转载请注明出处:https://blog.csdn.net/qq_33427047/article/details/80393972
以TextCNN为例学习CNN
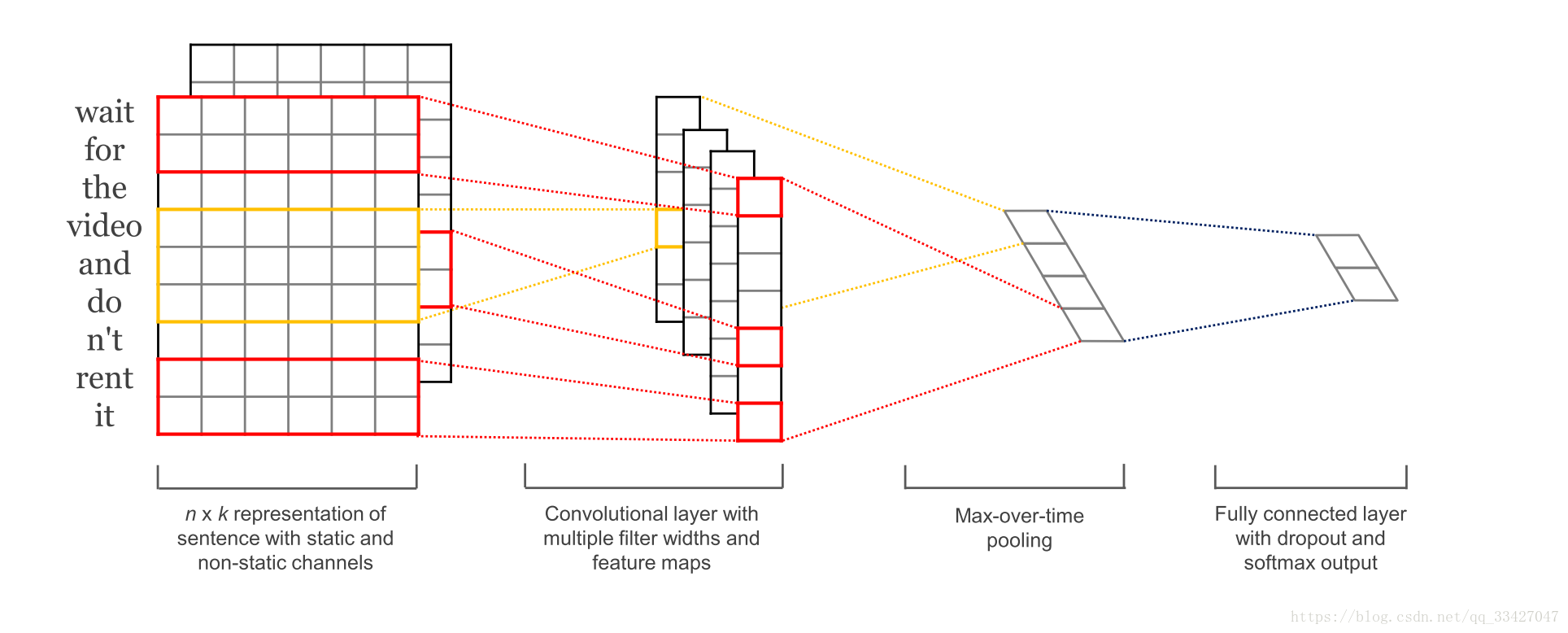
- TextCNN 是利用卷积神经网络对文本进行分类的算法,由 Yoon Kim 在 Convolutional Neural Networks for Sentence Classification 一文中提出. 是2014年的算法.
- CNN 的主要过程如下:
解读TextCNN
- TextCNN源码 https://github.com/dennybritz/cnn-text-classification-tf
- 以下1部分转载至 http://www.dataguru.cn/forum.php?mod=viewthread&tid=637971&extra=page=1&page=1
1 这个class的主要作用是什么?
TextCNN类搭建了一个最basic的CNN模型,有input layer,convolutional layer,max-pooling layer和最后输出的softmax layer.
但是又因为整个模型是用于文本的(而非CNN的传统处理对象:图像),因此在cnn的操作上相对应地做了一些小调整:
- 对于文本任务,输入层自然使用了word embedding来做input data representation
- 接下来是卷积层,大家在图像处理中经常看到的卷积核都是正方形的,比如4*4,然后在整张image上沿宽和高逐步移动进行卷积操作。但是nlp中输入的”image”是一个词矩阵,比如n个words,每个word用200维的vector表示的话,这个”image”就是n*200的矩阵,卷积核只在高度上已经滑动,在宽度上和word vector的维度一致(=200),也就是说每次窗口滑动过的位置都是完整的单词,不会将几个单词的一部分”vector”进行卷积,这也保证了word作为语言中最小粒度的合理性。(当然,如果研究的粒度是character-level而不是word-level,需要另外的方式处理)
- 由于卷积核和word embedding的宽度一致,一个卷积核对于一个sentence,卷积后得到的结果是一个vector, shape=(sentence_len - filter_window + 1, 1),那么,在max-pooling后得到的就是一个Scalar.所以,这点也是和图像卷积的不同之处,需要注意一下
- 正是由于max-pooling后只是得到一个scalar,在nlp中,会实施多个filter_window_size(比如3,4,5个words的宽度分别作为卷积的窗口大小),每个window_size又有num_filters个(比如64个)卷积核。一个卷积核得到的只是一个scalar太孤单了,智慧的人们就将相同window_size卷积出来的num_filter个scalar组合在一起,组成这个window_size下的feature_vector
- 最后再将所有window_size下的feature_vector也组合成一个single vector,作为最后一层softmax的输入
一个卷积核对于一个句子,convolution后得到的是一个vector;max-pooling后,得到的是一个scalar
总结一下这个类的作用就是:搭建一个用于文本数据的CNN模型!
2 模型参数
- 关于model
- filter_sizes: 3,4,5, Comma-separated filter sizes (default: ‘3,4,5’)
- num_filters: 128, Number of filters per filter size (default: 128)
- dropout_keep_prob: 0.5, Dropout keep probability (default: 0.5)
- l2_reg_lambda: 0.0, L2 regularization lambda (default: 0.0)
- 关于training
- batch_size: 64, Batch Size (default: 64)
- num_epochs: 200, Number of training epochs (default: 200)
- evaluate_every: 100, Evaluate model on dev set after this many steps (default: 100)
- checkpoint_every: 100, Save model after this many steps (default: 100)
- num_checkpoints: 5, Number of checkpoints to store (default: 5)
3 Dropout
- 正则是解决过拟合的问题,在最后一层softmax的时候是full-connected layer,因此容易产生过拟合.
- 策略就是在:
- 在训练阶段,对max-pooling layer的输出实行一些dropout,以概率p激活,激活的部分传递给softmax层.
- 在测试阶段,w已经学好了,但是不能直接用于unseen sentences,要乘以p之后再用,这个阶段没有dropout了全部输出给softmax层.
- 在训练阶段,对max-pooling layer的输出实行一些dropout,以概率p激活,激活的部分传递给softmax层.
4 Embedding Layer
# Embedding layer
with tf.device('/cpu:0'), tf.name_scope("embedding"):
self.W = tf.Variable(
# 所有词汇,每个词对应一个embedding_size的向量
tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0),
name="W")
# 将input_x中的每句话的每一个词都用embedding_size维的向量来表示
# 表示后的向量维度是:[input_x.shape[0], sequence_length, embedding_size]
self.embedded_chars = tf.nn.embedding_lookup(self.W, self.input_x)
# 因为卷积操作conv2d()需要输入的是四维数据,分别代表着批处理大小、宽度、高度、通道数。
# 而embedded_chars只有前三维,所以需要添加一维,设为1。变为:[input_x.shape[0], sequence_length, embedding_size, 1]
# [训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数]
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
存储全部word vector的矩阵W初始化时是随机random出来的,也就是paper中的第一种模型CNN-rand.
训练过程中并不是每次都会使用全部的vocabulary,而只是产生一个batch(batch中都是sentence,每个sentence标记了出现哪些word(较大长度为sequence_length),因此batch相当于一个二维列表),这个batch就是input_x.
self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name="input_x")- 1
tf.nn.embedding_lookup:查找input_x中所有的ids,获取它们的word vector。batch中的每个sentence的每个word都要查找。所以得到的embedded_chars的shape应该是[None, sequence_length, embedding_size] (1)
输入的word vectors得到之后,下一步就是输入到卷积层,用到 tf.nn.conv2d 函数
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)- 1
除去name参数用以指定该操作的name,与方法有关的一共五个参数:
input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一
filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4
padding: string类型的量,只能是”SAME”, “VALID”其中之一,这个值决定了不同的卷积方式
use_cudnn_on_gpu: bool类型,是否使用cudnn加速,默认为true
结果返回一个Tensor,这个输出,就是我们常说的feature map扫描二维码关注公众号,回复: 1958912 查看本文章
5 Conv and Max-pooling
# 卷积层、池化层
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# 卷积层
# 构建卷积核尺寸,输入和输出channel分别为1和num_filters
# 相当于CNN中的卷积核,它要求是一个Tensor,
# 具有[filter_height, filter_width, in_channels, out_channels]这样的shape,
# 具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],
# 要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
filter_shape = [filter_size, embedding_size, 1, num_filters]
# 矩阵内积 + 偏置 : W * X + b
# W 就是卷积核
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(
# [训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数]
self.embedded_chars_expanded,
W,
# 卷积时在图像每一维的步长,这是一个一维的向量,长度4
strides=[1, 1, 1, 1],
# string类型的量,只能是”SAME”,”VALID”其中之一,这个值决定了不同的卷积方式
padding="VALID",
name="conv")
# 做完卷积之后,矩阵大小为 [None, sequence_length - filter_size + 1, 1, num_filters]
# 非线性操作,激活函数:relu(W*x + b)
# h 是对卷积结果进行非线性转换之后的结果
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# 最大池化, 选取卷积结果的最大值pooled的尺寸为[None, 1, 1, 128](卷积核个数)
# 本质上是一个特征向量,最后一个维度是特征代表数量
pooled = tf.nn.max_pool(
h, # 待池化的四维张量,维度是[batch, height, width, channels]
# 池化窗口大小,长度(大于)等于4的数组,与value的维度对应,
# 一般为[1,height,width,1],batch和channels上不池化
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_outputs.append(pooled)
# pooled_outputs最终为一个长度为3的列表。每一个元素都是[None,1,1,128]的Tensor张量
# 对每个卷积核重复上述操作,故pooled_outputs的数组长度应该为len(filter_sizes)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
一个卷积核对于一个句子,convolution后得到的是一个vector;max-pooling后,得到的是一个scalar
以上是一个filter_size的结果(比如filter_size = 3),pooled存储的是当前filter_size下每个sentence最重要的num_filters个features,结果append到pooled_outputs列表中存起来,再对下一个filter_size进行相同的操作。
等到for循环结束时,也就是所有的filter_size全部进行了卷积和max-pooling之后,首先需要把相同filter_size的所有pooled结果concat起来,再将不同的filter_size之间的结果concat起来,最后的到的应该类似于二维数组,[batch, all_pooled_result]
# Combine all the pooled features
# 将所有window_size下的feature_vector也组合成一个single vector,作为最后一层softmax的输入
# 因为3种filter卷积池化之后是一个scalar, 共有
num_filters_total = num_filters * len(filter_sizes)
# 对pooled_outputs在第四个维度上进行合并,变成一个[None,1,1,384]Tensor张量
# 将不同核产生的计算结果(features)拼接起来
# tf.concat(values, concat_dim)连接values中的矩阵,concat_dim指定在哪一维(从0计数)连接
self.h_pool = tf.concat(pooled_outputs, 3)
# 把每一个max-pooling之后的张量合并起来之后得到一个长向量 [batch_size, num_filters_total]
# 展开成两维Tensor[None,384]
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
6 Dropout
# 是cnn中最流行的正则化方法
# dropout layer随机地选择一些神经元,使其失活。
# 这样可以阻止co-adapting,迫使它们每一个都学习到有用的特征。
# 失活的神经单元个数由dropout_keep_prob 决定。在训练的时候设为 0.5 ,测试的时候设为 1 (disable dropout)
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)- 1
- 2
- 3
- 4
- 5
- 6
7 Output
# 全连接层计算输出向量(w*h+b)和预测(scores向量中的最大值即为预测结果);其实是个softmax分类器
with tf.name_scope("output"):
W = tf.get_variable(
"W",
shape=[num_filters_total, num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
8 Loss function
得到了整个网络的输出之后,也就是得到了y_prediction,但还需要和真实的y label进行比较,以此来确定预测好坏
# 损失函数
# Calculate Mean cross-entropy loss 计算scores和input_y的交叉熵损失函数
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.scores, labels=self.input_y)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss- 1
- 2
- 3
- 4
- 5
还是使用常规的cross_entropy作为loss function。最后一层是全连接层,为了防止过拟合,最后还要在loss func中加入l2正则项,即l2_loss。l2_reg_lambda来确定惩罚的力度
9 Accuracy
# Accuracy
# Accuracy计算准确度,预测和真实标签相同即为正确
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")- 1
- 2
- 3
- 4
- 5
tf.equal(x, y)返回的是一个bool tensor,如果xy对应位置的值相等就是true,否则false。得到的tensor是[batch, 1]的.
tf.cast(x, dtype)将bool tensor转化成float类型的tensor,方便计算.
tf.reduce_mean()本身输入的就是一个float类型的vector(元素要么是0.0,要么是1.0),直接对这样的vector计算mean得到的就是accuracy.
以TextCNN为例学习CNN
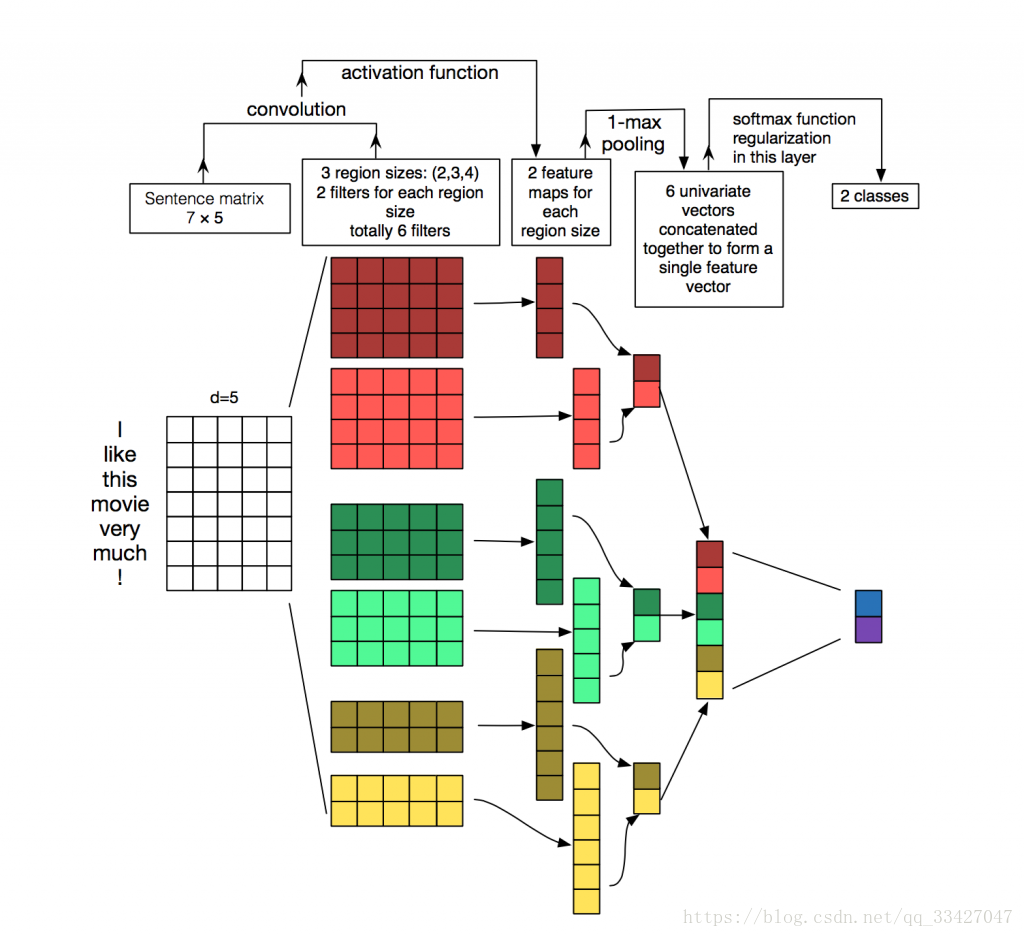
- TextCNN 是利用卷积神经网络对文本进行分类的算法,由 Yoon Kim 在 Convolutional Neural Networks for Sentence Classification 一文中提出. 是2014年的算法.
- CNN 的主要过程如下:
解读TextCNN
- TextCNN源码 https://github.com/dennybritz/cnn-text-classification-tf
- 以下1部分转载至 http://www.dataguru.cn/forum.php?mod=viewthread&tid=637971&extra=page=1&page=1
1 这个class的主要作用是什么?
TextCNN类搭建了一个最basic的CNN模型,有input layer,convolutional layer,max-pooling layer和最后输出的softmax layer.
但是又因为整个模型是用于文本的(而非CNN的传统处理对象:图像),因此在cnn的操作上相对应地做了一些小调整:
- 对于文本任务,输入层自然使用了word embedding来做input data representation
- 接下来是卷积层,大家在图像处理中经常看到的卷积核都是正方形的,比如4*4,然后在整张image上沿宽和高逐步移动进行卷积操作。但是nlp中输入的”image”是一个词矩阵,比如n个words,每个word用200维的vector表示的话,这个”image”就是n*200的矩阵,卷积核只在高度上已经滑动,在宽度上和word vector的维度一致(=200),也就是说每次窗口滑动过的位置都是完整的单词,不会将几个单词的一部分”vector”进行卷积,这也保证了word作为语言中最小粒度的合理性。(当然,如果研究的粒度是character-level而不是word-level,需要另外的方式处理)
- 由于卷积核和word embedding的宽度一致,一个卷积核对于一个sentence,卷积后得到的结果是一个vector, shape=(sentence_len - filter_window + 1, 1),那么,在max-pooling后得到的就是一个Scalar.所以,这点也是和图像卷积的不同之处,需要注意一下
- 正是由于max-pooling后只是得到一个scalar,在nlp中,会实施多个filter_window_size(比如3,4,5个words的宽度分别作为卷积的窗口大小),每个window_size又有num_filters个(比如64个)卷积核。一个卷积核得到的只是一个scalar太孤单了,智慧的人们就将相同window_size卷积出来的num_filter个scalar组合在一起,组成这个window_size下的feature_vector
- 最后再将所有window_size下的feature_vector也组合成一个single vector,作为最后一层softmax的输入
一个卷积核对于一个句子,convolution后得到的是一个vector;max-pooling后,得到的是一个scalar
总结一下这个类的作用就是:搭建一个用于文本数据的CNN模型!
2 模型参数
- 关于model
- filter_sizes: 3,4,5, Comma-separated filter sizes (default: ‘3,4,5’)
- num_filters: 128, Number of filters per filter size (default: 128)
- dropout_keep_prob: 0.5, Dropout keep probability (default: 0.5)
- l2_reg_lambda: 0.0, L2 regularization lambda (default: 0.0)
- 关于training
- batch_size: 64, Batch Size (default: 64)
- num_epochs: 200, Number of training epochs (default: 200)
- evaluate_every: 100, Evaluate model on dev set after this many steps (default: 100)
- checkpoint_every: 100, Save model after this many steps (default: 100)
- num_checkpoints: 5, Number of checkpoints to store (default: 5)
3 Dropout
- 正则是解决过拟合的问题,在最后一层softmax的时候是full-connected layer,因此容易产生过拟合.
- 策略就是在:
- 在训练阶段,对max-pooling layer的输出实行一些dropout,以概率p激活,激活的部分传递给softmax层.
- 在测试阶段,w已经学好了,但是不能直接用于unseen sentences,要乘以p之后再用,这个阶段没有dropout了全部输出给softmax层.
- 在训练阶段,对max-pooling layer的输出实行一些dropout,以概率p激活,激活的部分传递给softmax层.
4 Embedding Layer
# Embedding layer
with tf.device('/cpu:0'), tf.name_scope("embedding"):
self.W = tf.Variable(
# 所有词汇,每个词对应一个embedding_size的向量
tf.random_uniform([vocab_size, embedding_size], -1.0, 1.0),
name="W")
# 将input_x中的每句话的每一个词都用embedding_size维的向量来表示
# 表示后的向量维度是:[input_x.shape[0], sequence_length, embedding_size]
self.embedded_chars = tf.nn.embedding_lookup(self.W, self.input_x)
# 因为卷积操作conv2d()需要输入的是四维数据,分别代表着批处理大小、宽度、高度、通道数。
# 而embedded_chars只有前三维,所以需要添加一维,设为1。变为:[input_x.shape[0], sequence_length, embedding_size, 1]
# [训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数]
self.embedded_chars_expanded = tf.expand_dims(self.embedded_chars, -1)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
存储全部word vector的矩阵W初始化时是随机random出来的,也就是paper中的第一种模型CNN-rand.
训练过程中并不是每次都会使用全部的vocabulary,而只是产生一个batch(batch中都是sentence,每个sentence标记了出现哪些word(较大长度为sequence_length),因此batch相当于一个二维列表),这个batch就是input_x.
self.input_x = tf.placeholder(tf.int32, [None, sequence_length], name="input_x")- 1
tf.nn.embedding_lookup:查找input_x中所有的ids,获取它们的word vector。batch中的每个sentence的每个word都要查找。所以得到的embedded_chars的shape应该是[None, sequence_length, embedding_size] (1)
输入的word vectors得到之后,下一步就是输入到卷积层,用到 tf.nn.conv2d 函数
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)- 1
除去name参数用以指定该操作的name,与方法有关的一共五个参数:
input:指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个4维的Tensor,要求类型为float32和float64其中之一
filter:相当于CNN中的卷积核,它要求是一个Tensor,具有[filter_height, filter_width, in_channels, out_channels]这样的shape,具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
strides:卷积时在图像每一维的步长,这是一个一维的向量,长度4
padding: string类型的量,只能是”SAME”, “VALID”其中之一,这个值决定了不同的卷积方式
use_cudnn_on_gpu: bool类型,是否使用cudnn加速,默认为true
结果返回一个Tensor,这个输出,就是我们常说的feature map
5 Conv and Max-pooling
# 卷积层、池化层
pooled_outputs = []
for i, filter_size in enumerate(filter_sizes):
with tf.name_scope("conv-maxpool-%s" % filter_size):
# 卷积层
# 构建卷积核尺寸,输入和输出channel分别为1和num_filters
# 相当于CNN中的卷积核,它要求是一个Tensor,
# 具有[filter_height, filter_width, in_channels, out_channels]这样的shape,
# 具体含义是[卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],
# 要求类型与参数input相同,有一个地方需要注意,第三维in_channels,就是参数input的第四维
filter_shape = [filter_size, embedding_size, 1, num_filters]
# 矩阵内积 + 偏置 : W * X + b
# W 就是卷积核
W = tf.Variable(tf.truncated_normal(filter_shape, stddev=0.1), name="W")
b = tf.Variable(tf.constant(0.1, shape=[num_filters]), name="b")
conv = tf.nn.conv2d(
# [训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数]
self.embedded_chars_expanded,
W,
# 卷积时在图像每一维的步长,这是一个一维的向量,长度4
strides=[1, 1, 1, 1],
# string类型的量,只能是”SAME”,”VALID”其中之一,这个值决定了不同的卷积方式
padding="VALID",
name="conv")
# 做完卷积之后,矩阵大小为 [None, sequence_length - filter_size + 1, 1, num_filters]
# 非线性操作,激活函数:relu(W*x + b)
# h 是对卷积结果进行非线性转换之后的结果
h = tf.nn.relu(tf.nn.bias_add(conv, b), name="relu")
# 最大池化, 选取卷积结果的最大值pooled的尺寸为[None, 1, 1, 128](卷积核个数)
# 本质上是一个特征向量,最后一个维度是特征代表数量
pooled = tf.nn.max_pool(
h, # 待池化的四维张量,维度是[batch, height, width, channels]
# 池化窗口大小,长度(大于)等于4的数组,与value的维度对应,
# 一般为[1,height,width,1],batch和channels上不池化
ksize=[1, sequence_length - filter_size + 1, 1, 1],
strides=[1, 1, 1, 1],
padding='VALID',
name="pool")
pooled_outputs.append(pooled)
# pooled_outputs最终为一个长度为3的列表。每一个元素都是[None,1,1,128]的Tensor张量
# 对每个卷积核重复上述操作,故pooled_outputs的数组长度应该为len(filter_sizes)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
一个卷积核对于一个句子,convolution后得到的是一个vector;max-pooling后,得到的是一个scalar
以上是一个filter_size的结果(比如filter_size = 3),pooled存储的是当前filter_size下每个sentence最重要的num_filters个features,结果append到pooled_outputs列表中存起来,再对下一个filter_size进行相同的操作。
等到for循环结束时,也就是所有的filter_size全部进行了卷积和max-pooling之后,首先需要把相同filter_size的所有pooled结果concat起来,再将不同的filter_size之间的结果concat起来,最后的到的应该类似于二维数组,[batch, all_pooled_result]
# Combine all the pooled features
# 将所有window_size下的feature_vector也组合成一个single vector,作为最后一层softmax的输入
# 因为3种filter卷积池化之后是一个scalar, 共有
num_filters_total = num_filters * len(filter_sizes)
# 对pooled_outputs在第四个维度上进行合并,变成一个[None,1,1,384]Tensor张量
# 将不同核产生的计算结果(features)拼接起来
# tf.concat(values, concat_dim)连接values中的矩阵,concat_dim指定在哪一维(从0计数)连接
self.h_pool = tf.concat(pooled_outputs, 3)
# 把每一个max-pooling之后的张量合并起来之后得到一个长向量 [batch_size, num_filters_total]
# 展开成两维Tensor[None,384]
self.h_pool_flat = tf.reshape(self.h_pool, [-1, num_filters_total])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
6 Dropout
# 是cnn中最流行的正则化方法
# dropout layer随机地选择一些神经元,使其失活。
# 这样可以阻止co-adapting,迫使它们每一个都学习到有用的特征。
# 失活的神经单元个数由dropout_keep_prob 决定。在训练的时候设为 0.5 ,测试的时候设为 1 (disable dropout)
with tf.name_scope("dropout"):
self.h_drop = tf.nn.dropout(self.h_pool_flat, self.dropout_keep_prob)- 1
- 2
- 3
- 4
- 5
- 6
7 Output
# 全连接层计算输出向量(w*h+b)和预测(scores向量中的最大值即为预测结果);其实是个softmax分类器
with tf.name_scope("output"):
W = tf.get_variable(
"W",
shape=[num_filters_total, num_classes],
initializer=tf.contrib.layers.xavier_initializer())
b = tf.Variable(tf.constant(0.1, shape=[num_classes]), name="b")
l2_loss += tf.nn.l2_loss(W)
l2_loss += tf.nn.l2_loss(b)
self.scores = tf.nn.xw_plus_b(self.h_drop, W, b, name="scores")
self.predictions = tf.argmax(self.scores, 1, name="predictions")- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
8 Loss function
得到了整个网络的输出之后,也就是得到了y_prediction,但还需要和真实的y label进行比较,以此来确定预测好坏
# 损失函数
# Calculate Mean cross-entropy loss 计算scores和input_y的交叉熵损失函数
with tf.name_scope("loss"):
losses = tf.nn.softmax_cross_entropy_with_logits(logits=self.scores, labels=self.input_y)
self.loss = tf.reduce_mean(losses) + l2_reg_lambda * l2_loss- 1
- 2
- 3
- 4
- 5
还是使用常规的cross_entropy作为loss function。最后一层是全连接层,为了防止过拟合,最后还要在loss func中加入l2正则项,即l2_loss。l2_reg_lambda来确定惩罚的力度
9 Accuracy
# Accuracy
# Accuracy计算准确度,预测和真实标签相同即为正确
with tf.name_scope("accuracy"):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")- 1
- 2
- 3
- 4
- 5
tf.equal(x, y)返回的是一个bool tensor,如果xy对应位置的值相等就是true,否则false。得到的tensor是[batch, 1]的.
tf.cast(x, dtype)将bool tensor转化成float类型的tensor,方便计算.
tf.reduce_mean()本身输入的就是一个float类型的vector(元素要么是0.0,要么是1.0),直接对这样的vector计算mean得到的就是accuracy.