构模型数据库;
l 网状结构模型数据库;
l 关系结构模型数据库,使用二维表格来存储数据;
l 关系-对象模型数据库;
我们今天要学习的MySQL就是关系结构模型数据库管理系统,简称关系型数据库管理系统
数据库管理系统(DBMS)

我们通常将数据库管理系统称为数据库,当我们安装了数据库(数据库服务器),就可以在数据库服务器中创建数据库,每个数据库中还可以包含多张表
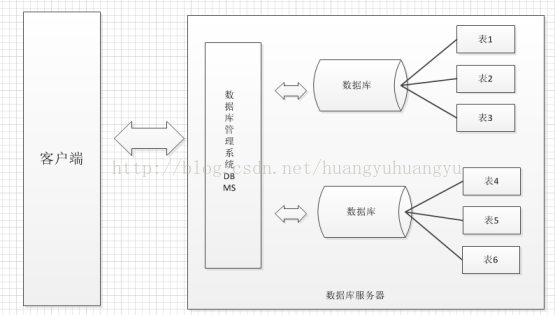
通过上述图我们知道了数据库与表之间的关系,那么我们的数据又是怎样存储在数据库中
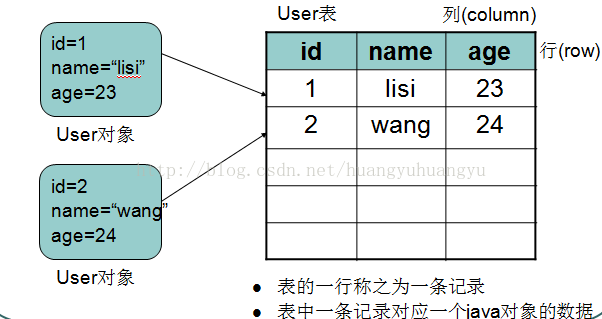
数据库中的表就是一个多行多列的表格。在创建表时,需要指定表的列数,以及列名称,列类型等信息。而不用指定表格的行数,行数是没有上限的。
表中的列我们称之为字段,表中的行我们称之为记录。
那么用我们熟悉的java程序来与关系型数据对比,就会发现以下对应关系。
类-------表
类中属性-------表中的字段
对象--------记录。
关于MySQL数据库的安装与卸载我就不在这篇文章中描述了,有需要的请看我的博客--MySQL的卸载与安装。1.SQL是什么,它的作用是什么
结构化查询语言(Structured Query Language)简称SQL,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系型数据库
2.SQL分类
SQL一共分成四类,如下所示:
1.数据定义语言:简称DDL(Data Definition Language),用来定义数据库对象:数据库,表,列等,例如创建、删除、修改:数据库、表结构等;
2.数据操作语言:简称DML(Data Manipulation Language),用来对数据库中表的记录进行更新,例如:增、删、改表记录;
3.数据控制语言:简称DCL(Data Control Language),用来定义数据库的访问权限和安全级别,及创建用户;
4.数据查询语言:简称DQL(Data Query Language),用来查询数据库中表的记录。
大家可能会对DDL和DML分的不太清楚,DDL是对数据库或表的结构进行操作,而DML是对表的记录进行操作(增、删、改)。以上四个分类,我们以后最常用的就是DDL、DML、DQL,其中,DQL是难点。
3.SQL语法
SQL的语法有以下要求:
1.SQL语句可以单行或多行书写,以分号结尾;
2.可使用空格和缩进来增强语句的可读性;
3.MySQL数据库的SQL语句不区分大小写,建议使用大写,例如:SELECT * FROM user。
库操作:
1. 创建数据库
格式1: create database 数据库名称;
格式2: create databse 数据库名称 character set 编码集
格式3 create database 数据库名称 character set 编码集COLLATE 校对
2. 查看数据库
Show databases; 查看当前服务器下所有数据库。
Show create database 数据库名称 查看当前指定的数据库的创建sql
3. 修改数据库
Alter databse 数据库名称 character set 字符集 collate 校对。
4. 删除数据库
Drop database 数据库名称
5. 其它操作
切换数据库
Use 数据库名称;
查看当前正在使用的数据库
Select database();
表操作
1. 创建表
Create table 表名(
字段名称 类型,
字段名称 类型,
……..
字段名称 类型
);
注意:最后一句的类型后面不用加“逗号”
2.创建表--指定字符集与校对
create table 表名(
字段1 类型,
字段2 类型,
.....
) character set 字符集 collate 校对;
3. 关于mysql中的创建表时的字段类型问题(重点)
在java中常见的数据类型
基本类型:
整型 byte short int long
浮点 float double
布尔 boolean
字符 char
引用类型
字符串 String
日期 Date
在mysql中与其对应:
TINYINT----byte
SMALLINT—short
INT-------------int
BIGINT--------long
在mysql中定义浮点也使用float double
在mysql中描述boolean类型,也是使用数值类型.
在mysql 中所谓字符与字符串是一样的。
Char : 它是定长的字符串 不会随着内容的长度变化而变化 效率 高,不节省表空间。
varchar: 它是可变长度的字符串,会随着内容的长度变化而变化,效率低,节省表空间
char与varchar区别?
char是一个定长字符串.指定长度不会随着内容的不足而改变
varchar是一个可变长度的字符串,它根据信息自动改变长度.(只在字符串长度小于指定长度情况下)
在mysql中如果一个字段是字符串类型,必须指定长度。
关于mysql中的日期类型
在jdk API中有这样的类
java.sql.Date java.sql.TimeStamp java.sql.Time
这三个类是java.util.Date的子类。
在mysql中的日期类型有:
Date 只包含年月日
Datetime 包含年月日时分秒
Time 时分秒
Timestamp 它代表的是一个时间戳(毫秒值)
Decimal,它也是浮点类型 decimal(5,2) 长度为5,小数点后保留两位。
Mysql中的大数据类型:
Blob-----在二进制
Tinyblob(255) blob(65536) mediumblob(16m) longblob(4g)
Clob----大文本类型 在mysql中它叫做text
Tinytext(255) text(65536) mediumtext(16m) longtext(4g)
| 类型 |
描述 |
| int |
整型,和java中的int类型一样; |
| double |
浮点型,例如double(5,2)表示该列存放的数据最多是5位,而且其中必须有2位小数,它的最大值是:999.99; |
| decimal |
浮点型,用于保存对准确精度有重要要求的值,例如与金钱有关的数据。 |
| char |
固定长度字符串类型,如果没有指定长度,默认长度是255,如果存储的字符没有达到指定长度,mysql将会在其后面用空格补足到指定长度; |
| varchar |
可变长度字符串类型,它的长度可以由我们自己指定,它能保存数据长度的最大值是65535,如果存储的字符没有达到指定的长度,不会补足到指定长度; |
| tinytext |
可变长度字符串类型,其存储范围是28-1B; |
| text |
也是可变长度字符串类型,其存储范围是216-1B; |
| mediumtext |
也是可变长度字符串类型,其存储范围是224-1B; |
| longtext |
也是可变长度字符串类型,其存储范围是232-1B; |
| tinyblob |
是可变长度二进制类型,其存储范围是28-1B; |
| blob |
是可变长度二进制类型,其存储范围是216-1B; |
| mediumblob |
也是可变长度二进制类型,其存储范围是224-1B; |
| longblob |
也是可变长度二进制类型,其存储范围是232-1B; |
| date |
日期类型,格式为yyyy-MM-dd,只有年月日,没有时分秒; |
| time |
时间类型,格式为hh:mm:ss,只有时分秒,没有年月日; |
| timestamp |
时间戳类型,格式为:yyyy-MM:dd hh:mm:ss,年月日,时分秒都有。 |
约束
它是用于限定表中字段。
我们在mysql课程中会介绍5种约束(注意:数据库中一共有六种约束,而mysql只支持五种)
1.主键约束
主键是用于标识当前记录的字段。它的特点是非空,唯一。
在开发中一般情况下主键是不具备任何意义,只是用于标识当前记录。
创建主键:
1.在创建表时,在字段后面加上 primary key.
create table tablename(
id int primary key,
.......
)
2.也可以表创建的最后来指定主键 create table tablename(
id int,
.......
primary key(id)
)
3.删除主键:alter table tablename drop primary key ;
2.唯一约束
某一列的值不为重复可以使用唯一约束. unique
3.非空约束
not null
4.默认值约束
default 值
5.外键约束(见MySQL(二))
6.check约束(mysql不支持)
表操作-查看修改删除表
查看表
查看表结构
desc表名;
查看当前数据库下所有表
show tables;
查看表的字符编码集
show create table 表名;
修改表
修改表的结构语法格式:alter table 表名 关键字 ….;
关键字有以下几个:
1.add----添加列操作 alter table 表名 add 列名 类型;
2.modify--修改列的类型 alter table 表名 modify 列名 类型;
3.drop --删除列 alter table 表名 drop 列名.
4.change--修改列名称 alter table 表名 change 旧列名 新列名 类型;
修改表的名称
rename table 旧表名 to 新表名;
修改表的字符编码集
alter table 表名 character set 字符集;
记录操作-insert操作
插入所有列值
insert into 表名(列名1,列名2, ...) values(列值1, 列值2, ...);
表名后面是当前表中所有字段名称
插入部分列值
insert into 表名(列名1,列名2) values(列值1, 列值2);
表名后面是当前表中部分字段名称
不指定列名
insert into 表名 values(列值1, 列值2, ...);
没有给出要插入的列,那么表示插入所有列;
值的个数必须是该表的列的个数;
值的顺序,必须与表创建时给出的列的顺序相同。
代码示例:
insert into user(id,username,password,gender,email,telephone,introduce,activecode,state,role,registTime) values(null,"james","123","male","[email protected]","13888888888","good boy","111",1,"admin",null);
插入操作注意事项
插入的数据应与字段的数据类型相同
数据的大小应该在列的长度范围内
在values中列出的数据位置必须与被加入的列的排列位置相对应。
1.除了数值类型外,其它的字段类型的值必须使用引号引起。
2.如果要插入空值,可以不写字段,或者插入 null.
3.注意:对于自动增长的列在操作时,直接插入null值即可.
记录操作-update操作
下面语句会将指定字段的值全部修改
update 表名 set 字段名称=值;
如果要修改多个字段
update 表名 set 字段1名称=值 ,字段2名称=值,...;
以上方式,进行修改,会将表中这个字段所有值都修改.
在实际开发中,对于修改操作,都是有条件修改.
update 表名 set 字段=值 ,... where 条件.
记录操作-delete操作
delete操作是删除数据.
格式 delete from 表名.
这会将表中所有数据删除。在开发一般情况下有条件删除
delete from 表名 where 条件.
关于删除表与删除表数据区别:
1.删除表 drop table 表名
2.删除表中记录
1.delete from 表名
2.truncate table 表名
关于delete 与truncate的区别?
1.delete是一行一行删除 truncate是将表结构销毁,在重新创建表结构.
如果数据比较多,truncate的性能高。
2.delete是dml语句 truncate dcl语句
delete是受事务控制. 可以回滚数据.
truncate是不受事务控制. 不能回滚.
记录操作-select基本查询
查询指定列
select 字段 from 表名;
查询指定字段信息,如果要查询多个字段
select 字段1,字段2,...from 表名;
查询所有列
select * from 表名;
查询表中所有字段.
注意:使用"*"在练习,学习过程中可以使用,在实际开发中,不建议使用。
去掉重复记录
select distinct 字段 from 表名;
distinct它的作用是去除重复.
使用别名
使用as 别名可以给表中的字段,表设置别名.
在查询中可以直接对列进行运算
我们在sql操作中,可以直接对列进行运算。
ifnull函数使用
在对数值类型的列做运算的时候,如果做运算的列的值为null的时,运算结果都为null,为了解决这个问题可以使用ifnull函数
代码示例:
1. 查询出所有商品信息
Select * FROM PRODUCTS;
2. 查询出所有商品的名称,价格,类别及数量信息
SELECT NAME,PRICE,CATEGORY,PNUM FROM PRODUCTS;
3. 查询出所有的商品类别
SELECT DISTINCT CATEGORY FROM PRODUCTS;
4. 查询出所有商品的名称及价格,将所有商品价格加10
SELECT NAME,ifnull(PRICE,0)+10 价格 from products;
5. 查询出每一个商品的总价及名称
Select ifnull(price,0)*ifnull(pnum,0) 总价,name from products;
记录操作-where子句
我们在开发中,使用select操作,一般都是有条件查询,那以我们介绍一下关于where子句的使用
格式 :select 字段 from 表名 where 条件;
where条件种类:
1.比较运算符
> >= < <= = !=(<>)
2.逻辑运算符
and or not
3.between ...and
相当于 >= and <=
注意:between 后面的值必须是小值 and后面的是大值
4.in
可以比较多个值
5.like
模糊查询
通配符使用:
1.% 匹配多个
2._ 匹配一个
6.null值操作
is null; 判断为空
is not null; 判断不为空
记录操作-order by排序
在开发中,我们从数据库中查询出的数据经常需要根据某些字段进行排序,可以使用order by关键字,后面跟的就是要排序的列
order by 子句是select的最后的一个子句。
asc 升序 (默认)
desc 降序
记录操作-聚合函数
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个单一的值;另外聚合函数会忽略空值。
今天我们学习如下五个聚合函数:
1.count:统计指定列不为NULL的记录行数;
2.sum:计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
3.max:计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
4.min:计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
5.avg:计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
记录操作-分组操作
分组查询是指使用group by字句对查询信息进行分组,例如:我们要统计出products表中所有分类商品的总数量,这时就需要使用group by 来对products表中的商品根据category进行分组操作.
分组后我们在对每一组数据进行统计。
分组操作中的having子名是用于在分组后对数据进行过滤的,作用类似于where条件。
笔试题: having与where的区别:
1.having是在分组后对数据进行过滤.
where是在分组前对数据进行过滤
2.having后面可以使用分组函数(统计函数)
where后面不可以使用分组函数。
代码示例:
1. 查询所有计算机类商品信息
select * from products where category=”计算机”;
2. 查询出商品价格大于90的商品信息
Select * from products where price>90;
3. 查询出商品总价大于10000的商品信息
Select * from products where (ifnull(price,0)*ifnull(pnum,0))>10000;
4. 查询出价格在100-200之间的商品信息
Select * from products where price>=100 and price<=200;
Select * from products where price between 100 and 200;
5. 查询出商品价格是65,100或190的商品信息
Select * from products where price in(65,100,190);
6. 查询出商品的名称中包含java的商品信息。
Select * from products where name like ‘%java%’;
7. 查询出书名是两个字的商品信息
Select * from products where name like “__”;
8. 查询出商品价格不为null商品信息
Select * from products where price is not null;
select * from product where not price is null;
记录操作总结
综合我们学习的查询相关关键字:select,from,where,group by,having,order by;它们的执行顺序是如下:
1.from:首先执行from,找到要查询的emp表;
2.where:判断条件,筛选出工资大于15000的所有记录;
3.group by:根据以上关键字执行的结果上对记录按照指定列进行分组
4.having:对分组后的信息进行筛选;
5.select:选择所需要的列信息;
6.order by:对查询信息进行排序。
在SQL语言中,第一个被处理的子句是from字句,尽管select字句最先出现,但是几乎总是最后被处理。