冒泡排序、插入排序、选择排序、希尔排序、归并排序、快速排序、堆排序,这几种算法有时经常搞混或想不起什么原理,写个总结归纳吧,希望以后能越来越清楚。
下面排序均为升序
冒泡排序
每一轮,依次相邻元素比较交换, 将最大值放到i(i=0+1,0+2,…)位置后面
缺点: 重复交换,复杂度为
优点: 简单、稳定;空间复杂度为O(1)
注释: 稳定性是相等的元素在排序后相对位置不变,如5 8 5 2 9,经过排序后第一个5和第二个5的相对前后位置不会变,也就是第一个5不会跑到第二个5的后面
public static void bubbleSort(int[] data) {
int t;
for(int i=0;i<data.length-1;i++) { //控制比较次数
for(int j=0;j<data.length-1-i;j++) { //用来比较的元素
if(data[j]>data[j+1]) {
t = data[j];
data[j] = data[j+1];
data[j+1] = t;
}
}
}
}下面是改进后的冒泡排序,最佳时间复杂度为O(n)
public static void bubbleSort(int[] data) {
int t;
boolean didswap;
for(int i=0;i<data.length-1;i++) { //控制比较次数
didswap = false;
for(int j=0;j<data.length-1-i;j++) { //用来比较的元素
if(data[j]>data[j+1]) {
t = data[j];
data[j] = data[j+1];
data[j+1] = t;
didswap=true;
}
}
if(!didswap){
break; //若一趟下来没有交换的,则数组已有序
}
}
}选择排序
每一轮,选出最小元素选出与剩余元素的第一位交换
优点: 每轮只交换一次
缺点: 复杂度为
序列5 8 5 2 9,第一遍选择第1个元素5会和2交换,那么原序列中2个5的相对前后顺序就被破坏了,所以选择排序不是一个稳定的排序算法。
public static void selectionSort(int[] data) {
int minIndex;
int temp;
for(int i=0;i<data.length;i++) { // 剩余元素的第一位
minIndex = i;
for(int j=i+1;j<data.length;j++) {
if(data[minIndex]>data[j]) {
minIndex = j;
}
}
if(minIndex!=i) { //若找到的最小元素不是剩余第一位元素
temp=data[minIndex];
data[minIndex]=data[i];
data[i] = temp;
}
}
}插入排序
把无序区的第一个元素插入到有序区的合适的位置
这个稍微有一点点复杂,下面看步骤
1. 第一个元素默认为已经在有序区
2. 取出无序区的第一个元素e,这时空余出e的位置
3. 从后往前扫描有序区,若大于e,则往后挪;否则将e插入到空余位置
4. 形成新的有序和无序区
5. 重复2~4,直到无序区元素个数为零
优点:稳定;若元素越趋于有序,效率越高;最佳复杂度为O(n);空间复杂度为O(1);空间复杂度为O(1)
缺点:复杂度为
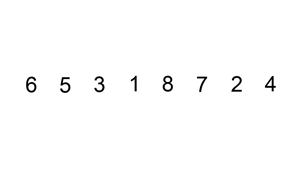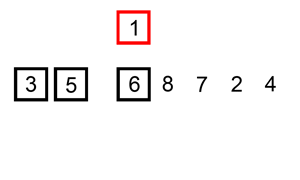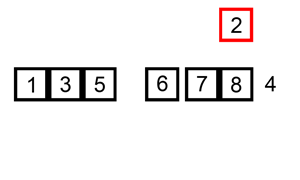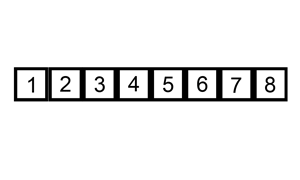
动图来源
public static void insertSort(int[] data) {
int temp;
for(int i=1;i<data.length;i++) {
temp = data[i]; // 取出无序区的第一位元素,空出位置i
int j=i-1; //有序区从后往前扫面
for(;j>=0 && data[j]>temp;j--) {
data[j+1] = data[j];
}
data[j+1]=temp; //出入空余位置
}
}希尔排序
其实质就是插入排序,它就是初始先取一个插入排序的步长,将数据按相隔的步长分成几组,并对么一组进行插入排序。这显然会多出了一个控制步长的循环,但它可以使序列快速趋向相对有序,使插入排序速度越来越快。到步长为1时,就是我们上一种的插入排序,此时数组已基本相对有序,所以速度会飞快。由粗至细检查元素,有点像做中国画由模糊到清晰,速度越来越快
例如有数组{13,14,94,33 ,82 ,25 ,59, 94, 65, 23, 45, 27, 73, 25, 39, 10},如果我们以步长为5开始进行排序,我们可以通过将这列表放在有5列的表中来更好地描述算法,这样他们就应该看起来是这样:
13 14 94 33 82
25 59 94 65 23
45 27 73 25 39
10然后我们对每列进行排序:
10 14 73 25 23
13 27 94 33 39
25 59 94 65 82
45将上述四行数字,依序接在一起时我们得到:[ 10 14 73 25 23 13 27 94 33 39 25 59 94 65 82 45 ].这时10已经移至正确位置了,然后再以3为步长进行排序:
10 14 73
25 23 13
27 94 33
39 25 59
94 65 82
45排序之后变为:
10 14 13
25 23 33
27 25 59
39 65 73
45 94 82
94这时在序列中,{10,25,27,39,45,94}等几组就是有序的
最后以1步长进行排序(此时就是简单的插入排序了)。到最后时,大致呈有序状态,有简单也就是我们这一个的插入算法排序时就可以让时间复杂度接近O(n)
public static void shellSort(int[] data) {
int temp;
int step = data.length;
do {
step = step/3==0 ? 1:step/3;
for(int i=step;i<data.length;i++) {
temp = data[i]; // 取出无序区的第一位元素,空出位置i
int j=i-step; //有序区从后往前扫面
for(;j>=0 && data[j]>temp;j-=step) {
data[j+step]=data[j];
}
data[j+step] = temp;
}
}while(step!=1);
}归并排序
合并的规则是,创建一个与空间大小为需要合并元素的总和,将分别从分别从头到位扫描两组元素,比较,将较小的组的元素一次放到所创建的空间中。先不断分,后不断合并
合并遵循一定规则,如:数组arr中有两组相邻元素{1,3,9} 和 {3,7,12},i,j分别为其首元素位置;temp时创建的空间,k为首元素位置其合并过程为
1. 比较arra[i]和arra[j], 若arra[i]小于等于则放入temp[k],反之则将arra[j]放入temp[k]中。小于等于只是为了算法的稳定
2. 若arra[i]放入temp[k],则需要i的下一个元素与arra[j]比较,故i+1
3. 若arra[j]放入temp[j],则需要j的下一个元素与arra[i]比较,故j+1
4. temp也跟着前进以为,k+1
5. 重复1~4直到有一组元素全部放入temp中,也就是temp
6. 再把剩余没有比较的元素直接由小到大的位置加到temp的末尾
7. 这时temp就是合并和的元素
大家可以试着合并。下面是我合并的过程
| 步骤 | 元素组1剩余 | 元素2剩余 | temp |
|---|---|---|---|
| 0 | 1,3,9 | 3,7,12 | |
| 1 | 3,9 | 3,7,12 | 1 |
| 2 | 9 | 3,7,12 | 1,3 |
| 3 | 9 | 7,12 | 1,3,3 |
| 4 | 12 | 1,3,3,7,9 | |
| 4 | 1,3,3,7,9,12 |
上面只是合并的思路,在具体实现中只有两个空间,分别都能放即将合并的全部元素即可
优点: 分而治之思想,速度快,平均和最差复杂度均为O(nlogn);稳定
缺点: 空间复杂度为O(n)
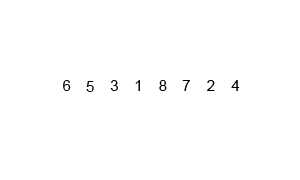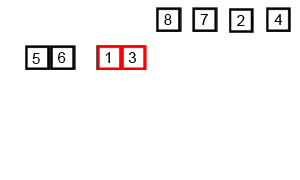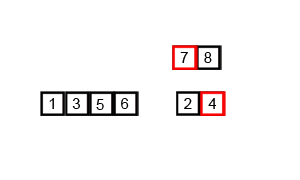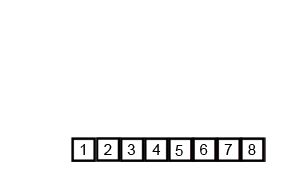
public static void mergeSort(int[] data) {
mergeSort(data,0,data.length/2,data.length-1);
}
public static void mergeSort(int[] data,int start,int mid,int end) {
if(start<end) {
//不断地分
mergeSort(data,start,(start+mid)/2,mid);
mergeSort(data,mid+1,(end+mid+1)/2,end);
//不断地合并
merge(data,start,mid,end);
}
}
public static void merge(int[] data,int start,int mid,int end) {
int[] temp = new int[data.length];
for(int i1=start;i1<=end;i1++) { //temp数组只存放要进行合并的数组
temp[i1]=data[i1];
}
int i,j,k;
i = start;
j = mid+1;
k=start;
while(i<=mid && j<=end) {
if(temp[i]<=temp[j]) {
data[k++] = temp[i++];
}else {
data[k++] = temp[j++];
}
}
//合并的数据重新放入data中
while(i<=mid) {
data[k++]=temp[i++];
}
while(j<=end) {
data[k++] = temp[j++];
}
}快速排序
优点: 分而治之,空间复杂度为O(1), 平均时间复杂度为O(nlogn)
缺点: 最坏时间复杂度O(
比如序列为 5 3 3 4 3 8 9 10 11,不能保证3的相对位置不变
过程:
1. 随机挑选一个元素作为基准元素,将所有比基准元素大的放在基准元素为后面,所有比它小的元素放在基准元素的左边;(可以考虑等于,但不影响排序结果)
2. 再对两边元素重复1步骤
其本质就是分而治之,基准元素归位
- 步骤1的算法最为重要,最常见也是最容易理解的一种方法就是: 将基准pivot与末尾元素调换位置,然后i指向首位置查找大于pivot的元素;
j从末尾的前一位开始遍历查找小于pivot的元素。两者都找到后则交换。
i前面的元素肯定大于或等于pivot, j前面的元素肯定小于等于pivot
public static int partition(int[] data,int start,int end) {
int pivot = data[(start+end)/2];
int i=start;
int j=end-1;
while(i<j) { //w1
while(data[i]<pivot && i<j) {i++;} //w2
while(data[j]>pivot && i<j) {j--;} //w3
System.out.println(i+" "+j);
swap(data,i,j);
}
if(data[i]<pivot) {
i++;
}
swap(data,i,end);
int pivotIndex =i;
return pivotIndex;
}因为i,j移动的步长都为1故此程序结束时,i==j;但data[i]是没有跟pivot比较过的,故需要做处理
堆排序
- 什么是堆?
堆通常是一个可以被看做一棵完全二叉树的数组对象。 - 是最大堆、最小堆?
最大堆,父节点的值大于等于子节点。
最小堆,父节点的值小于等于子节点。 - 如何维护某个节点子树的最大堆?
每次某个节点的值发生变化后,都要对其所在子树从上往下调整堆(序号小的到大的)。为什么是上往下?因为最大堆的某个节点换成较小值后只影响其子树的变化,故需要继续往下调整。的调整算法(非递归)是:
largest = parentIndex
while true
l = leftChildIndex
r= rightChildIndex
if l<heapSize and A[largest]<A[l]
largest = l
if r<heapSize and A[largest]<A[l]
largest = r
if largest != parentIndex
swap(A,largest,parentIndex)
parentIndex = largest
else
break为什么上面算法是r小于heapSize而不是小于数组长度? 因为堆的长度小于等于所用数组建立起来的堆。
- 如何建立堆?
从下往上即根节点递减调整每一个节点的堆,因为这才能保证下层的最堆的根节点小于其父节点。 - 堆排序算法
如输入数组A[0…n]
- 建立最大堆,最大的元素在根节点
- 根节点的值与A[n]互换位置,即剩余最大元素归位
- n–,将A[n]从堆中移出
- 调整堆为最大堆,重复2~3,直到堆的长度为1,此时的元素全部归位
下面是堆排序的递归实现
public static void heapSort(int[] data) {
buildMaxHeap(data);
int heapSize = data.length;
for(int i=data.length-1;i>=1;i--) {
swap(data,0,i);
heapSize--;
maxHeapify(data,0,heapSize);
}
}
public static void buildMaxHeap(int[] data) {
int heapSize = data.length;
for(int i=heapSize/2-1;i>=0;i--) {
maxHeapify(data,i,heapSize);
}
}
public static void maxHeapify(int[] data,int i,int heapSize) {
int l=2*i+1;
int r=l+1;
int largest = i;
if(l<heapSize && data[largest]<data[l]) {
largest = l;
}
if(r<heapSize && data[largest]<data[r]) {
largest = r;
}
if(i!=largest) {
swap(data,i,largest);
maxHeapify(data,largest,heapSize);
}
}总结
希尔排序是插入排序的优化
冒泡、选择、堆排序都是最值归位
归并、快速排序是分而治之的结果
参考资料
维基百科:冒泡排序 希尔排序 快速排序 堆排序
经典排序算法总结与实现
白话经典算法系列之六快速排序
堆排序和选择排序的比较
算法导论第六章—堆排序