kNN近邻算法
邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。
模型基本原理与算法实现
下图中,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
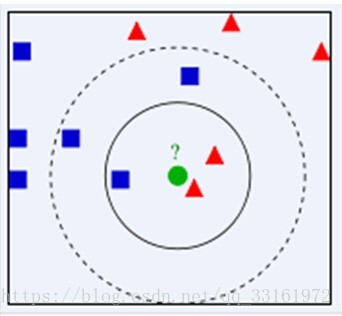
kNN近邻算法
(1)计算已知类别数据集中的点与当前点之间的距离;
(2)按照距离递增次序排序
(3)按照与当前点距离最小的k个点
(4)确定前k个点所在类别的出现频率
(5)返回前k个点出现频率最高的类别作为当前点的预测分类
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:
欧氏距离:
曼哈顿距离:
代码实现
def classify(inX, dataSet, labels, k):
inX=mat(inX)
dataSet=mat(dataSet)
labels=mat(labels)
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = array(diffMat)**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i],0]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]Kaggle——手写识别
Kaggle是由联合创始人、首席执行官安东尼·高德布卢姆(Anthony Goldbloom)2010年在墨尔本创立的,主要为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台。该平台已经吸引了80万名数据科学家的关注,这些用户资源或许正是吸引谷歌的主要因素。
数据集
手写识别数据集
训练集包含48000行数据,每行数据包含784个像素
测试集包含28000行数据,每行数据包含784个像素
每个图像的高度为28个像素,宽度为28个像素,总共为784个像素。每个像素都有与之相关联的单个像素值,指示该像素的亮度或暗度,较高的数字意味着较暗。这个像素值是0到255之间的整数。

数据集预处理
数据的导入
训练数据的导入
def loadTrainData():
l=[]
with open('train.csv') as file:
lines=csv.reader(file)
for line in lines:
l.append(line) #42001*785
l.remove(l[0])
l=array(l)
label=l[:,0]
data=l[:,1:]
return nomalizing(toInt(data)),toInt(label) #label 1*42000 data 42000*784测试数据的导入
def loadTestData():
l=[]
with open('test.csv') as file:
lines=csv.reader(file)
for line in lines:
l.append(line)
#28001*784
l.remove(l[0])
data=array(l)
return nomalizing(toInt(data)) # data 28000*784数据归一化处理
因每个像素是0-255之间的数表示该点的亮度,因为在识别数字时,数字每个点的亮度不影响数字的识别,所以将有数字的地方设为1。其余设为0。
def nomalizing(array):
m,n=shape(array)
for i in range(m):
for j in range(n):
if array[i,j]!=0:
array[i,j]=1
return array输出数据的保存
def saveResult(fileName,result):
fr = open(fileName,'w')
result1 = str(result)
#myWriter = fr.writelines(result1)
m = 0
for i in result:
temp=[]
temp.append(i)
m += 1
fr.write(str(m)+','+str(i)+'\n')
fr.close()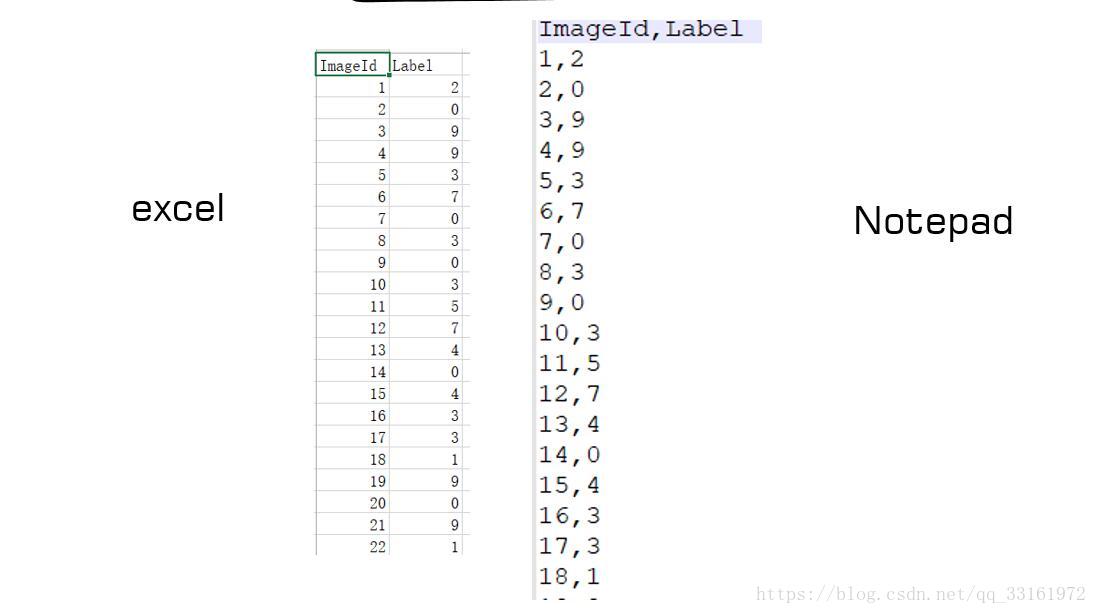
运行
def handwritingClassTest():
trainData,trainLabel=loadTrainData()
testData=loadTestData()
m,n=shape(testData)
errorCount=0
resultList=[]
for i in range(m):
classifierResult = classify(testData[i], trainData, trainLabel.transpose(), 5)
resultList.append(classifierResult)
print ("the classifier came back with: %d" % (classifierResult))
saveResult('result.csv',resultList)结果分析
经过接近8小时的运行终于得到了运算结果,将其提交到kaggle网站上得到正确率

可知knn算法准确率很高,但缺点就是需要逐一计算距离,当数据庞大时,识别效率便会降低。
代码
from numpy import *
import operator
import csv
def toInt(array):
array=mat(array)
m,n=shape(array)
newArray=zeros((m,n))
for i in range(m):
for j in range(n):
newArray[i,j]=int(array[i,j])
return newArray
def nomalizing(array):
m,n=shape(array)
for i in range(m):
for j in range(n):
if array[i,j]!=0:
array[i,j]=1
return array
def loadTrainData():
l=[]
with open('train.csv') as file:
lines=csv.reader(file)
for line in lines:
l.append(line) #42001*785
l.remove(l[0])
l=array(l)
label=l[:,0]
data=l[:,1:]
return nomalizing(toInt(data)),toInt(label) #label 1*42000 data 42000*784
def loadTestData():
l=[]
with open('test.csv') as file:
lines=csv.reader(file)
for line in lines:
l.append(line)
#28001*784
l.remove(l[0])
data=array(l)
return nomalizing(toInt(data)) # data 28000*784
#dataSet:m*n labels:m*1 inX:1*n
def classify(inX, dataSet, labels, k):
inX=mat(inX)
dataSet=mat(dataSet)
labels=mat(labels)
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = array(diffMat)**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i],0]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def saveResult(fileName,result):
fr = open(fileName,'w')
result1 = str(result)
#myWriter = fr.writelines(result1)
m = 0
for i in result:
temp=[]
temp.append(i)
m += 1
fr.write(str(m)+','+str(i)+'\n')
fr.close()
def handwritingClassTest():
trainData,trainLabel=loadTrainData()
testData=loadTestData()
m,n=shape(testData)
errorCount=0
resultList=[]
for i in range(m):
classifierResult = classify(testData[i], trainData, trainLabel.transpose(), 5)
resultList.append(classifierResult)
print ("the classifier came back with: %d" % (classifierResult))
saveResult('result.csv',resultList)
handwritingClassTest()
[1] 机器学习实战
[2] https://blog.csdn.net/qq_33323162/article/details/78126567